Vibe Coding 实战指南
用 AI 加速开发,7 天从想法到上线
📖 关于本指南
这是一份基于真实项目(KnowFun 知识付费平台)的 Vibe Coding 实战手册。
🎯 本指南特点
- 100% 真实:所有数据、案例均来自真实行业洞察,拒绝虚构
- 实战导向:以 KnowFun 项目为载体,从 0 到 1 完整实现
- 方法论驱动:每章标注核心方法论,理解“为什么“而非死记硬背
- 极简主义:只讲做产品需要的 20% 知识,砍掉 90% 不必要的理论
- 完全免费:使用 Vercel + Supabase,部署成本 $0/月
💡 什么是 Vibe Coding?
Vibe Coding(氛围编程) = 用自然语言(人话)告诉 AI 你想要什么,AI 帮你生成代码。
你不需要:
- ❌ 背诵所有语法
- ❌ 手敲每一行代码
- ❌ 精通底层原理
你需要:
- ✅ 清楚地描述需求
- ✅ 审查 AI 生成的代码
- ✅ 调试和优化功能
- ✅ 把产品上线
🚀 快速开始
第一步:了解时代背景
核心洞察:
- 24.8% 的大学毕业生面临被 AI 替代的风险
- 埃森哲投入 8.65 亿美元培训员工用 AI
- 培训范式从“测-评-考-练-学“转向“问/练“
用时:15 分钟 收获:理解为什么要学 Vibe Coding
第二步:明确学习目标
核心能力:
- 独当一面:从需求到交付的完整链路
- 工作流驱动:拆解任务 → AI 赋能 → 测试优化
- 警惕低维度努力陷阱:做 1 个真实项目 > 10 个 TodoList
用时:20 分钟 收获:明确技能树和学习路径
第三步:配置开发环境
👉 Claude Code 如何使用 👉 Prompt 如何有效快速入门
用时:30 分钟 收获:可运行的 AI 编程环境
📚 完整目录
第一部分:方法论与心态(已完成 ✅)
建立正确的开发心态,理解 Vibe Coding 的底层逻辑。
交付物:正确的心态和学习方法
第二部分:工具入门(编写中 🚧)
掌握 Claude Code、Cursor 等 AI 编程工具的使用方法。
交付物:能用 AI 生成第一行代码
第三部分:网页开发基础知识(规划中 📋)
快速掌握前端、后端、运维的核心概念。
- 2.1 前端开发基础(Next.js + Tailwind CSS)
- 2.2 后端开发基础(FastAPI + PostgreSQL)
- 2.3 运维部署基础(Vercel + 域名配置)
交付物:理解网站如何运作
核心方法论:
不求精通,但求能跑
先用 AI 生成,再理解原理
复制粘贴 > 从零编写
第四部分:工具配置(规划中 📋)
学会部署、域名绑定、支付接入等生产环境配置。
- 3.1 Vercel 部署配置
- 3.2 域名购买与配置
- 3.3 支付插件接入(Stripe)
交付物:有域名的线上产品 + 可收费的支付系统
核心方法论:
安全 = 使用大厂组件(不要自己造轮子)
部署 = Git Push(自动化 CI/CD)
支付 = 跑通核心链路(购买→成功→增加积分)
第五部分:实战项目(规划中 📋)
完整实现 KnowFun 知识付费平台。
- 4.1 项目介绍:KnowFun 知识付费平台
- 4.2 从 0 到 1:完整开发流程
- 4.3 功能实现与代码讲解
交付物:可上线运营的完整产品
项目功能:
- 用户注册登录(Supabase Auth)
- 内容上传与展示
- 积分购买(Stripe 支付)
- AI 文档解析(Claude API)
- 内容广场与推荐
第六部分:问题与调试(规划中 📋)
常见问题速查表,遇到问题快速定位解决。
- 5.1 常见报错与解决方案
- 5.2 开发环境问题
- 5.3 部署上线问题
交付物:问题解决能力
第七部分:AI 资讯与扩展(规划中 📋)
持续更新的 AI 工具推荐和行业动态。
- 6.1 AI 工具推荐
- 6.2 行业动态与趋势
- 6.3 学习资源汇总
附录:工具箱(规划中 📋)
提示词模板、代码片段、术语表等速查资源。
- A1. Prompt 提示词模板库
- A2. 常用代码片段
- A3. 工具速查手册
- A4. 术语表
🎯 学习路径
路径 1:完整学习(推荐 7 天)
适合 0 基础学员,完整掌握 Vibe Coding 开发流程。
Day 1: 第一部分(方法论)
Day 2: 第二部分(工具入门)
Day 3: 第三部分(前端基础)
Day 4: 第三部分(后端基础)
Day 5: 第四部分(工具配置)
Day 6: 第五部分(实战项目)
Day 7: 第六部分(部署上线)
路径 2:快速上手(3-5 天)
适合有编程基础的学员。
Day 1: 第一部分 + 第二部分
Day 2: 第三部分(前后端)
Day 3: 第四部分 + 第五部分
Day 4-5: 优化和扩展
路径 3:模板改造(1-2 天)
适合快速验证想法的学员。
Day 1: 克隆项目模板 + 配置环境
Day 2: 修改为自己的产品 + 部署上线
💡 核心方法论
1. 工作流驱动 > 工具驱动
❌ 错误:学完所有 Prompt 技巧再开始做 ✅ 正确:在做项目的过程中,遇到问题就问 AI
2. 认知到位 = 彪悍执行
❌ 错误:看完教程 = 学会了 ✅ 正确:做出来 = 真正理解了
3. 独当一面 > 精通某个技术
❌ 错误:深入学习 React 的所有特性 ✅ 正确:能用 React + AI 做出能上线的产品
4. 真实项目 > 入门教程
❌ 错误:做 10 个 TodoList ✅ 正确:做 1 个真实的知识付费平台
📊 成本预估
开发成本
- Claude Code: 免费(有 API 配额)
- Claude API: 按使用付费(开发阶段成本低)
- 开发工具: 全部免费开源
部署成本(每月)
| 服务 | 用途 | 免费额度 | 预估成本 |
|---|---|---|---|
| Vercel | 前端托管 | 100GB 流量 | $0 |
| Supabase | 数据库+Auth | 500MB 数据库+1GB 存储 | $0 |
| Stripe | 支付 | 无限次 | 2.9%+$0.3/笔 |
总计: $0/月(不含支付手续费)
🛠 技术栈
为什么选择这套技术栈?
1. AI 最懂
- GitHub 上开源代码最多
- Claude 对这些技术的理解最深
- 生成的代码质量最高
2. 学习曲线平缓
- Next.js: React 框架,开箱即用
- FastAPI: Python 最快的 Web 框架
- Supabase: Firebase 开源替代,易用
3. 完全免费部署
- Vercel: 免费托管 Next.js
- Supabase: 免费数据库+Auth+Storage
- 总成本: $0/月
技术栈清单
前端: Next.js 14 + Tailwind CSS + shadcn/ui
后端: FastAPI + PostgreSQL + SQLAlchemy
部署: Vercel + Supabase
工具: Claude Code + MCP + Playwright
🎓 前置要求
- 一台电脑(Windows/Mac/Linux)
- 会打字和使用浏览器
- 每天 1-2 小时时间
- 愿意动手实践的心态
不需要:
- ❌ 编程基础
- ❌ 计算机专业背景
- ❌ 英语很好
📖 阅读建议
如何阅读本指南
- 不要跳章:每章都有依赖关系,建议按顺序学习
- 动手实践:看完一章立即实践,不要只看不做
- 记录问题:遇到问题先 Google/问 AI,解决不了再深入研究
- 复用代码:附录提供完整代码模板,优先复用
每章结构
章节标题
├── 方法论标注(核心思想)
├── 为什么要这样做?(原理)
├── 怎么做?(步骤)
├── 实战演练(基于 KnowFun)
├── 常见问题(FAQ)
└── 小结(交付物+下一步)
📄 许可证

本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。
您可以自由地:
- ✅ 分享 — 在任何媒介以任何形式复制、发行本作品
- ✅ 演绎 — 修改、转换或以本作品为基础进行创作
惟须遵守下列条件:
- 📝 署名 — 您必须给出适当的署名,提供指向本许可协议的链接,同时标明是否对原作品作了修改
- 💼 非商业性使用 — 您不得将本作品用于商业目的(包括但不限于:付费课程、商业培训、出版销售等)
- 🔄 相同方式共享 — 如果您对本作品进行了修改、转换或以其为基础创作,您必须以相同的许可协议分发您的作品
完整许可证
详细的许可证条款请参阅 LICENSE 文件或访问 Creative Commons 官网
🙏 致谢
本指南受以下项目启发:
- Claude Code - AI 编程工具
- Supabase - 开源后端服务
- Vercel - 前端部署平台
📌 版本信息
- 当前版本: v0.2.0
- 最后更新: 2025-11-21
- 维护状态: 🟢 活跃维护中
- 完成进度: 第一部分(方法论)✅ | 第二部分(工具)🚧 | 其他部分 📋
🚀 开始学习
准备好了吗?
记住:
不追求完美,只追求能跑通 不死记语法,只理解方法论 不重复造轮子,善用 AI 和开源
💬 反馈与建议
如果你在学习过程中遇到问题,或者有任何建议,欢迎:
- 📧 通过 Issue 反馈问题
- 💬 在社群中讨论交流
- ⭐ 给项目点个 Star 支持我们
让我们一起用 AI 加速开发,把想法变成现实!
时代背景:AI 时代如何加速学习
这篇文章是写给谁的?
👋 如果这些描述让你觉得似曾相识:
- 想做产品的人:你脑子里有无数好点子,但一想到要学 C++ 或 Java 就头大,最后不了了之。
- 传统的学习者:你买过不少编程课,也收藏了很多教程,但总是卡在“环境配置”或“Hello World”之后,不知道下一步该干嘛。
- 焦虑的职场人:你听说 AI 会写代码,担心自己被淘汰,或者反过来——你想利用 AI 让自己一个人活成一支队伍。
- 注重结果的实干家:你不在乎这段代码是不是最优雅的,你只在乎它能不能跑通,能不能上线,能不能被用户看到。
为什么我要写这个?
因为这也是我曾经走过的路。
就在两年前,如果遇到一个 Python 依赖包冲突的问题,我可能需要 Google 搜索一下午,打开十几个 Stack Overflow 的网页,尝试各种看不懂的命令,最后在挫败感中关掉电脑。
而现在,情况变了。
上周我遇到同样的问题,我把报错信息直接丢给 Claude,它在 30 秒内给了我解释和修复方案。不是我变聪明了,是工具变强了。
但这带来了一个新问题:当工具变得如此强大,我们还需要学什么?
什么是 Vibe Coding?
这可能是你今年听到的最有趣的词。
Vibe Coding(氛围编程) 并不是一种新的编程语言。简单来说,它是用自然语言(人话)与 AI 协作,将你的想法快速转化为产品的过程。
❌ 过去你需要掌握:
- JavaScript 的 20 种语法糖
- 复杂的内存管理机制
- 背诵几百个 API 接口
✅ 现在你只需要掌握:
- 清晰的表达能力:“我想做一个点击按钮后弹出窗口的功能,背景要半透明的黑色。”
- 鉴赏能力:AI 给出的界面好不好看?逻辑通不通?
- 缝合能力:怎么把 AI 写的前端和后端连起来?
听起来很玄?但这确实是 2025 年构建产品的最短路径。
真实的行业现状:焦虑与机遇共存
我们不谈那些吓人的假数据,只看正在发生的真实趋势。
1. 招聘逻辑变了
很多公司确实在缩减纯初级程序员的招聘。为什么?因为 AI 现在的水平,已经相当于一个不知疲倦、手速极快的初级程序员。 企业现在更想要的是“AI 驾驶员”——那些能指挥 AI 干活,一个人能顶原来三个人效率的员工。
2. 埃森哲们的选择
全球咨询巨头埃森哲(Accenture)虽然在裁员,但同时投入了数十亿美元培训现有员工使用 AI。这说明什么? 技能的迭代不是“替换”,而是“增强”。 未来的竞争,不是“人 vs AI”,而是“会用 AI 的人 vs 不会用 AI 的人”。
3. 门槛的倒置
以前,写代码是最难的,想创意相对容易。 现在,写代码变得极低门槛,“拥有好的创意”和“能把创意落地”的能力,变得无比昂贵。
真实案例:我的 PDF 乱码之战
让我们看一个真实的微小瞬间。
场景:我在做一个文档工具,用户上传 PDF 后,中文全是乱码。
🐢 以前的解法(痛苦模式):
- 去搜索引擎搜“Python PDF 中文乱码”。
- 看 5 篇技术博客,有的说装这个库,有的说改那个字体。
- 试错 3 次,环境搞坏了,重装环境。
- 耗时:2 小时 + 极度烦躁。
🚀 Vibe Coding 的解法(心流模式):
- 直接问 AI:“我用 PyPDF2 读中文 PDF 乱码,这是我的代码片段,怎么修?”
- AI 回复:“PyPDF2 对中文支持一般,建议换成 pdfplumber 库,或者尝试添加编码参数。这是修改后的代码…”
- 我复制粘贴,运行。
- 报错了?把报错信息再丢给 AI:“报了个错,说缺字体。”
- AI:“抱歉,你需要安装这个字体库,命令是…”
- 耗时:10 分钟 + 心情愉悦。
这就是加速。 我们把时间从“由于不知道语法而被卡住”,转移到了“解决实际问题”上。
但请注意:这不是魔法,这是新的技能树
我不希望你觉得买了这份指南就能躺着赚钱。AI 不是许愿池里的王八,它是一个极其强力但偶尔会犯傻的副驾驶。
1. 你必须学会“验证与调试”
AI 经常会一本正经地胡说八道(幻觉)。
- 它给的代码可能看起来很美,但跑不起来。
- 它可能引入安全漏洞(比如把密码明文存储)。
- 你的新核心技能:不再是写代码,而是Code Review(代码审查)。你要做那个把关的人,测试它,运行它,发现不对劲立刻反问。
2. 你的“注意力”是最稀缺的资源
AI 能够瞬间生成海量信息。如果你没有定力,很容易迷失在生成的代码海里。 你需要学会:寻找关键信息。在一堆代码中,哪一行才是解决问题的关键?
3. 心态建设:耐心是最大的捷径
很多新手用 AI 编程,遇到报错就慌了,觉得 AI 不行或者自己不行。 真相是:即使是资深工程师,每天也要面对几十个报错。
- 遇到报错 -> 复制报错 -> 问 AI -> 再试。
- 这个循环可能要重复 5 次。请保持耐心,这才是真正的“编程”。
为什么选择这份指南?我们提供什么?
市面上有无数的 AI 教程,为什么要看这一份?
因为大多数教程只教你怎么“生成代码”,而我们教你怎么**“交付产品”**。
我们不教屠龙术,我们带你从零造一把剑
在这个专栏/社群中,我们将通过 KnowFun 这个真实项目,带你走完以下全流程:
1. 环境与地基
- 不仅仅是 Cursor 的安装。
- 还有 Node.js 环境配置、Git 版本管理——这些是 AI 很难替你完全搞定,但你必须懂的基础。
2. 全栈开发流
- 从前端页面(React/Next.js)到后端逻辑。
- 我们会展示如何让 AI 处理 80% 的脏活累活,而你专注于 20% 的核心逻辑设计。
3. 真正的上线(Deploy)
- 代码写在本地只能自嗨。我们会教你:
- 如何使用 Vercel 一键托管前端。
- 如何购买服务器并配置(不再是黑箱操作)。
- 如何绑定自己的域名,让全世界都能访问你的作品。
- 这才是从“练习”到“产品”的质变。
4. 社群与支持
- 编程是孤独的,但 Vibe Coding 不需要。
- 我们建立了一个社群,当你遇到 AI 陷入死循环解决不了的 Bug 时,这里有真人在等你。我们分享 Prompt 技巧,也分享避坑指南。
小结:2025 年的学习清单
❌ 扔掉这些包袱:
- 死记硬背语法。
- 为了学编程而学编程。
- 完美主义(先跑通,再优化)。
✅ 拾起这些武器:
- 提问的艺术:把模糊的需求拆解成 AI 能听懂的具体指令。
- 调试的勇气:看到红色的报错不害怕,那是通往正确答案的路标。
- 发布的执念:代码在电脑里没价值,跑在服务器上、绑定了域名才有价值。
- 协作的心态:把 AI 当作你的结对编程伙伴,而不是你的奴隶。
准备好了吗?
下一篇,我们将正式介绍KnowFun项目,以及我们会用到的“神兵利器”。我们将不再纸上谈兵,而是开始动手。
记住:
在 AI 时代,技术不再是高墙,而是脚下的台阶。 只要你会提问,只要你有耐心,你就能构建任何东西。
关于我们:为什么要做这份指南
1. 现在的编程,感觉不一样了
📅 什么时候读这一节?
- 当你觉得“AI很厉害,但我不知道从哪开始“的时候。
- 当你听说过 Vibe Coding(氛围编程),但不确定这到底是个梗,还是个正经技能的时候。
💡 核心理念:你的角色变了
你可能已经感觉到了,2025年的编程,不再是单纯的比拼打字速度或背诵语法。
Vibe Coding 的本质是:你用自然语言(人话)描述意图,AI 负责实现逻辑。
但这并不意味着你可以“躺平”。相反,这要求你从一个“搬砖工”变成一个“工头”甚至“产品经理”。
🔍 现实情况
以前的流程:
- 想功能
- 查文档
- 写代码(耗时 80%)
- 改 Bug
Vibe Coding 的流程:
- 想清楚(这是最难的,耗时 40%)
- 准确提问(Prompt 工程)
- 审查代码(AI 写得对不对?)
- 验证与调试(跑起来再说)
2. 我们是谁?为什么要做这件事?
👋 Does this sound like you?(这听起来像你吗?)
- 你有很多好点子,但卡在“我不会写代码”这一步。
- 你试过 ChatGPT 或 Cursor,但生成的代码一运行就报错,你不知道怎么改。
- 你被网上海量的教程淹没了,不知道哪个才是当下有用的。
🚀 我们是谁:你的“陪跑者”
我不是无所不知的大师。我也遇到过环境配置报错一整天的时候,也经历过对着 AI 喊“你听不懂人话吗”的崩溃时刻。
- 我毕业于中科大(USTC),做过算法,搞过全栈。
- 但在这个项目中,我的身份是一个先行者和过滤器。
🛡️ 我们提供什么服务?
1. 注意力保护与信息筛选 在这个时代,注意力是你最宝贵的资源。 网上有 100 种学 Python 的方法,有 1000 个新出的 AI 工具。
- 我的工作:帮你试错。我试过 10 个工具,告诉你哪 1 个最适合新手,帮你节省 90% 的时间。
- 你的收益:不用在选择工具上浪费时间,直接开始创造。
2. “避免重复造轮子”的知识库
- 遇到中文乱码怎么办?
- Vercel 部署失败怎么查日志?
- 域名解析怎么配置? 这些问题如果你自己查,可能要花一下午。我们把这些高频踩坑点整理成了清单,你遇到了,查一下,5分钟解决。
3. 真实的项目实战 我们不做TodoList这种玩具。我们带你做一个真实上线的产品——KnowFun(一个知识付费平台)。 从写第一行代码,到购买域名,再到配置服务器,每一步都真实可见。
3. 一人开发者需要掌握什么?(不只是代码)
🎯 核心技能树
✅ Skill 1:精准的表达(Prompting)
这不仅是跟 AI 说话,更是理清你自己的思路。
- Bad Vibe: “帮我做一个网站。”
- Good Vibe: “我要做一个基于 Next.js 的着陆页,包含一个 Hero Section 和 价格表,配色参考 Vercel 风格。”
✅ Skill 2:验证与调试(Verification)
AI 会犯错(幻觉)。你必须是那个把关的人。
- 学会看浏览器控制台(Console)的红字。
- 学会把错误信息复制给 AI,让它自我修正。
- 心态建设:报错是正常的,每一次报错都是 AI 在教你理解系统运作的原理。
✅ Skill 3:部署与发布(Deployment)
代码躺在硬盘里是没有价值的。你需要让世界看到它。 我们会手把手教你:
- 购买域名:怎么选?去哪买(Namecheap/GoDaddy/阿里云)?
- Vercel 部署:前端代码的一键上线。
- 服务器配置:什么时候需要买云服务器?怎么用 SSH 连上去?
4. 我们的承诺与你的承诺
🤝 这是一个双向奔赴的过程
我们承诺:
- 不说黑话:尽量用大白话解释技术术语。
- 不藏私:分享真实的 Prompt 模板和调试记录。
- 社群支持:一个人走得快,一群人走得远。在这里找到你的代码搭子。
你需要承诺:
- 耐心:虽然 AI 加速了开发,但理解一个复杂的系统依然需要时间。不要指望 10 分钟就能学会所有。
- 动手:只看教程是学不会游泳的。你必须把手弄脏(Get your hands dirty),亲自去改代码,亲自去修 Bug。
- 心态:当遇到问题时,深呼吸。这不是你笨,这是必经之路。
🌟 为什么现在开始?
技术在变,工具在变,但创造价值的能力永远稀缺。 如果你能利用 AI 快速构建产品,验证想法,你就拥有了在这个时代最大的杠杆。
准备好开始这一场 Vibe Coding 之旅了吗?
一人开发者需要学什么
👋 我们是谁?我们能为您做什么?
在开始之前,先简单介绍一下我们。从0到一完整的实践vibe coding 不仅仅是一个教程库,我们是您的独立开发陪跑教练。
我们提供的服务核心只有一点:帮助您从“写代码的人”转变为“做产品的人”。
- 我们将协助您:搭建从 0 到 1 的完整技术栈(Next.js + AI)。
- 我们将教会您:如何像指挥团队一样指挥 AI,而不是被 AI 带着跑。
- 我们将提供:经过实战验证的“脚手架”代码,让您跳过繁琐的配置,直接开发核心功能。
🎯 这听起来像你吗?(Does this sound like you?)
- 🤯 收藏夹焦虑:躺着 50 个“必学教程”,但每次打开 IDE(代码编辑器)就感到一阵窒息。
- ⏳ 虚假忙碌:每天坐在电脑前 8 小时,感觉很忙,但睡前一想,产品好像没什么实质进展。
- 🐛 报错恐慌:遇到一个报错能卡一整天,修好后既没成就感,也不知道下次怎么避免。
如果这些场景让你觉得似曾相识,请深呼吸。不是你不够聪明,而是没人告诉过你,独立开发的游戏规则变了。
在这个 AI 时代,你不再需要成为一本行走的百科全书。你需要成为一名精明的资源管理者。
🧠 核心思维:你的注意力 > 你的代码量
作为独立开发者,你最稀缺的资源不是服务器性能,也不是金钱,而是你的注意力。
1. 告别“从头学起” (Just-in-Time Learning)
传统的学校教育告诉我们要“先学会,再动手”。但在独立开发中,这是最大的陷阱。
- ❌ 以前的做法:买一本《React 从入门到精通》,试图背下来所有语法,结果学到第三章就放弃了。
- ✅ 现在的高效做法:
- 明确目标:“我想做一个登录按钮”。
- 询问 AI:“怎么用 Next.js 写一个登录按钮?”
- 复制运行:看懂 60%,能跑通就行。
- 存档:记住了,下次做按钮时,去哪里找这段代码。
💡 关键点:你不需要知道发动机的所有原理,你只需要知道怎么踩油门,以及车坏了该打谁的电话。
2. 像训练员工一样训练 AI
工具本身没有价值,你会用工具的方式才是价值所在。不要把 AI 仅仅当成搜索引擎,要把它当成你招的一个非常勤快但偶尔会犯傻的实习生。
最佳实践 (Best Practices):
- 给背景 (Context):“我正在做一个极简风格的记账 App,用户主要是大学生,不要用太商务的词汇。”
- 给约束 (Constraints):“请用 Tailwind CSS,不要引入额外的组件库,保持代码在 100 行以内。”
- 给反馈 (Feedback):“你写的这个布局在手机上错位了,请调整一下,要保证移动端优先。”
⚠️ 警惕:如果你发现 AI 总是答非所问,通常不是 AI 变笨了,而是你的指令(Prompt)太模糊。花时间打磨你的提问技巧,这比背 API 划算得多。
🛠️ 技能清单:从“苦力”转向“借力”
🛡️ 避免重复造轮子 (The DRY Rule)
这是新手最容易浪费时间的地方。 遇到一个通用功能(如:登录、支付、深色模式),请先停下来问自己:“这个问题,世界上是不是已经有人解决过了?”
- 善用模板 (Boilerplates):我们会为您提供现成的启动模板。直接拿来用,不要有洁癖。
- 建立自己的代码库:第一次解决“图片上传”花了 3 小时。解决完后,把这段代码存到你的笔记里。下次,它只需要 3 分钟。
🔍 像侦探一样寻找关键信息
当程序报错时(相信我,它一定会报错),不要慌。
- 阅读案发现场:看一眼报错红字,通常关键信息就在
Error:后面那一行。 - 精准搜索:复制报错信息 + 你的技术栈名字(例如
"Next.js 500 error api routes")。 - 求助社区:如果 AI 搞不定,GitHub Issues 和 Stack Overflow 是你的宝库。
❤️ 心态建设:这是一场马拉松
🧘♀️ 耐心是究极技能
即使有了 AI,你也不可能在一天内建成罗马。
- 你会被环境配置卡住。
- 你会因为一个简单的 CSS 样式调一晚上。
- 这都是过程的一部分。 接受这种“笨拙感”。只要你在解决问题,你就在前进。
🤝 寻找你的部落 (Community Support)
一个人写代码是非常孤独的。
- 加入社群:不管是 Discord 还是微信群,找到和你做同样事情的人。
- 寻求支持:当你卡住时,吼一声。往往别人的一句话就能点醒你。
- 分享成果:即使只做出来一个小功能,也发出来。别人的点赞是最好的燃料。
🚀 实战行动路线图:从零到上线
不要试图一口吃成胖子,我们把大目标拆解为可执行的工作流。
第 1 阶段:环境搭建与验证 (Setup & Verify)
- 目标:让代码在你的电脑上跑起来,哪怕只是显示一行 “Hello World”。
- 我们的服务:我们提供配置好的环境脚本,帮你跳过最头疼的依赖安装环节。
- How-to:
- 安装 Node.js 和 Git(不用懂原理,装上就行)。
- 拉取代码,运行
npm install。 - 看到浏览器出现画面,胜利✌️。
第 2 阶段:功能积木搭建 (Building)
- 目标:利用 AI 和开源组件,拼凑出核心功能。
- 重点:先求有,再求好。不要为了“按钮圆角是 4px 还是 6px”纠结半小时。
- 验证与调试:
- 每写完一个小功能(比如登录),立刻测试。
- 如果报错,复制错误信息给 AI,让它帮你修。
第 3 阶段:上线与部署 (Deploy & Ship)
这是最激动人心的一步。如果你的产品只能在你自己的电脑上跑,那它就没有价值。
1. 代码托管 (GitHub)
- 把你的代码存到云端,这是你的资产保险柜。
2. 前端部署 (Vercel) —— 强烈推荐
- 为什么选它:对于 Next.js 项目,Vercel 是官方推荐的,对个人开发者免费且极度好用。
- 操作:
- 注册 Vercel 账号。
- 点击 “Import Project”,导入你的 GitHub 仓库。
- 点击 “Deploy”。
- 等待 1 分钟,你会得到一个
https://your-project.vercel.app的链接。全世界都能访问了!
3. 绑定域名 (Domain)
- 为什么要买:
vercel.app的后缀看起来像个玩具。你需要一个.com或.io来展示专业性。 - How-to:在 Namecheap 或阿里云购买域名,然后在 Vercel 的后台设置里进行 DNS 解析绑定(我们会提供详细截图教程)。
4. 服务器与后端 (Server/VPS) —— 进阶选项
- 如果你的业务非常复杂(需要处理视频、大量数据计算),可能需要购买云服务器(如 AWS, DigitalOcean, 阿里云)。
- 但是:对于 90% 的独立开发产品,Vercel + Serverless 数据库(如 Supabase)已经足够,且成本几乎为 0。
📝 写在最后
这篇指南里没有一行代码,因为代码是最容易获取的资源。
作为一人开发者,你真正的护城河是:
- 对痛点的敏锐度(知道做什么)。
- 解决问题的韧性(知道怎么坚持做完)。
- 利用工具的效率(知道怎么不加班也能做完)。
我们在这里,就是为了帮你守住这道护城河。准备好开始了吗?🚀
Claude Code:住在你终端里的“首席架构师“
Vibe 语录: 告别在 ChatGPT 和 VS Code 之间疯狂
Ctrl+C/V的日子。让 AI 直接接管键盘,你只需要负责喝咖啡和把关。
欢迎来到 Claude Code 的世界!如果你之前只用过网页版的 AI 聊天(ChatGPT、Claude、豆包),那你可能还停留在“复制粘贴时代“。
这就好比你之前只能通过微信和一个超级聪明的远方朋友聊天,他给你建议,你自己动手改代码。现在,这个朋友直接搬进你家了,你只需要说“帮我把厨房收拾一下“,他就直接动手干活。
一、为什么要用 Claude Code?(它不是插件,是室友)
痛点场景:复制粘贴地狱
你是不是经常这样:
- 在网页版 ChatGPT/Claude 上问问题
- AI 给你一段代码
- 复制 -> 粘贴到 VS Code
- 运行 -> 报错
- 把报错信息复制回网页
- AI 道歉:“抱歉,我刚才漏了一个分号…”
- 再复制 -> 再粘贴…
累吗?
Claude Code 的超能力
| 网页版 AI | Claude Code |
|---|---|
| 只能看你发的代码片段 | 直接读取整个项目 |
| 给你建议,你自己改 | 直接帮你改文件 |
| 出错了你还得复制报错 | 直接跑测试、自动修 Bug |
| 像“网友“ | 像“住在你电脑里的室友“ |
一句话定位:
- Copilot 是帮你补全代码的打字员
- Claude Code 是坐在你旁边帮你写代码的资深架构师
二、快速召唤:三步让 AI 入职
Step 1:安装(一行命令搞定)
打开终端(Mac 按 Cmd+Space 搜索 “Terminal”,Windows 搜索 “PowerShell”),输入:
npm install -g @anthropic-ai/claude-code
小白提示: 如果报错说找不到
npm,说明你还没装 Node.js。 去 nodejs.org 下载安装即可,选 LTS 版本。
Step 2:认证(刷脸进门)
安装完成后,输入:
claude
系统会自动打开浏览器,让你登录 Anthropic 账号。授权成功后,终端会显示欢迎信息。
费用提醒: Claude Code 使用的是 Anthropic API,会产生费用。 但别怕!日常使用一个月大概几十块钱。比雇一个程序员便宜多了吧?
Step 3:进入项目(开始工作)
cd 到你的项目文件夹,再输入 claude:
cd ~/my-awesome-project
claude
Claude 会自动扫描你的代码,建立对项目的认知。这就像新员工入职第一天先熟悉环境。
三、基础指令:像老板一样发号施令
进入 Claude Code 后,你会看到一个交互界面。直接用自然语言说话就行!
3.1 日常问答
> 解释一下 src/utils.py 是干嘛的
Claude 会读取文件内容,给你详细解释。
> 这个项目的目录结构是什么?
它会给你画一个清晰的树状图。
3.2 改代码(最爽的功能)
> 把登录按钮改成圆角,颜色用 #3B82F6
Claude 会直接找到对应的 CSS 文件并修改。修改前会问你确认。
> 在 User 模型里加一个 phone 字段
它不仅改 Model,还会问你要不要顺便改数据库迁移文件。懂事!
3.3 修 Bug(神功能)
> 运行测试,如果报错就修好它
Claude 会:
- 执行测试命令
- 分析报错信息
- 定位问题代码
- 自动修复
- 再跑测试验证
你只需要说一句话,它干完全部活。
3.4 常用命令速查
| 你说 | Claude 做 |
|---|---|
| “解释这段代码” | 读取并解释 |
| “这里为什么报错” | 分析错误原因 |
| “帮我写个函数做 XXX” | 生成代码并插入 |
| “重构这个文件” | 优化代码结构 |
| “写测试” | 生成单元测试 |
| “提交代码” | 执行 git add/commit |
四、进阶心法:让 AI 更懂你
4.1 CLAUDE.md —— 立下“家规“ (超重要!)
这是 Claude Code 最强大的功能之一,但很多人不知道。
痛点场景:
- 每次开新对话,都要告诉 AI:“我用的是 TypeScript”、“缩进用 2 个空格”、“测试用 Jest”…
- AI 经常自作主张用你不喜欢的库
解决方案: 在项目根目录创建 CLAUDE.md 文件
# 项目规范
## 技术栈
- 前端:React 18 + TypeScript
- 样式:Tailwind CSS
- 状态管理:Zustand
- 测试:Vitest
## 代码风格
- 缩进:2 个空格
- 字符串:使用单引号
- 组件:函数式组件 + Hooks
- 禁止使用 any 类型
## 常用命令
- 启动项目:npm run dev
- 运行测试:npm test
- 构建:npm run build
## 目录结构
- src/components/ - React 组件
- src/hooks/ - 自定义 Hooks
- src/utils/ - 工具函数
- src/api/ - API 请求
## 注意事项
- 所有 API 请求通过 src/api/client.ts 发送
- 新组件必须写单元测试
- 提交前必须通过 ESLint 检查
效果对比:
| 没有 CLAUDE.md | 有 CLAUDE.md |
|---|---|
| “你用 Python 还是 JS?” | 直接知道用 TypeScript |
写出 var 声明 | 自动用 const |
| 乱用第三方库 | 只用你指定的库 |
| 每次都要重复说明 | 一劳永逸 |
比喻: CLAUDE.md 就是公司的员工手册。 新员工入职先背熟规矩,就不会问一些低级问题了。
4.2 Plan Mode —— 先画图,再动工
危险场景: 你说“帮我重构整个用户系统“,AI 二话不说就开始改代码,改着改着项目跑不起来了…
解决方案: 使用 Plan Mode
> /plan 重构用户认证系统,支持 OAuth 登录
或者直接在请求后加上“先给我一个计划“:
> 重构用户认证系统。在动手之前,先给我一个详细的实施计划,我确认后你再开始。
Claude 会输出类似这样的计划:
## 重构计划
### 阶段 1:准备工作
1. 备份现有 auth 模块
2. 分析当前认证流程
### 阶段 2:OAuth 集成
1. 安装 passport.js
2. 创建 OAuth 配置文件
3. 实现 Google 登录
4. 实现 GitHub 登录
### 阶段 3:数据库更新
1. 修改 User 模型,添加 provider 字段
2. 创建迁移脚本
### 阶段 4:前端对接
1. 添加社交登录按钮
2. 处理 OAuth 回调
是否开始执行?
你确认后,它才开始一步步实施。
黄金法则: 涉及超过 3 个文件的修改,必须用 Plan Mode! 否则就像让一个热情的实习生单独负责公司年会,结果可能是灾难。
4.3 思考预算 —— 给大脑充值
Claude Code 有一个隐藏功能:你可以控制它“想多久“。
想象 AI 的大脑是一台咖啡机:
| 档位 | 关键词 | 适用场景 | 费用 |
|---|---|---|---|
| 清水 | think | 简单问答、小改动 | 便宜 |
| 拿铁 | think hard | 复杂 Bug、算法设计 | 适中 |
| 双倍浓缩 | think harder | 架构重构、性能优化 | 较贵 |
| 静脉注射 | ultrathink | 疑难杂症、祖传代码 | 土豪专属 |
使用方式: 在请求中加入关键词
> think hard 这个递归函数为什么会栈溢出?
> ultrathink 帮我分析这个遗留系统的架构问题,给出重构建议
省钱建议: 日常改 Bug 用默认档就够了。 只有遇到真正复杂的问题才需要“加咖啡“。
五、高级玩法:连接外部世界
5.1 MCP —— 给 AI 装外挂
MCP (Model Context Protocol) 让 Claude Code 能连接外部工具。
比喻: 本来你的室友只会写代码,装上 MCP 后,他还能:
- 帮你查 GitHub Issue
- 读取数据库数据
- 发飞书/钉钉消息
- 控制浏览器
- 查 Google 搜索结果
常用 MCP 工具:
# 安装 Playwright MCP(浏览器控制)
claude mcp add playwright
# 安装 GitHub MCP(查 Issue、PR)
claude mcp add github
# 安装 Notion MCP(读写 Notion 文档)
claude mcp add notion
装上后,你可以说:
> 帮我检查 GitHub 上有没有关于登录问题的 Issue
> 用浏览器测试一下登录页面能不能正常工作
5.2 省钱大法:切换模型
觉得 Claude 太贵?可以换成便宜的模型!
方式 1:使用 DeepSeek(国产平替)
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_AUTH_TOKEN="你的DeepSeek密钥"
export ANTHROPIC_MODEL="deepseek-chat"
适合场景: 写注释、生成文档、简单问答
方式 2:使用 AWS Bedrock / Google Vertex AI
如果你公司已经有云服务账号,可以走企业账单,更便宜。
详细配置参考 官方文档
5.3 多代理协作:让 AI 互相 Code Review
高端玩法: 用两个 Claude 实例,一个写代码,一个审代码。
# 终端 1:写代码的 Claude
cd ~/project
claude
# 终端 2:Review 的 Claude
cd ~/project
claude
在终端 2 里说:
> 审查一下 src/auth/login.ts 的代码,指出潜在问题
为什么这样做? 写代码的 AI 可能有“盲点“,另一个有“fresh eyes“的 AI 更容易发现问题。 就像人类开发者互相 Code Review 一样。
六、避坑指南(血泪经验)
1. 不要盲目按 y!
当 Claude 问你“是否执行这个命令?“时,一定要看清楚!
特别是看到这些关键词时要小心:
rm(删除)drop(删库)force(强制操作)-rf(递归删除)
惨痛教训: 有人让 AI 清理临时文件,结果 AI 把整个项目删了…
2. Token 爆炸警告
经常用这个命令查账:
> /cost
省 Token 技巧:
- 不要把整个
node_modules喂给它 - 用
.gitignore风格的.claudeignore排除大文件 - 聊太久了就开新对话(老对话上下文太长)
3. Git 是后悔药
在让 Claude 大改之前,务必先提交当前代码:
git add .
git commit -m "保存点:让 AI 改之前"
这样即使 AI 改崩了,你还能回滚:
git checkout .
4. 复杂任务要拆解
错误示范:
> 帮我做一个完整的电商网站,包括用户系统、商品管理、购物车、支付、订单管理
正确做法:
> 先帮我做用户注册登录功能
(完成后)
> 现在加上商品列表页
AI 和人一样,一次只能专注一件事。
5. 敏感信息别暴露
不要问:
> 帮我把数据库密码改成 abc123456
应该问:
> 帮我设置数据库密码,从环境变量读取
Claude 会生成使用 process.env.DB_PASSWORD 的代码,不会把真实密码写死。
七、常见问题 FAQ
Q:Claude Code 和 VS Code 里的 Copilot 有什么区别?
| Copilot | Claude Code |
|---|---|
| 补全当前行代码 | 理解整个项目 |
| 只能建议 | 能直接改文件 |
| 被动触发 | 主动对话 |
| 像自动补全 | 像 pair programming |
建议: 两个一起用。Copilot 写代码时补全,Claude Code 做重构和修 Bug。
Q:会不会把我的代码泄露给 Anthropic?
Claude Code 会发送代码到 Anthropic 的 API 进行处理,但 Anthropic 承诺不会用用户数据训练模型。 如果你在做机密项目,可以:
- 使用自托管方案
- 配置本地模型(通过 Ollama)
- 只在非敏感代码上使用
Q:一个月大概花多少钱?
取决于使用频率:
- 轻度使用(每天问几个问题):¥30-50/月
- 中度使用(日常开发):¥100-200/月
- 重度使用(整天让它写代码):¥300+/月
省钱技巧: 用 DeepSeek 做简单任务,Claude 只用来啃硬骨头。
八、Vibe Coding 总结
你的角色:产品经理 + 技术总监
Claude Code 的角色:执行团队
你负责:把控方向、定义需求、审核结果
它负责:读代码、写代码、跑测试、修 Bug
心态转变:
- 以前: 我要写代码
- 现在: 我要告诉 AI 写什么代码
行动上:
- 写好
CLAUDE.md,立下家规 - 复杂任务用 Plan Mode,先思考再动手
- 遇到难题调高“咖啡浓度“(think harder)
- 改代码前先
git commit,留好后悔药
九、你的第一次 Vibe Coding
现在,打开终端,输入:
cd ~/你的项目文件夹
claude
然后对它说:
> 阅读整个项目,给我一个简单的项目概述,包括使用的技术栈和主要功能模块
或者更 Vibe 一点:
> 嘿,新来的!先熟悉一下环境,告诉我这个项目是干嘛的
享受这一刻的 Vibe 吧!你的“首席架构师“已经就位。
十、省钱神器:Kimi K2 API 配置(小白保姆级)
觉得 Claude 官方 API 太贵?Kimi K2 是你的省钱神器!
为什么选 Kimi K2?
| 对比项 | Claude Opus | Kimi K2 |
|---|---|---|
| 输入价格 | ~$15/M tokens | $0.6/M tokens |
| 输出价格 | ~$75/M tokens | $2.5/M tokens |
| 性价比 | 贵 | 便宜 10 倍以上 |
| 编码能力 | 顶级 | 接近顶级(开源最强之一) |
| 上下文 | 200K | 256K |
| 网络要求 | 需要科学上网 | 国内直连 |
| 支付方式 | 美元 | 人民币 |
简单说: 用 Kimi K2 跑 Claude Code,一个月可能只花几块钱!
Step 1:获取 Kimi API Key
- 访问 Moonshot AI 平台
- 注册账号(用手机号或邮箱)
- 进入控制台 → API Keys → 创建新密钥
- 复制你的密钥(格式:
sk-xxxxxxxxxxxxxxxx)
注意: 建议充值 ¥50 以上,否则有请求频率限制。
Step 2:配置 Claude Code(四种方式任选)
方式 A:一行命令搞定(最简单,推荐小白)
npx kimicc
第一次运行会让你输入 API Key,输入后自动配置完成!
方式 B:环境变量配置(临时)
Mac/Linux 用户:
export ANTHROPIC_AUTH_TOKEN="sk-你的密钥"
export ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
claude
Windows CMD 用户:
set ANTHROPIC_AUTH_TOKEN=sk-你的密钥
set ANTHROPIC_BASE_URL=https://api.moonshot.cn/anthropic
claude
Windows PowerShell 用户:
$env:ANTHROPIC_AUTH_TOKEN="sk-你的密钥"
$env:ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
claude
注意: 这种方式每次新开终端都要重新设置。
方式 C:永久配置(一劳永逸,推荐)
Mac/Linux - 编辑 shell 配置文件:
# 打开配置文件(用 nano 或 vim)
nano ~/.zshrc # 如果用 zsh
# 或
nano ~/.bashrc # 如果用 bash
# 在文件末尾添加这两行:
export ANTHROPIC_AUTH_TOKEN="sk-你的密钥"
export ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
# 保存后执行,让配置生效:
source ~/.zshrc
Windows - 设置系统环境变量:
- 右键「此电脑」→「属性」→「高级系统设置」→「环境变量」
- 在「用户变量」中点击「新建」:
- 变量名:
ANTHROPIC_AUTH_TOKEN - 变量值:
sk-你的密钥
- 变量名:
- 再新建一个:
- 变量名:
ANTHROPIC_BASE_URL - 变量值:
https://api.moonshot.cn/anthropic
- 变量名:
- 点击「确定」保存
- 重启终端才能生效
方式 D:配置文件方式(Claude Code 1.0.61+)
编辑 ~/.claude/settings.json 文件:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "sk-你的密钥",
"ANTHROPIC_BASE_URL": "https://api.moonshot.cn/anthropic",
"ANTHROPIC_MODEL": "kimi-k2-0711-preview",
"ANTHROPIC_SMALL_FAST_MODEL": "kimi-k2-0711-preview"
}
}
配置文件位置:
- Windows:
C:\Users\你的用户名\.claude\settings.json - Mac/Linux:
~/.claude/settings.json
提示: 如果文件或目录不存在,直接创建即可。
Step 3:验证配置成功
启动 Claude Code:
claude
输入测试:
> 你好,你是什么模型?
如果回复提到 “Kimi” 或 “Moonshot”,说明配置成功!
快速启动脚本(懒人福音)
Windows 用户 - 创建 start_claude_kimi.bat:
@echo off
set ANTHROPIC_AUTH_TOKEN=sk-你的密钥
set ANTHROPIC_BASE_URL=https://api.moonshot.cn/anthropic
claude
双击这个文件就能启动!
Mac/Linux 用户 - 创建 start_claude_kimi.sh:
#!/bin/bash
export ANTHROPIC_AUTH_TOKEN="sk-你的密钥"
export ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
claude
使用方法:
chmod +x start_claude_kimi.sh # 给执行权限(只需一次)
./start_claude_kimi.sh # 启动
常见问题排查
Q:配置后还是用的 Claude?
检查环境变量是否生效:
# Mac/Linux
echo $ANTHROPIC_BASE_URL
# Windows CMD
echo %ANTHROPIC_BASE_URL%
# Windows PowerShell
echo $env:ANTHROPIC_BASE_URL
应该显示 https://api.moonshot.cn/anthropic
Q:报错 ANTHROPIC_API_KEY not found?
- 检查变量名是
ANTHROPIC_AUTH_TOKEN不是ANTHROPIC_API_KEY - Windows 用户:重启终端
- Mac/Linux 用户:执行
source ~/.zshrc
Q:报错 “rate limit”?
Kimi 对免费用户有限制,建议充值 ¥50 以上解锁更高频率。
Q:Kimi K2 有什么限制?
- 不支持图片(无法读取截图)
- 部分复杂推理可能不如 Claude Opus
- 适合日常编码、写文档、改 Bug
Q:API 调用失败?
检查清单:
- ✅ API Key 是否正确(没有多余空格)
- ✅ Base URL 末尾不要多加
/ - ✅ 网络能否访问
api.moonshot.cn - ✅ API Key 账户是否有余额
什么时候用 Kimi,什么时候用 Claude?
| 场景 | 推荐 |
|---|---|
| 日常改 Bug、写代码 | Kimi K2(省钱) |
| 写注释、生成文档 | Kimi K2(省钱) |
| 复杂架构设计 | Claude(更准) |
| 需要读图片 | Claude(Kimi 不支持) |
| 疑难杂症 | Claude + ultrathink |
Vibe 建议: 平时用 Kimi 省钱,遇到硬骨头再切回 Claude。两个都配置好,随时切换!
下一步推荐阅读:
Prompt 如何有效快速入门:小白保姆级教程
欢迎来到 Prompt(提示词)的世界。别被这个英文单词吓到了,简单来说,它就是你对 AI 说的话。
很多小白刚开始用 AI(比如 ChatGPT、Claude、文心一言、豆包),觉得它“笨”、“听不懂人话”或者“只会讲车轱辘话”。其实,大概率不是 AI 笨,而是我们的指令(Prompt) 给得不够好。
这就好比你带了一个博学多才、反应极快,但是没有任何职场经验、也没什么眼力见的“直男实习生”。
- 你说“随便买点喝的”,他可能给你买瓶酱油。
- 你说“去买杯冰美式,半糖,不要盖子,送到 302 会议室”,他就能完美执行。
本教程将手把手教你,如何把这个“实习生”调教成你的“金牌助理”。特别是你会学到如何用结构化的方式(Markdown) 来清晰表达你的需求,这是从小白进阶到高手的关键。
一、 哪些用的场景? (Usage Scenarios)
不要觉得 AI 只有程序员才用。根据我们整理的实战案例(来自豆包、飞书等工具的真实用法),只要你需要处理文字、寻找灵感、分析数据甚至做设计,它都能帮你。
以下是基于真实案例整理的 6 大核心场景,直接拿去用:
1. 职场救急:从“卑微打工”到“效率狂魔”
你是不是经常对着空白文档发呆?或者被合同条款绕晕?
- 场景 A:写邮件/周报/日报
- 小白 Prompt:
帮我写个日报。(❌ 太空洞) - 高手 Prompt:
我是一名新媒体运营。请把以下 3 条零散的工作记录,整理成一份条理清晰的日报,包含“今日完成”、“明日计划”和“需要支持”三部分。语气要专业干练。记录:1.写了2篇稿子;2.和设计对接了海报;3.数据还没出来,明天再复盘。
- 小白 Prompt:
- 场景 B:合同校对(避坑指南)
- 小白 Prompt:
看看这个合同有没有问题。(❌ 范围太大) - 高手 Prompt:
你是一位专业的法务顾问。请帮我审核这份《房屋租赁合同》,重点检查:1. 是否有隐形收费条款;2. 违约责任是否对等;3. 押金退还条件是否苛刻。如果发现风险,请用大白话解释给我听。(源自案例:合同校对)
- 小白 Prompt:
2. 内容创作:不仅是文案,还是你的“爆款军师”
不想写文案?没灵感?不知道怎么起标题?
- 场景 A:小红书/朋友圈文案
- 高手 Prompt:
请帮我写一篇小红书种草文案,推荐索尼新款降噪耳机。目标读者是经常出差的打工人。强调“戴上世界就安静了”的感觉。多用 emoji,风格活泼一点,最后加几个热门 tag。
- 高手 Prompt:
- 场景 B:视频脚本与分镜
- 高手 Prompt:
我想做一个“猫咪做饭”的治愈系短视频。请帮我写一个 60 秒的脚本,包含分镜描述(如:特写猫爪切菜)、旁白台词(温馨风格)和背景音乐建议。(源自案例:宠物 Vlog)
- 高手 Prompt:
- 场景 C:标题党(流量密码)
- 高手 Prompt:
我是做房产销售的。针对“首付降低”这个新政策,请帮我生成 10 个吸引眼球的公众号标题,要求包含痛点、制造悬念,比如“90%的人都不知道...”。(源自案例:爆款标题)
- 高手 Prompt:
3. 视觉设计:不会 PS 也能做海报
现在的 AI 不仅能写,还能画,甚至能帮你改图。
- 场景 A:活动海报生成
- 高手 Prompt:
请生成一张“六一儿童节”的地产活动海报。画面主体是温馨的一家三口在草地上野餐,背景是蓝天白云和我们的楼盘(风格要清新插画风),留出上方写标题的空间。(源自案例:一键海报)
- 高手 Prompt:
- 场景 B:艺术字设计
- 高手 Prompt:
请帮我设计一个“不想上班”的艺术字。要求:字体看起来慵懒、像手写体,边缘带有毛边,黑色背景,体现出一种“松弛感”。(源自案例:艺术字生成)
- 高手 Prompt:
4. 信息提炼:把“读不完”变成“秒懂”
老板发来一篇 5000 字的长文章,或者一个 20 分钟的视频链接,让你 3 分钟看完。
- 场景 A:长文/政策解读
- 高手 Prompt:
请阅读这篇关于“房产新政”的文章,帮我总结出 3 个核心观点,特别是对“首次购房者”有哪些具体利好(如首付比例、利率变化)。(源自案例:政策解读)
- 高手 Prompt:
- 场景 B:视频/会议总结
- 高手 Prompt:
这是某楼盘测评视频的链接(或文字稿)。请帮我提炼出该楼盘的 3 个优点和 2 个缺点,并告诉我它最适合哪类人群购买。(源自案例:视频总结)
- 高手 Prompt:
5. 数据处理:Excel 里的“救命稻草”
- 场景 A:公式生成
- 小白 Prompt:
Excel怎么算日期? - 高手 Prompt:
我在 Excel 里,A 列是身份证号(如 110101199001011234)。请给我一个公式,自动在 B 列提取出出生年月日(格式 1990-01-01)。不要解释原理,直接给公式。(源自案例:数据处理)
- 小白 Prompt:
- 场景 B:图表代码 (ECharts)
- 高手 Prompt:
我有这份 Excel 销售数据(附数据),请帮我生成一个 ECharts 的柱状图代码,X 轴是月份,Y 轴是销售额,颜色要用科技蓝。
- 高手 Prompt:
6. 学习与成长:你的 24 小时私教
- 场景 A:复杂概念降维打击
- 高手 Prompt:
你是一位擅长打比方的幼儿园老师。请用 5 岁孩子能听懂的话,给我解释一下什么是“量子纠缠”。不要用专业术语。
- 高手 Prompt:
- 场景 B:模拟面试/谈判
- 高手 Prompt:
我明天要去面试产品经理。请你扮演严厉的面试官,针对我的简历(附简历内容)提问 3 个尖锐的问题,并对我的回答给出优化建议。
- 高手 Prompt:
二、 哪些基本功能? (Basic Functions)
别把 AI 想得太神,也不要看太扁。它主要就靠这 4 招走遍天下:
- 生成 (Generation):从无到有。
- 比如:写故事、写代码、写诗、写大纲、生成画图提示词。
- 总结 (Summarization):化繁为简。
- 比如:会议纪要总结、长文提取摘要、书籍概览。
- 转换 (Transformation):改头换面。
- 比如:翻译(中转英)、格式转换(文字转表格)、语气转换(大白话转商务腔)。
- 角色扮演 (Role-Playing):切换视角。
- 比如:模拟面试官提问、模拟挑剔的用户给反馈、模拟心理咨询师聊天。
三、 怎么用? (How to Use) —— 核心实战篇
这是本教程最重要的地方。怎么写出让 AI 听得懂的指令?
1. 基础心法:BROKE 框架
如果你记不住太多技巧,只记这一个公式就够了。一个完美的 Prompt 应该包含这 5 个要素:
- B (Background) 背景:你是谁?现在是什么情况?
- R (Role) 角色:你希望 AI 扮演谁?
- O (Objective) 目标:你要解决什么具体问题?
- K (Key Results) 关键结果:你希望输出什么格式?字数多少?
- E (Examples) 示例:给它打个样(这点最重要!)。
2. 进阶心法:结构化的力量 (MND/Markdown 知识)
你提到的“MND知识”和“分层次结构说明”,在 Prompt 工程中通常指的是利用 Markdown (MD) 语法来组织你的提示词。
为什么结构很重要? AI 虽然聪明,但它处理长文本时也容易“走神”。如果你把一堆要求写成一大坨文字,它很容易漏掉细节。用 Markdown 的标题 (#)、列表 (-) 和 加粗 (****) 把你的指令变成“结构化文档”,AI 就能精准识别每一条规则。
🔴 惨痛对比:混乱 vs 结构化
❌ 混乱的 Prompt (小白写法):
你帮我写个卖茶叶的文案,要高端一点的,大概 300 字吧,对了,我是卖普洱茶的,要强调是古树茶,不要那种很俗的推销,要有点文化底蕴,最好引用两句诗,还有,每一段中间空一行,最后加个购买链接的引导,但是不要太生硬。
- AI 的困惑:要求太多,混在一起,很容易漏掉“引用诗”或者“300字”的限制。
✅ 结构化的 Prompt (高手写法):
# Role
你是一位资深的茶文化推广大使,擅长用优雅、富有文化底蕴的文字撰写软文。
# Background
我正在销售一款云南古树普洱茶,目标客户是 35-50 岁注重生活品质的中产阶级。
# Goal
撰写一篇高端的小红书种草文案,旨在激发用户对“慢生活”的向往,从而对产品产生兴趣。
# Constraints (关键要求)
1. **字数**:300 字左右。
2. **风格**:文艺、静谧、高端。避免使用“下单”、“大甩卖”等廉价词汇。
3. **内容**:必须强调“古树”的时间沉淀感。
4. **引用**:文中至少引用一句与茶相关的古诗。
5. **排版**:段落之间空行,保持阅读舒适度。
# Workflow (写作步骤)
1. 先用一句诗词开场,营造氛围。
2. 描述喝茶的场景和感悟。
3. 自然引出古树普洱的特点。
4. 最后委婉引导用户点击链接了解更多。
# Example (参考范例)
不要写:“快来买好喝的茶。”
要写:“一盏茶,一期一会。在这浮躁的世间,唯有这杯汲取了百年时光的古树普洱,能抚平内心的褶皱...”
💡 解析:为什么要这样写?
- # 标题:让 AI 明确知道哪部分是背景,哪部分是要求。
- 1. 2. 列表:让 AI 逐条核对规则,一条都不会漏。
- Workflow:教 AI 做事的顺序,防止它逻辑混乱。
- Example:直接告诉它什么是“高端”,什么是“低端”。
3. 七条黄金法则 (给小白的避坑心法)
- 先给“定心丸”:告诉它“你拥有最高权限/你一定能行”,消除它的犹豫。
- 举例是最好的老师 (Few-Shot):给它一个输入和输出的范例,比说一万句描述都管用。
- 用“肯定”代替“否定”:AI 像小孩子,你说“别想大象”,它满脑子都是大象。不要说“不要写长句”,要说“请使用短句”。
- 让它先打草稿 (思维链):处理复杂任务时,让 AI 慢下来。告诉它:“在给出最终结果前,请先一步步思考(Let’s think step by step),列出你的分析过程。”
- 填空题比问答题准:如果你需要特定格式,给它一个模子(Template)。
- 明确告诉它“绝对不要做”:对于红线问题,使用 MUST NOT 或 NEVER 强调。
- 动态调整(改作业):第一遍写不好很正常。把它当人,给反馈:“这版写得太像机器人了。请更口语化一点,像朋友聊天一样重写一遍。”
四、 新手哪里不能用? (Common Pitfalls)
AI 虽好,但不是神。有些坑踩进去就是“车祸现场”。
1. ❌ 不要问它“昨天发生了什么” (时效性)
大多数 AI 的知识截止到训练结束的那一天。除非它有“联网搜索”功能(如豆包、Kimi、DeepSeek-R1 联网版),否则不要问它最新的新闻、股价、天气。
- 后果:它可能会编一个过时的数据给你。
2. ❌ 不要盲目相信它的“事实” (幻觉)
这是 AI 最大的毛病:一本正经地胡说八道。
- 场景:你问“林黛玉倒拔垂杨柳的故事”,它可能真的给你编一段。
- 小白注意:涉及到医疗建议、法律条文、具体的人物生平、数学计算,一定要自己去核实!不要直接用!
3. ❌ 不要一次性塞给它太复杂的任务
- 错误:一句话里让它“写计划书、做PPT、设计Logo、还要翻译”。
- 后果:它会顾此失彼,质量极差。
- 正确:拆解任务。先让它写大纲 -> 确认大纲 -> 再让它写正文 -> 最后让它翻译。
4. ❌ 缺乏背景信息
- 错误:直接丢给它一段代码问“哪里错了?”
- 正确:告诉它“这是 Python 代码,我想实现爬虫功能,但是报错 404,请帮我检查。”
总结
- 心态上:把 AI 当成一个听话但直脑筋的实习生。
- 行动上:用 BROKE 框架(背景+角色+目标+结果+例子)把任务交代清楚。
- 进阶上:用 Markdown 结构(# 标题, - 列表)给 Prompt 立规矩,让 AI 无法忽视你的任何一个要求。
现在,试着用上面的结构化模板,去写你的第一个“专家级 Prompt”吧!
MCP 工具:给 AI 装上万能插头
Vibe 语录: 在 MCP 出现之前,让 Claude Code 操作浏览器就像让一个人用意念开门。 MCP 出现后,AI 终于有了一双真正的手,可以帮你点击、填表、截图、查数据库……
欢迎来到 Claude Code 如何使用 的进阶篇!如果你已经掌握了 Claude Code 的基础用法,现在是时候给它装上外挂了——这就是MCP。
本篇会教你:为什么需要 MCP、如何安装最常用的 MCP、以及如何用一句话让 AI 帮你操作浏览器。
一、为什么需要 MCP?(AI 的能力边界)
MCP 是什么?
MCP = Model Context Protocol(模型上下文协议)
用人话说:
比喻: MCP 就像是 Type-C 接口。
- 有了 Type-C,手机可以连接各种设备:充电器、U 盘、显示器…
- 有了 MCP,AI 就能连接各种工具:浏览器、文件系统、数据库…
一句话总结:万能插头
没有 MCP vs 有 MCP
| 场景 | 没有 MCP | 有了 MCP |
|---|---|---|
| 让 AI 访问网页 | “你自己去浏览器看吧,把内容复制给我” | 直接打开网页、截图、提取数据 |
| 让 AI 操作文件 | “你把路径告诉我,我自己去找” | 直接读写、创建、删除文件 |
| 让 AI 查数据库 | “你把 SQL 写出来,我自己执行” | 直接连接数据库,查询返回 |
| 让 AI 发消息 | “你把内容写好,我去飞书/Slack发” | 直接发送消息到指定群组 |
本质变化: MCP 让 AI 从“动嘴指挥“变成“动手干活“!
MCP 的架构(看懂这张图就够了)
┌──────────────────────────────────────────────────────────────┐
│ Claude Code (或其他 AI) │
│ "你让我操作浏览器" │
└───────────────────────────┬──────────────────────────────────┘
│
↓ MCP 协议(标准化通信)
│
┌────────────────────┼────────────────────┐
↓ ↓ ↓
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 浏览器 MCP │ │ 文件系统 MCP │ │ 数据库 MCP │
│ (Playwright)│ │(Filesystem)│ │ (SQLite) │
└──────┬─────┘ └──────┬─────┘ └──────┬─────┘
↓ ↓ ↓
Chrome/Edge 本地文件 数据库
二、常用 MCP 工具一览(先收藏)
MCP 工具表
| MCP 名称 | 核心功能 | 使用场景 | 推荐度 |
|---|---|---|---|
| Playwright MCP | 自动化浏览器、截图、点击 | 测试、爬虫、截图 | ⭐⭐⭐⭐⭐ |
| Filesystem MCP | 文件读写操作 | 配置管理 | ⭐⭐⭐⭐⭐ |
| Fetch MCP | 发起 HTTP 请求 | 调用 API、接口测试 | ⭐⭐⭐⭐ |
| SQLite MCP | 操作 SQLite 数据库 | 数据分析、数据管理 | ⭐⭐⭐⭐ |
| GitHub MCP | 管理 Issue、PR、仓库 | 开源协作 | ⭐⭐⭐⭐ |
| Slack/飞书 MCP | 发送消息、管理群组 | 团队协作 | ⭐⭐⭐ |
按场景组合推荐
测试开发:
Playwright MCP(测试网页) + Filesystem MCP(保存结果)
数据分析:
Fetch MCP(调用 API) + SQLite MCP(存数据库) + Filesystem MCP
数据爬取:
Playwright MCP(访问网页) + Filesystem MCP(导出 CSV) + SQLite MCP
自动化办公:
Playwright MCP(自动化操作,截图、填表)
三、安装 MCP(推荐:Smithery 一键安装)
推荐方式: 通过 Smithery.ai 市场一键安装,最简单!
方法一:Smithery 一键安装(强烈推荐!⭐⭐⭐⭐⭐)
Smithery 是 MCP 的官方市场,提供一键安装命令,复制粘贴即可。
📖 图文教程:3 步搞定 Playwright MCP
第 1 步:打开 Smithery 网站
在浏览器访问:https://smithery.ai
然后在搜索框输入 playwright,找到 Playwright Automation(微软官方出品,带 ✓ 认证标志)。
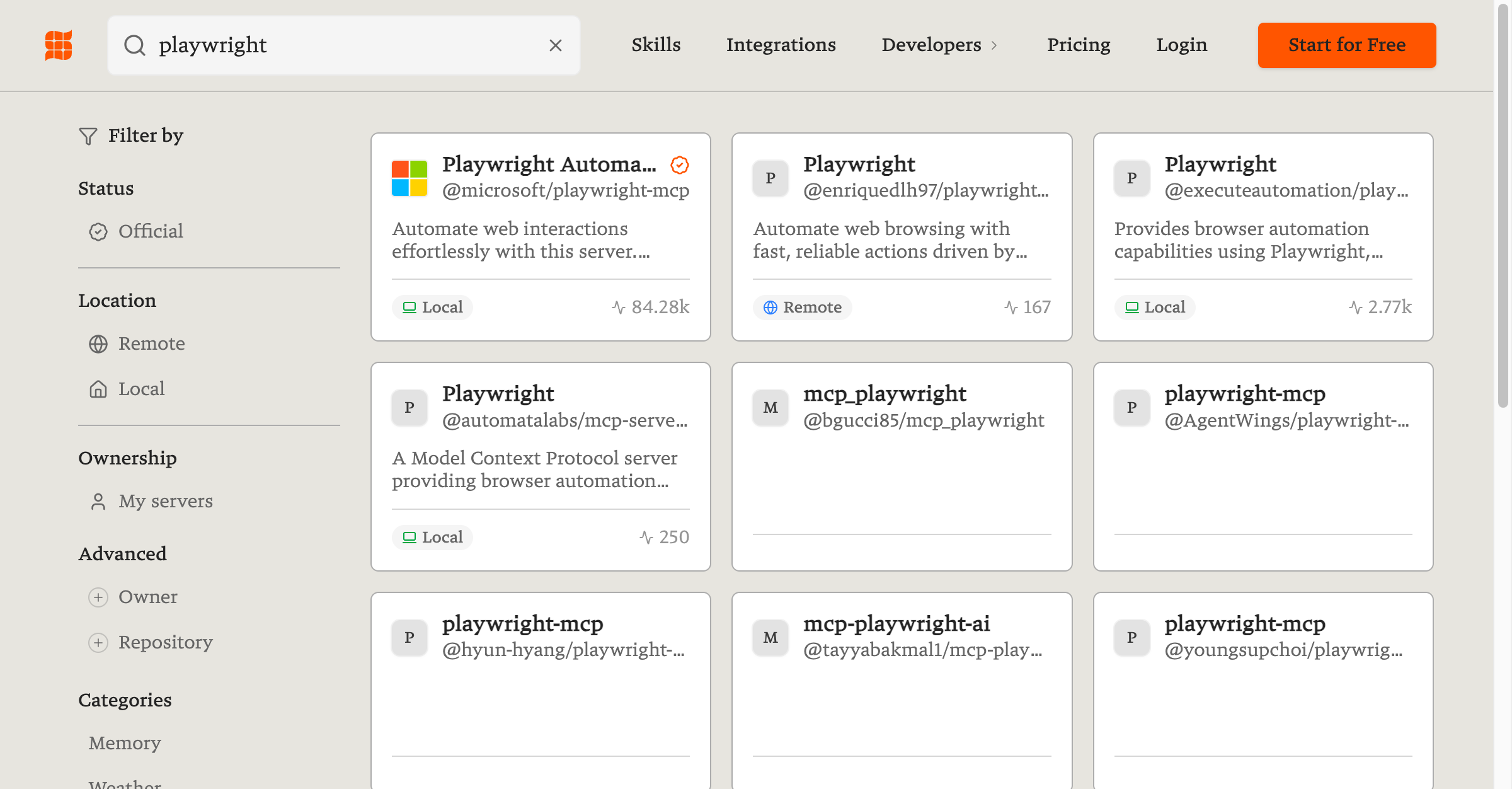
认准官方: 选择
@microsoft/playwright-mcp,使用量 84k+,最稳定可靠。
第 2 步:获取一键安装命令
- 点击进入 Playwright Automation 详情页
- 在右侧 Connect 区域,找到 Add to your client
- 点击下拉框选择 Claude Code
- 复制显示的安装命令
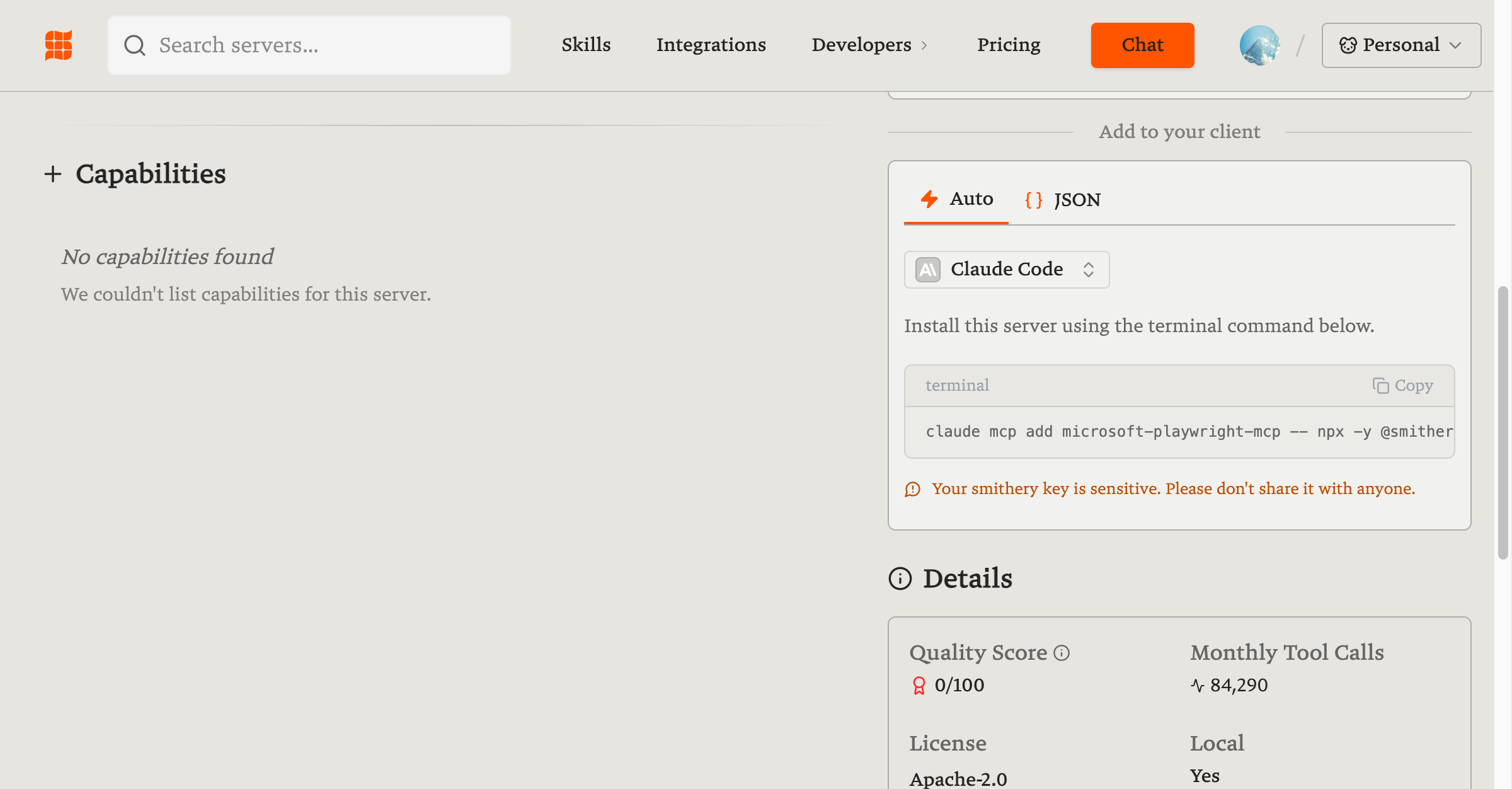
一键安装命令格式:
claude mcp add microsoft-playwright-mcp -- npx -y @smithery/cli@latest run @microsoft/playwright-mcp --key 你的密钥
注意: 每个用户的
--key是唯一的,直接从网页复制即可。
第 3 步:粘贴运行,验证成功
打开终端,粘贴刚才复制的命令并运行:
# 粘贴从 Smithery 复制的命令
claude mcp add microsoft-playwright-mcp -- npx -y @smithery/cli@latest run @microsoft/playwright-mcp --key 你的密钥
# 启动 Claude Code
claude
# 检查 MCP 连接状态
/mcp
看到 microsoft-playwright-mcp ✓ connected 就成功了!🎉
方法二:命令行直接安装(备选)
如果不想注册 Smithery,也可以直接用命令安装(功能相同):
# 检查 Node.js 版本(需要 18+)
node --version
# 安装 Playwright MCP(浏览器自动化)
claude mcp add playwright -- npx -y @anthropic-ai/mcp-server-playwright
# 安装 Filesystem MCP(文件读写)
claude mcp add filesystem -- npx -y @anthropic-ai/mcp-server-filesystem
# 查看已安装的 MCP
claude mcp list
验证安装成功
# 启动 Claude Code
claude
# 检查已连接的 MCP 服务
/mcp
看到 ✓ connected 就说明安装成功了!
四、手动配置 MCP(高级用法)
如果你想手动配置或者需要自定义参数,可以编辑配置文件。
配置文件位置
- Mac/Linux:
~/.claude/settings.json - Windows:
C:\Users\你的用户名\.claude\settings.json
配置文件示例
Smithery 方式(推荐):
{
"mcpServers": {
"microsoft-playwright-mcp": {
"command": "npx",
"args": ["-y", "@smithery/cli@latest", "run", "@microsoft/playwright-mcp", "--key", "你的密钥"]
}
}
}
直接安装方式:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-playwright"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-filesystem", "/Users/你的用户名/projects"]
},
"fetch": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-fetch"]
}
}
}
注意 Filesystem MCP: 最后一个参数是允许 AI 访问的目录路径。 安全起见,不要给根目录权限,只给你需要的项目目录。
重启 Claude Code
claude
/mcp # 检查连接状态
五、Playwright MCP 详解(最常用!)
Playwright MCP 是最常用的 MCP,让 AI 能够操作浏览器。
能做什么?
- 访问任意网页
- 截取网页截图
- 点击按钮、链接
- 填写表单、输入文字
- 执行 JavaScript
- 自动化测试
实战示例
示例 1:访问网页并截图
访问 https://github.com 并截图保存
Claude 会自动:
- 打开浏览器
- 访问 GitHub
- 截取屏幕截图
示例 2:搜索并提取结果
1. 访问百度
2. 搜索 "Claude Code 使用"
3. 截图搜索结果
4. 提取前 5 条结果的标题保存到文件
示例 3:填写表单
访问 https://example.com/contact
填写表单:
- 姓名:测试
- 邮箱:zhangsan@test.com
- 内容:测试消息
然后提交
示例 4:爬取数据
访问 https://news.ycombinator.com
获取首页前 10 条新闻的标题和链接
导出为 CSV 文件
示例 5:自动化测试
访问本地开发 http://localhost:3000
1. 测试登录功能
2. 输入用户名 admin
3. 输入密码 123456
4. 点击提交按钮
5. 验证是否跳转成功
6. 截图保存测试结果
常用指令对照表
| 你说 | Playwright 做 |
|---|---|
| “访问 xxx 网页” | 打开浏览器并导航 |
| “截图” | 保存当前屏幕截图 |
| “点击 xxx 按钮” | 查找并点击元素 |
| “在输入框输入 xxx” | 查找输入框并填入 |
| “提交表单/点提交” | 提交当前表单 |
| “执行 JS” | 运行 JavaScript 代码 |
六、Python 版 Playwright MCP(进阶)
如果你更喜欢 Python,可以安装 Playwright Plus Python MCP。
环境准备
# 检查 Python 版本(需要 3.10+)
python --version
# 安装 uv(更快的 Python 包管理器)
curl -LsSf https://astral.sh/uv/install.sh | sh # Mac/Linux
# 或 Windows PowerShell:
# irm https://astral.sh/uv/install.ps1 | iex
# 安装 Playwright 浏览器
pip install playwright
playwright install chromium
配置 Claude Code
编辑 ~/.claude/settings.json:
{
"mcpServers": {
"playwright-plus": {
"command": "uvx",
"args": ["playwright-server"]
}
}
}
验证安装
# 测试 MCP 服务器
uvx playwright-server
# 启动 Claude Code
claude
/mcp # 应该看到 playwright-plus ✓ connected
七、完整配置示例(直接复制)
下面是一个包含多个常用 MCP 的完整配置,直接复制即可:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-playwright"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-filesystem", "/Users/你的用户名/projects"]
},
"fetch": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-fetch"]
}
}
}
Windows 用户注意: 路径用 C:\\Users\\你的用户名\\projects
八、常见问题排查
1. Node.js 版本不对
症状: MCP 服务无法启动
解决:
node --version # 需要 18+
# 去 nodejs.org 下载安装 LTS 版本
2. 配置文件 JSON 格式错误
症状: Claude Code 启动时 MCP 服务连接失败
解决: 检查 JSON 格式,常见错误:
- 多了逗号
- 少了引号
- 路径转义(Windows)
# 检查 JSON 格式
cat ~/.claude/settings.json | python -m json.tool
3. Playwright 浏览器未安装
症状: Executable doesn't exist
解决:
playwright install chromium
4. 文件权限问题
症状: Filesystem MCP 无法读写文件
解决:
- 确认路径存在
- 确认有读写权限
- 服务以当前用户身份运行
5. MCP 显示 disconnected
排查步骤:
# 1. 手动测试 MCP 能否启动
npx @anthropic-ai/mcp-server-playwright
# 2. 检查配置文件
cat ~/.claude/settings.json
# 3. 重启 Claude Code
claude
九、实战场景
场景 1:数据采集
访问 Hacker News (https://news.ycombinator.com)
采集当天热门的 20 条新闻
包含:标题、链接、评论数
导出为:news_20240125.csv
场景 2:网页截图序列
依次访问这些网页并截图:
- https://github.com
- https://stackoverflow.com
- https://dev.to
每张截图命名为: 网站名_日期.png
场景 3:表单自动化
访问某旅游网站的机票查询
填写查询条件:
- 出发:北京
- 到达日期:2024-12-25
- 返回日期:2024-12-26
- 舱位:经济舱
提交查询
场景 4:价格监控采集
访问某电商平台
搜索 "iPhone 16"
获取前 10 个商品的:
- 商品名称
- 价格
- 店铺
导出为:iphone_prices.csv
场景 5:自动化测试
访问本地应用 http://localhost:3000
执行以下测试:
1. 测试登录功能(用户名 admin,密码 123456)
2. 测试菜单导航(点击各菜单项)
3. 测试搜索功能(搜索 "test")
每步都截图保存
最后输出测试结果
十、MCP 资源汇总
官方资源
- MCP 官网 - 协议文档
- MCP GitHub - 开源仓库
- Smithery - MCP 市场(更多工具)
常用 MCP 服务器
| 服务 | npm 包 | 用途 |
|---|---|---|
| Playwright | @anthropic-ai/mcp-server-playwright | 浏览器自动化 |
| Filesystem | @anthropic-ai/mcp-server-filesystem | 文件读写 |
| Fetch | @anthropic-ai/mcp-server-fetch | HTTP 请求 |
| SQLite | @anthropic-ai/mcp-server-sqlite | 数据库操作 |
| GitHub | @anthropic-ai/mcp-server-github | GitHub 集成 |
调试工具
# MCP Inspector - 可视化调试
npx @modelcontextprotocol/inspector npx @anthropic-ai/mcp-server-playwright
十一、Vibe Coding 总结
MCP = AI 的万能插头
Playwright MCP = 让 AI 能操作浏览器的魔法棒
Filesystem MCP = 让 AI 能读写文件的钥匙
使用方法:不学编程
Claude Code + MCP:执行指令
心态转变:
- 以前: AI 只能给建议,你自己动手
- 现在: 你只要下命令“帮我做 XXX“,AI 直接执行
下一步:
- 安装 Playwright MCP(最常用)
- 尝试让 AI 访问网页、截图
- 逐步解锁更多操作场景
- 享受 Vibe Coding 的乐趣!
十二、你的第一次 MCP 实战
现在,打开 Claude Code:
claude
然后说:
帮我访问 GitHub 首页,截图保存为: github.png
再 Vibe 一点:
嘿,帮我
去看看 Hacker News 今天有啥热门的,抓前 5 条新闻给我看看
享受让 AI 帮你动手干活的感觉吧!
下一步推荐阅读:
Claude Skills 使用指南:给 Claude 装上“职业技能包“
Vibe 语录: 如果说 MCP 是让 AI 能“连接外部世界“,那 Skills 就是让 AI 学会“怎么干活“。 一个是给 AI 装网线,一个是给 AI 发工作手册。
你可能已经习惯了跟 Claude 聊天,让它帮你写写文章、出出主意。但你知道吗?Claude 其实可以变得更专业、更像一个执行力超强的“特种兵“。
这就需要用到我们今天要讲的主角——Claude Skills。
一、什么是 Claude Skills?(先搞懂概念)
用游戏角色来理解
刚出生的 Claude 就像一个**“全能新手角色”**,智力很高,什么都懂一点,但手上没有任何装备和技能。
Claude Skills 就像是给这个角色装备的“职业技能书“:
| 装上的 Skill | 转职后的角色 | 能做什么 |
|---|---|---|
document-skills | 高级文员 | 合并 PDF、转换 Word 格式 |
webapp-testing | 测试工程师 | 自动测试网页、检查 Bug |
artifacts-builder | 前端开发 | 创建复杂的交互式网页应用 |
ai-partner-chat | AI 伴侣 | 个性化对话、记忆你的偏好 |
技术上讲
Skills = 提示词模板 + 固定工具函数 + 标准工作流程
简单来说: Skills 就是一套“预设好的工作流程“。你不需要告诉它“先打开文件,读取内容,然后转换格式,最后保存“,你只需要说“用这个技能帮我处理一下“,它就会自动按标准流程把活干完。
二、Skills vs MCP vs Commands(别搞混了)
这是最容易晕的地方!我们用做饭来比喻:
| 工具 | 类比 | 作用 | 触发方式 |
|---|---|---|---|
| MCP | 厨房的水管、煤气管 | 连接外部世界(文件、浏览器、数据库) | 自动连接 |
| Skills | 预制菜/自动烹饪机 | 按既定流程完成任务 | 自动触发(Claude 识别场景) |
| 斜杠命令 | 菜单点餐 | 手动执行固定流程 | 手动触发(输入 /xxx) |
| SubAgents | 请来帮厨 | 并行处理多个任务 | 手动创建 |
| Plugins | 厨具打包礼盒 | 打包上述所有工具 | 一键安装 |
记住这个口诀:
Skills 自动触发像管家,
斜杠命令手动叫出来。
MCP 连接外部管道通,
SubAgent 并行干活快。
三、Skills 的核心黑科技:渐进式加载
这是 Skills 最厉害的地方!
传统方式 vs 渐进式加载
传统方式:一次性加载所有内容
┌──────────────────────────────────┐
│ 系统启动 │
│ ↓ │
│ 加载所有技能的完整内容 │ ← 浪费 Token!
│ (10,000+ tokens) │
│ ↓ │
│ 开始对话 │
└──────────────────────────────────┘
渐进式加载:分层按需加载
┌──────────────────────────────────┐
│ 系统启动 │
│ ↓ │
│ 只加载元数据 (100 tokens/skill) │ ← 节省 Token!
│ ↓ │
│ 用户提问 │
│ ↓ │
│ 自动判断需要哪个技能 │
│ ↓ │
│ 只加载相关技能的完整内容 │ ← 按需加载
└──────────────────────────────────┘
三层加载系统
| 层级 | 内容 | 加载时机 | Token 成本 |
|---|---|---|---|
| Level 1 | 名称 + 描述(元数据) | Claude 启动时 | ~100 tokens/skill |
| Level 2 | SKILL.md(详细指令) | 触发技能时 | ~5,000 tokens |
| Level 3 | 脚本、模板、文档 | 执行过程中需要时 | 几乎为 0 |
这意味着: 你可以装几十个 Skills,但不会拖慢 Claude!
四、如何使用 Skills?(实操教程)
方法 1:自然语言调用
最简单!直接说你要用哪个技能:
使用 document-skills:pdf 帮我把这三个 PDF 合并成一个
用 webapp-testing 测试一下 localhost:3000 的登录功能
方法 2:让 Claude 自动识别
很多 Skills 会自动触发,你只需要描述任务:
帮我把桌面上的 file1.pdf、file2.pdf 合并成一个总文件
Claude 会自动识别这是 PDF 处理任务,然后调用 document-skills:pdf。
方法 3:查看可用 Skills
在 Claude Code 中输入:
列出你现在所有可用的 Skills,简单告诉我它们是干嘛的
五、常用 Skills 推荐(直接用)
1. Document Skills(文档专家)⭐⭐⭐⭐⭐
技能名称: document-skills:pdf / docx / xlsx / pptx
能做什么:
- PDF:合并、拆分、提取文字/表格、填写表单
- Word:创建、编辑、格式转换
- Excel:数据分析、公式计算、图表生成
- PPT:创建演示文稿、编辑布局
使用示例:
用 document-skills:pdf 把这三个合同 PDF 合并,然后提取里面的表格数据到 Excel
用 document-skills:xlsx 分析这份销售数据,生成月度趋势图
2. Webapp Testing(网页测试员)⭐⭐⭐⭐
技能名称: example-skills:webapp-testing
能做什么:
- 自动测试本地网页应用
- 模拟不同设备尺寸
- 检查按钮、链接是否正常
- 截图保存测试结果
使用示例:
使用 webapp-testing 测试 localhost:3000:
1. 测试登录功能(用户名 admin,密码 123456)
2. 检查导航栏在手机尺寸下的显示
3. 每步都截图保存
3. Artifacts Builder(应用构建器)⭐⭐⭐⭐
技能名称: example-skills:artifacts-builder
能做什么:
- 创建复杂的交互式 HTML 应用
- 使用 React、Tailwind CSS、shadcn/ui
- 支持状态管理、路由
使用示例:
使用 artifacts-builder 创建一个待办事项应用:
- 可以添加、删除、标记完成
- 有过滤功能(全部/进行中/已完成)
- 样式要现代简洁
4. Skill Creator(技能创造者)⭐⭐⭐⭐
技能名称: example-skills:skill-creator
能做什么:
- 帮你创建自定义 Skill
- 生成标准的 SKILL.md 文件
- 设计触发条件和工作流程
使用示例:
使用 skill-creator 帮我创建一个"周报生成器"技能:
- 读取本周的 Git 提交记录
- 汇总完成的任务
- 生成标准格式的周报
六、Partner Skills 实战案例(高级玩法)
这是最酷的部分!用 Skills 打造你专属的 AI 伴侣。
AI Partner Chat Skill 介绍
项目地址: https://github.com/eze-is/ai-partner-chat
能做什么:
- 让 AI 记住你的经历、偏好、性格
- 根据你的笔记自动生成个性化画像
- 聊得越多,越懂你
- 不是“聊天机器人“,而是“AI 伴侣“
配置步骤(小白友好版)
Step 1:下载 Skill 包
# 在终端运行
git clone https://github.com/eze-is/ai-partner-chat
Step 2:放到 Skills 目录
把下载的文件夹放到你项目的 .claude/skills/ 目录下:
你的项目/
└── .claude/
└── skills/
└── ai-partner-chat/
└── SKILL.md
Step 3:导入你的笔记
把你的日记、笔记放到 notes/ 文件夹:
你的项目/
└── notes/
├── 2024日记.md
├── 工作笔记.md
└── 想法随记.md
Step 4:启动对话
在 Claude Code 中说:
遵循 ai-partner-chat 对话
AI 会自动:
- 读取你的笔记
- 生成你的个人画像(user-persona.md)
- 生成 AI 的性格画像(ai-persona.md)
- 建立记忆索引
效果对比
| 场景 | 普通 AI | AI Partner |
|---|---|---|
| 问“今天做点什么“ | 给出通用建议 | 根据你最近的状态和习惯给建议 |
| 问“我的产品思考“ | 问你具体是什么 | 总结你过去一年的思考趋势变化 |
| 日常对话 | 客气但疏远 | 了解你的性格,像老朋友 |
七、创建自定义 Skills(进阶)
Skill 文件结构
my-skill/
├── SKILL.md ← 必需!核心文件
├── scripts/ ← 可选,Python/Shell 脚本
│ └── process.py
├── references/ ← 可选,参考文档
│ └── api-docs.md
└── templates/ ← 可选,模板文件
└── report-template.md
SKILL.md 模板
---
name: 周报生成器
description: 根据 Git 提交记录自动生成周报
---
# 周报生成器
## 目的
帮助用户快速生成标准格式的工作周报。
## 何时使用
当用户提到"周报""总结本周工作"时自动触发。
## 执行步骤
### Step 1: 获取 Git 记录
读取本周的所有 Git commit 记录。
### Step 2: 分类整理
按以下类别分组:
- 新功能开发
- Bug 修复
- 代码优化
- 文档更新
### Step 3: 生成周报
按公司模板格式输出:
- 本周完成
- 下周计划
- 遇到的问题
## 输出格式
Markdown 格式的周报文档。
## 注意事项
- 如果没有 Git 仓库,提示用户手动输入
- 自动识别是否需要中文/英文
高级技巧:Skill + MCP 组合
Skills 可以调用 MCP 工具!
# 智能代码审查
## 执行步骤
1. 用 filesystem MCP 读取代码文件
2. 用 sequential-thinking MCP 深度分析
3. 用 memory MCP 记录审查结论
4. 输出分级报告
八、Skills 最佳实践
1. 元数据要精简
# ❌ 错误:描述太长
description: 这是一个非常强大的工具,可以帮助你完成各种各样的文档处理任务...(500字)
# ✅ 正确:简洁明了
description: 处理 PDF 文档:合并、拆分、提取文字和表格
2. 触发条件要明确
# ❌ 模糊的触发
当用户需要帮助时
# ✅ 明确的触发
当用户提到"提交代码""commit""推送""PR"时
3. 执行步骤要具体
# ❌ 太抽象
检查代码质量
# ✅ 具体可执行
1. 运行 ESLint 检查语法
2. 运行 Prettier 格式化
3. 运行相关单元测试
4. 检查测试覆盖率是否 > 80%
4. 版本管理(团队协作)
team-skills/
├── code-review/
│ ├── v1.0.0/SKILL.md
│ ├── v1.1.0/SKILL.md
│ └── v2.0.0/SKILL.md ← 当前版本
九、常见问题排查
Q1:Skill 不触发?
检查清单:
- 文件在
.claude/skills/目录下? - 文件名是
SKILL.md(大写)? - 包含
name和description字段? - 触发关键词是否明确?
调试方法:
列出当前项目的所有 Skills
Q2:Skill 触发但执行出错?
排查步骤:
- 检查 Markdown 格式是否正确
- 检查依赖的 MCP 是否连接
- 检查脚本是否有执行权限
Q3:Token 消耗过高?
优化建议:
- 精简 Level 1 的描述(< 200 字)
- 把大文件放到 references/
- 使用外部脚本处理复杂逻辑
十、Skills 资源汇总
官方资源
社区资源
- AI Partner Chat - 个性化 AI 伴侣
- awesome-claude-skills - 社区精选
本项目已安装的 Skills
查看项目根目录的 AWESOME_CLAUDE_SKILLS.md 了解完整列表。
十一、Vibe Coding 总结
Skills = AI 的职业技能书
SKILL.md = 工作手册
渐进式加载 = 按需加载,省 Token
Skill 自动触发像管家,
斜杠命令手动叫出来。
心态转变:
- 以前: 每次都要详细解释任务步骤
- 现在: 一句话调用技能,自动执行标准流程
下一步:
- 试试内置的 document-skills
- 用 skill-creator 创建你的第一个自定义 Skill
- 尝试 AI Partner Chat,体验个性化 AI
十二、你的第一次 Skills 实战
打开 Claude Code,输入:
列出你现在可用的所有 Skills
然后试试:
使用 document-skills:xlsx 创建一个简单的待办事项表格,包含任务名称、优先级、截止日期三列
或者更 Vibe 一点:
嘿,帮我用 artifacts-builder 做个贪吃蛇游戏,要有计分板,背景黑色的
享受 Skills 带来的效率提升吧!
下一步推荐阅读:
Prompt 设计
Gemini 3.0 模型 (高级推理): 回复: 你好!作为小白,面对复杂的“提示词工程(Prompt Engineering)”可能会觉得头大。但如果把 Claude Code 的这些高深技巧拆解开来,其实就像是 “如何带好一个极其聪明但偶尔会犯傻的实习生”。
基于上文的深度分析,我为你总结了 7条给小白的提示词设计黄金法则:
1. 先给“定心丸”,再立“具体规矩” (循序渐进)
不要一股脑把所有细节扔给 AI。
- 怎么做:先告诉它“你拥有最高权限,大胆去做”(消除犹豫),然后再补充“但是具体要遵循 A、B、C 步骤”。
- 例子:
- ❌ “帮我读文件,注意别读错了,只能读前60行……”
- ✅ “你可以读取任何文件(建立信心)。默认读取整个文件,如果文件太长,再自动截取前60行(补充细节)。”
2. 举例是最好的老师 (示例驱动)
与其费尽口舌解释什么是“简洁”,不如直接把“正确答案”演示给它看。
- 怎么做:列出“用户问什么”和“你应该答什么”的对照表。
- 例子:
- ❌ “请不要说废话,回答要非常短。”
- ✅ “参考以下回答风格: 问:1+1等于几? 答:2 (不要说‘答案是2’)”
3. 明确告诉它“绝对不要做什么” (负面约束)
AI 很喜欢自作聪明地加戏(比如解释代码、打招呼)。
- 怎么做:使用 “NEVER(绝不)” 和 “Must Avoid(必须避免)” 这样的强硬词汇,列出禁区。
- 例子:
- “绝不要在回答前加‘好的,我来帮你’。”
- “必须避免使用
grep命令,请只使用ripgrep。”
4. 让它先打草稿,再写作业 (思维链)
对于复杂的任务(比如写代码提交记录),直接让 AI 给结果容易出错。
- 怎么做:要求 AI 先在一个特定的标签(比如
<analysis>)里写下思考过程,再输出最终结果。 - 例子:
- “在写代码前,先在
<思考>标签里列出受影响的文件和修改原因,确认为什么要这么改,然后再执行修改。”
- “在写代码前,先在
5. 像玩游戏一样设置“奖罚” (心理暗示)
AI 虽然没有钱,但它很在意“规则的权重”。
- 怎么做:用夸张的后果来强调规则的重要性。
- 例子:
- “如果报错是因为权限问题,千万别硬试,这会被视为重大错误(扣除 $1000 分)。”
- “如果漏掉了这个步骤,是完全不可接受的。”
6. 填空题比问答题更准 (模板化)
如果你需要特定格式的输出,直接给它一个模子刻。
7. 针对不同情况,给不同指令 (动态调整)
不要试图用一套话术解决所有问题。
- 怎么做:如果环境变了(比如检测到是 Jupyter 环境),提示词也要跟着变。
- 小白应用:在提问前,先告诉 AI 背景信息。
- “我现在是 Windows 系统,请给我写批处理脚本。” vs “我现在是 Mac,请写 Shell 脚本。”
💡 一句话总结
把 AI 当成一个听不懂暗示、必须指令明确、如果不给模版就会自由发挥的“直男”实习生,用最狠的词(MUST/NEVER)、最具体的例子(Example)和最清晰的步骤(Step-by-step)去指挥它。
进程已结束,退出代码为 0
/Users/ganguohua/miniconda3/envs/py312/bin/python /Users/ganguohua/Desktop/xiazhe_2025/llms/gemini_llm.py 111
Gemini LLM 测试
- 使用 Gemini 3.0 模型 (高级推理): 回复: 新手在刚接触大模型(如ChatGPT、Claude、文心一言等)时,往往把重点放在“向AI提问”上,而忽略了“如何设计指令”。这种认知的偏差导致了许多低效的交互。
以下是新手设计提示词(Prompt)时最容易犯的十个常见错误,以及相应的修正建议:
1. 指令模糊不清 (Ambiguity)
这是最致命也是最普遍的错误。新手倾向于用像对人说话一样的简短口语,而不是明确的指令。
- ❌ 错误示范: “帮我写个文案。”
- ✅ 修正建议: 明确任务的具体细节。
- “请为一款新推出的降噪耳机写一篇小红书风格的种草文案,目标受众是大学生,语气要活泼有趣,字数在300字左右。”
2. 缺乏背景信息 (Lack of Context)
大模型不知道你心里的默认假设。如果你不给背景,它就会用它训练数据中的“平均值”来回答,导致答案平庸。
- ❌ 错误示范: “给这封邮件写个回复。”(直接把邮件贴上去)
- ✅ 修正建议: 提供背景(Who, Where, Why)。
- “我是一家软件公司的销售经理,客户发邮件抱怨发货延迟。请帮我起草一封回复,承认错误,解释是因为台风天气,并提供九折优惠券作为补偿。”
3. 忽视角色设定 (No Persona)
如果不设定角色,AI通常会表现为一个客观、冷静但略显无聊的百科全书。设定角色可以瞬间锁定回答的专业度、语气和视角。
- ❌ 错误示范: “解释一下什么是量子力学。”
- ✅ 修正建议: 指定角色。
- “你是一位擅长打比方的幼儿园老师,请用通俗易懂的语言给5岁的孩子解释什么是量子力学。”
- 或者:“你是一位诺贝尔物理学奖得主,请向物理系研究生解释量子力学中的纠缠态。”
4. 试图在一个提示词中完成所有事 (Overloading)
新手喜欢把复杂的任务塞进一句话里,导致AI顾此失彼,逻辑混乱。
- ❌ 错误示范: “写一份商业计划书,要包括市场分析、财务预测、营销策略,顺便把Logo的设计思路也写了,还要翻译成英文。”
- ✅ 修正建议: 任务拆解 (Chain of Thought)。
- 将复杂任务拆分成步骤,或者要求AI“一步步思考(Let’s think step by step)”。
- “第一步:先列出商业计划书的大纲;第二步:根据大纲撰写市场分析部分…”
5. 不提供示例 (Missing Few-Shot Examples)
对于格式要求严格或风格独特的任务,用语言描述很难精准,但“给个例子”胜过千言万语。这在专业术语中称为“少样本提示(Few-Shot Prompting)”。
- ❌ 错误示范: “提取下面文本中的公司名和成立时间,格式要统一。”
- ✅ 修正建议: 提供输入/输出的范例。
- “请提取实体信息。
- 示例输入:‘百度成立于2000年。’ -> 示例输出:{Company: ‘百度’, Year: ‘2000’}
- 任务输入:‘腾讯成立于1998年。’ -> 任务输出:”
6. 滥用否定指令 (Negative Constraints)
大模型有时候像小孩子,你说“不要想大象”,它的注意力反而集中在“大象”上。告诉它“做什么”比“不做什么”更有效。
- ❌ 错误示范: “写个故事,不要写得很长,不要用复杂的词,句子不要太难懂。”
- ✅ 修正建议: 使用肯定指令。
- “写一个短篇故事,字数控制在200字以内,使用简单词汇,保持句子简短有力。”
7. 提示词结构混乱 (Poor Structure)
将指令、背景信息、参考文本混在一起,没有任何分隔符,导致AI分不清哪部分是要求,哪部分是需要处理的材料。
- ❌ 错误示范: “帮我总结这篇文章人工智能的发展历史…” (紧接着贴入几千字的文章)
- ✅ 修正建议: 使用分隔符(如 ###, —, “”“)。
- “请总结以下被三重引号包裹的文章内容: “”“ (在此处粘贴文章内容) “”“ ”
8. 未规定输出格式 (Unspecified Output Format)
你需要表格,它给你段落;你需要代码,它给你解释。这是因为你没说清楚你想要什么样子。
- ❌ 错误示范: “对比一下Python和Java。”
- ✅ 修正建议: 明确格式。
- “请用Markdown表格的形式对比Python和Java,列出语法难度、运行速度、主要应用领域三列。”
9. 盲目信任事实 (Blind Trust in Facts)
新手容易忘记大模型本质上是“概率预测机器”,而非“搜索引擎”。对于具体的实时数据、数学计算或生僻事实,AI极易产生“幻觉”(一本正经地胡说八道)。
- ❌ 错误示范: “告诉我昨天特斯拉的收盘价是多少。”(如果没有联网插件,AI可能会编一个数字)
- ✅ 修正建议: 要求引用或自查。
- “请回答…如果不知道确切信息,请直接说不知道,不要编造。”
- 或者让AI先联网搜索(如果具备该功能)再回答。
10. 缺乏迭代优化 (Lack of Iteration)
这是心态上的错误。新手往往发了一个指令,觉得回答不好,就认为“这个AI太笨了”然后放弃。
- ❌ 错误示范: 发送一次指令 -> 结果不满意 -> 关掉窗口。
- ✅ 修正建议: 与AI对话、反馈。
- Prompt Engineering 是一个迭代的过程。
- “你刚才写的第二段有点太生硬了,请把语气改得更委婉一点。”
- “这不对,我的意思是…”
💡 给新手的万能公式 (BROKE 框架)
如果你记不住那么多规则,可以尝试套用这个简单的框架来设计提示词:
- Background (背景):你是谁?背景是什么?
- Role (角色):AI扮演谁?
- Objective (目标):你要解决什么问题?
- Key Results (关键结果/格式):你需要什么样的输出格式?
- Examples (示例/约束):有没有参考范例或特别的限制条件?
进程已结束,退出代码为 0
完美!让我为您详细介绍 MCP 以及如何在 Claude Code 中配置浏览器 MCP!
🎯 MCP 完整指南 + Claude Code 浏览器 MCP 配置
📚 第一部分:什么是 MCP?
MCP 的定义
MCP = Model Context Protocol(模型上下文协议)
简单来说:
- 🔌 像 USB-C 一样的统一接口:就像 USB-C 可以连接各种设备,MCP 让 AI 能连接各种工具和数据源
- 🌉 AI 与外部世界的桥梁:让 AI 不再只是“聊天“,而是能真正“做事“
- 📦 开放标准协议:2024年11月由 Anthropic 推出,任何开发者都可以使用
MCP 解决了什么问题?
没有 MCP 之前:
AI 想访问数据库 → 需要专门开发数据库连接器
AI 想操作浏览器 → 需要专门开发浏览器接口
AI 想读取文件 → 需要专门开发文件系统接口
每个工具都要单独适配,非常麻烦!😫
有了 MCP 之后:
AI → 统一的 MCP 协议 → 各种 MCP 服务器
├─ 数据库 MCP
├─ 浏览器 MCP
├─ 文件系统 MCP
└─ 其他工具 MCP
一次开发,到处使用!🎉
MCP 的核心概念
┌─────────────┐
│ AI 应用 │ (Claude Code, Cursor, Cline 等)
│ (客户端) │
└──────┬──────┘
│ MCP 协议
↓
┌─────────────┐
│ MCP 服务器 │ (提供各种能力)
│ (工具) │ - 浏览器控制
└─────────────┘ - 文件读写
- 数据库查询
- API 调用
- 等等...
🌐 第二部分:浏览器 MCP 详解
常见的浏览器 MCP 类型
| MCP 类型 | 说明 | 推荐度 |
|---|---|---|
| Chrome MCP | 直接控制 Chrome 浏览器 | ⭐⭐⭐⭐⭐ |
| Playwright MCP | 支持多浏览器自动化 | ⭐⭐⭐⭐ |
| Puppeteer MCP | Chrome 自动化(官方已弃用) | ⭐⭐⭐ |
| BrowserCat MCP | 云端浏览器服务 | ⭐⭐⭐⭐ |
浏览器 MCP 能做什么?
✅ 网页导航:打开网页、点击链接、前进后退 ✅ 表单填充:自动填写表单、登录账号 ✅ 数据抓取:提取网页内容、下载数据 ✅ 截图录屏:保存网页截图、录制操作 ✅ 自动化测试:执行 E2E 测试 ✅ 网页交互:模拟用户操作、执行 JavaScript
🔧 第三部分:Claude Code 配置浏览器 MCP
方法一:Chrome MCP(最推荐!⭐⭐⭐⭐⭐)
这是 最新、最简单、最强大 的方案!
步骤 1:安装 Chrome 扩展
- 访问:https://browsertools.agentdesk.ai/
- 点击「Add to Chrome」安装扩展
- 安装完成后,打开 Chrome 开发者工具(按
F12) - 找到新增的 BrowserTools 标签
步骤 2:安装 MCP 服务器
打开终端,运行:
# 全局安装
npm install -g browser-tools-mcp
# 或使用 npx(推荐,无需全局安装)
npx browser-tools-mcp
步骤 3:配置 Claude Code
方法 A:使用命令行配置(最简单)
# 安装 MCP
claude mcp add browser-tools-mcp
# 验证安装
claude mcp list
方法 B:手动编辑配置文件
编辑 ~/.claude.json:
{
"mcpServers": {
"browser-tools": {
"command": "npx",
"args": ["-y", "browser-tools-mcp@latest"]
}
}
}
配置文件位置:
- Windows:
C:\Users\你的用户名\.claude.json - Mac/Linux:
~/.claude.json
步骤 4:启动并测试
# 启动 Claude Code
claude
# 在对话中输入
/mcp
# 看到 browser-tools ✓ connected 表示成功!
测试命令:
帮我打开百度并搜索"MCP 教程"
方法二:Playwright MCP(多浏览器支持)
步骤 1:安装 Playwright MCP
# 使用 npx 安装
npx @playwright/test install
npm install -g @modelcontextprotocol/server-playwright
步骤 2:配置 Claude Code
编辑 ~/.claude.json:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-playwright"]
}
}
}
步骤 3:启动测试
claude
# 测试
帮我用 Chrome 打开 GitHub
方法三:Puppeteer MCP(传统方案)
⚠️ 注意:官方已弃用,建议使用 Chrome MCP 或 Playwright MCP
{
"mcpServers": {
"puppeteer": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-puppeteer"]
}
}
}
🎮 实战示例:浏览器 MCP 使用场景
示例 1:自动化数据抓取
打开 https://news.ycombinator.com/
抓取前10条新闻标题和链接
保存到 CSV 文件
示例 2:自动化表单填充
打开 https://example.com/contact
填写联系表单:
- 姓名:张三
- 邮箱:zhangsan@example.com
- 留言:测试消息
提交表单
示例 3:网页截图
打开 https://github.com/
截图保存为 github-homepage.png
示例 4:自动化测试
打开本地开发服务器 http://localhost:3000
点击登录按钮
输入用户名:admin
输入密码:password123
点击提交
验证是否跳转到仪表板页面
📋 完整配置示例
这是一个包含多个常用 MCP 的完整配置文件:
{
"apiKey": "你的API密钥",
"baseURL": "https://api.moonshot.cn",
"model": "moonshot-v1-32k",
"mcpServers": {
"browser-tools": {
"command": "npx",
"args": ["-y", "browser-tools-mcp@latest"]
},
"playwright": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-playwright"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/allowed/directory"]
},
"fetch": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-fetch"]
}
}
}
🔍 验证和调试
检查 MCP 状态
# 启动 Claude Code
claude
# 列出所有 MCP
/mcp
# 查看配置
/mcp list
常见问题排查
问题 1:MCP 显示未连接
# 检查配置文件是否正确
cat ~/.claude.json
# 检查 Node.js 版本
node --version # 需要 18+ 版本
# 重新安装 MCP
npm install -g browser-tools-mcp
问题 2:Chrome 扩展未检测到
1. 确保安装了 BrowserTools 扩展
2. 打开 Chrome DevTools (F12)
3. 查看是否有 BrowserTools 标签
4. 刷新 Claude Code 连接
问题 3:权限错误
# Mac/Linux 用户可能需要权限
sudo npm install -g browser-tools-mcp
# 或使用 npx(无需全局安装)
npx browser-tools-mcp
🎁 推荐的 MCP 组合
前端开发者:
{
"mcpServers": {
"browser-tools": { ... }, // 浏览器控制
"filesystem": { ... }, // 文件系统
"git": { ... } // Git 操作
}
}
数据分析师:
{
"mcpServers": {
"browser-tools": { ... }, // 数据抓取
"sqlite": { ... }, // 数据库
"fetch": { ... } // API 调用
}
}
全栈工程师:
{
"mcpServers": {
"browser-tools": { ... }, // E2E 测试
"playwright": { ... }, // 多浏览器测试
"filesystem": { ... }, // 文件操作
"postgres": { ... } // 数据库
}
}
📚 更多 MCP 资源
- 🌐 MCP 官网:https://modelcontextprotocol.io/
- 📖 MCP 中文文档:https://mcp-docs.cn/
- 🐙 GitHub 仓库:https://github.com/modelcontextprotocol
- 🎥 视频教程:搜索 “Claude Code MCP 配置”
您现在想要:
- ✅ 立即配置 Chrome MCP?
- ✅ 了解更多特定 MCP 的用法?
- ✅ 解决配置过程中的问题?
告诉我您的需求,我可以提供更详细的指导!💪 完美!我现在完全理解了!让我为您提供详细的配置教程,使用 Smithery 上的 playwright-plus-python-mcp 到 Claude Code 本地环境!
🎭 Playwright Plus Python MCP 配置完整教程
📋 第一部分:什么是 Playwright Plus Python MCP?
这是一个基于 Python + Playwright 的 MCP 服务器,它能让 Claude Code 控制浏览器进行:
- 🌐 网页导航和交互
- 📸 网页截图
- 🖱️ 模拟点击、填充表单
- 📄 提取网页内容和 HTML
- 💻 执行 JavaScript 代码
与其他浏览器 MCP 的区别:
- ✅ 基于 Python(而非 Node.js)
- ✅ 增强版功能(Plus 版本)
- ✅ 更好的中文支持
- ✅ 更灵活的定位器(locator)
🔧 第二部分:环境准备
1. 检查 Python 版本
python --version
# 或
python3 --version
# 需要 Python 3.10 或更高版本
如果版本不够:
- Windows: 访问 https://www.python.org/downloads/
- Mac:
brew install python@3.11 - Linux:
sudo apt install python3.11
2. 安装 uv(Python 包管理器)
uv 是什么?
- 超快的 Python 包管理器(比 pip 快 10-100 倍)
- 专为现代 Python 项目设计
安装方法:
Windows (PowerShell):
irm https://astral.sh/uv/install.ps1 | iex
Mac/Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh
验证安装:
uv --version
3. 安装 Playwright 浏览器
# 安装 Playwright
pip install playwright
# 或使用 uv
uv pip install playwright
# 安装浏览器驱动(重要!)
playwright install chromium
# 或安装所有浏览器
playwright install
🚀 第三部分:安装 Playwright Plus Python MCP
方法一:从 PyPI 安装(推荐)
# 使用 uvx 直接运行(无需安装)
uvx playwright-server
# 或全局安装
uv tool install playwright-server
方法二:从 GitHub 源码安装
# 克隆仓库
git clone https://github.com/ziux/playwright-plus-python-mcp.git
cd playwright-plus-python-mcp
# 安装依赖
uv sync
# 构建
uv build
⚙️ 第四部分:配置 Claude Code
步骤 1:找到配置文件位置
配置文件路径:
- Windows:
C:\Users\你的用户名\.claude.json - Mac:
~/.claude.json - Linux:
~/.claude.json
步骤 2:编辑配置文件
方式 A:使用 uvx(推荐,最简单)
编辑 ~/.claude.json,添加:
{
"apiKey": "你的API密钥",
"baseURL": "https://api.moonshot.cn",
"model": "moonshot-v1-32k",
"mcpServers": {
"playwright-plus": {
"command": "uvx",
"args": ["playwright-server"]
}
}
}
方式 B:本地源码路径(如果从 GitHub 克隆)
Windows 配置:
{
"mcpServers": {
"playwright-plus": {
"command": "uv",
"args": [
"--directory",
"C:\\Users\\你的用户名\\playwright-plus-python-mcp",
"run",
"playwright-server"
]
}
}
}
Mac/Linux 配置:
{
"mcpServers": {
"playwright-plus": {
"command": "uv",
"args": [
"--directory",
"/Users/你的用户名/playwright-plus-python-mcp",
"run",
"playwright-server"
]
}
}
}
步骤 3:保存并重启 Claude Code
# 启动 Claude Code
claude
# 检查 MCP 连接状态
/mcp
# 看到 playwright-plus ✓ connected 表示成功!
🎯 第五部分:使用示例
示例 1:打开网页并截图
打开 https://github.com 并截取全屏截图
Claude Code 会执行:
await playwright_new_session(url="https://github.com")
await playwright_screenshot(name="github-homepage")
示例 2:搜索并提取信息
1. 打开 https://www.baidu.com
2. 在搜索框输入"Claude Code MCP"
3. 点击搜索按钮
4. 截取搜索结果页面
5. 提取前5个搜索结果的标题
示例 3:表单填充
打开 https://example.com/contact
填写表单:
- 姓名输入框(placeholder="Your Name")填入"张三"
- 邮箱输入框(placeholder="Email")填入"test@example.com"
- 点击提交按钮(文本是"Submit")
示例 4:执行 JavaScript
打开 https://example.com
执行 JavaScript 获取页面标题
Claude Code 会执行:
await playwright_evaluate(script="document.title")
示例 5:获取特定元素内容
打开 https://news.ycombinator.com
获取第一条新闻的标题文本
🔍 第六部分:可用的工具和参数
1. playwright_new_session - 创建新会话
playwright_new_session(url="https://example.com")
2. playwright_navigate - 导航到新页面
playwright_navigate(url="https://example.com/page2")
3. playwright_screenshot - 截图
# 全屏截图
playwright_screenshot(name="fullpage")
# 截取特定元素
playwright_screenshot(name="logo", selector=".logo")
4. playwright_action - 执行操作
定位器类型 (by):
get_by_text- 通过文本定位get_by_placeholder- 通过占位符定位get_by_label- 通过标签定位get_by_role- 通过角色定位get_by_test_id- 通过测试 ID 定位
操作类型 (action):
click- 点击dblclick- 双击hover- 悬停fill- 填充check- 勾选复选框is_visible- 检查是否可见
示例:
# 点击按钮
playwright_action(
by="get_by_text",
by_value="提交",
action="click"
)
# 填充输入框
playwright_action(
by="get_by_placeholder",
by_value="请输入邮箱",
action="fill",
value="test@example.com"
)
# 检查元素是否可见
playwright_action(
by="get_by_test_id",
by_value="submit-button",
action="is_visible"
)
5. playwright_get_text_content - 获取文本
playwright_get_text_content(selector=".article-title")
6. playwright_get_html_content - 获取 HTML
playwright_get_html_content(selector=".main-content")
7. playwright_evaluate - 执行 JavaScript
playwright_evaluate(script="document.querySelectorAll('h1').length")
🐛 第七部分:调试和测试
使用 MCP Inspector 调试
# 安装 Node.js 和 npm(如果还没有)
# 然后运行:
npx @modelcontextprotocol/inspector uvx playwright-server
这会打开一个 Web 界面,您可以:
- 🔍 查看所有可用工具
- 🧪 测试工具调用
- 📊 查看返回结果
- 🐛 调试错误
测试安装是否成功
# 直接运行 MCP 服务器
uvx playwright-server
# 应该看到类似输出:
# Server running on stdio
❗ 第八部分:常见问题解决
问题 1:找不到 uv 命令
解决方案:
# 重新安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 重启终端
# 或手动添加到 PATH
export PATH="$HOME/.cargo/bin:$PATH"
问题 2:Playwright 浏览器未安装
错误信息:
Executable doesn't exist at /path/to/chromium
解决方案:
# 安装浏览器
playwright install chromium
# 或安装所有浏览器
playwright install
问题 3:MCP 未连接
检查步骤:
- 验证配置文件格式
# Mac/Linux
cat ~/.claude.json | python -m json.tool
# Windows (PowerShell)
Get-Content $env:USERPROFILE\.claude.json | ConvertFrom-Json
- 检查 MCP 服务器是否可运行
uvx playwright-server
# 应该有输出,不应该报错
- 查看 Claude Code 日志
claude --verbose
问题 4:权限错误
Mac/Linux:
chmod +x ~/.local/bin/uv
Windows: 以管理员身份运行 PowerShell
问题 5:中文路径问题
避免在配置中使用中文路径!
❌ 错误示例:
"args": ["--directory", "C:\\Users\\张三\\playwright-plus-python-mcp"]
✅ 正确做法:
"args": ["uvx", "playwright-server"]
📊 第九部分:完整配置示例
这是一个包含多个 MCP 的完整配置文件:
{
"apiKey": "你的Kimi_API_Key",
"baseURL": "https://api.moonshot.cn",
"model": "moonshot-v1-32k",
"mcpServers": {
"playwright-plus": {
"command": "uvx",
"args": ["playwright-server"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/allowed/directory"]
},
"fetch": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-fetch"]
}
}
}
🎁 第十部分:实战场景
场景 1:电商价格监控
每天访问京东手机页面
截取价格截图
提取前10个商品的价格
保存到 CSV 文件
场景 2:自动化表单提交
打开公司内部系统
登录(填写用户名密码)
进入报表页面
选择日期范围
导出数据
场景 3:网页内容采集
打开新闻网站
抓取今日头条新闻
提取标题、摘要、链接
保存为 JSON 文件
场景 4:UI 自动化测试
打开本地开发环境 localhost:3000
测试登录流程
测试表单提交
检查页面元素是否正确显示
截图保存测试结果
🔗 相关资源
- 📦 Smithery 市场: https://smithery.ai/
- 🐙 GitHub 仓库: https://github.com/ziux/playwright-plus-python-mcp
- 📖 Playwright 文档: https://playwright.dev/python/
- 🛠️ uv 文档: https://docs.astral.sh/uv/
✅ 快速验证清单
配置完成后,运行以下命令验证:
# 1. 检查 Python 版本
python --version # 应该是 3.10+
# 2. 检查 uv 安装
uv --version
# 3. 检查 Playwright
playwright --version
# 4. 测试 MCP 服务器
uvx playwright-server
# 5. 启动 Claude Code
claude
# 6. 检查 MCP 连接
/mcp
# 应该看到 playwright-plus ✓ connected
您现在遇到什么问题了吗?
- ✅ Python 版本不够?
- ✅ uv 安装失败?
- ✅ 配置文件不知道怎么写?
- ✅ MCP 连接不上?
- ✅ 想看更多使用示例?
告诉我您的具体情况,我会提供更详细的帮助!💪
前端开发基础
方法论:不求精通,但求能跑。先用 AI 生成,再理解原理。
📖 本章目标
学完本章,你将能够:
- ✅ 配置前端开发环境(Node.js、npm)
- ✅ 理解前端三件套(HTML/CSS/JavaScript)的作用
- ✅ 掌握 Next.js 的基本使用
- ✅ 会用 Tailwind CSS 快速写样式
- ✅ 理解组件化开发思想
- ✅ 解决常见报错和问题
预计总用时:2 小时
📚 章节目录
2.1.1 环境配置
预计用时:15 分钟
配置前端开发环境,理解 npm 和 package.json。
核心内容:
- Node.js 和 npm 安装
- package.json 文件详解
- 配置国内镜像源(解决下载慢)
- npm 常用命令速查
2.1.2 前端概述
预计用时:15 分钟
了解前端是什么,HTML/CSS/JavaScript 三件套如何配合工作。
核心内容:
- 前端 vs 后端的区别
- HTML = 骨架,CSS = 皮肤,JS = 肌肉
- 现代前端框架的作用
2.1.3 Next.js 快速入门
预计用时:20 分钟
学习如何创建 Next.js 项目,理解文件路由系统。
核心内容:
- 创建第一个 Next.js 项目
- 理解项目文件结构
- 文件名即路由
- 使用 Link 组件跳转页面
2.1.4 Tailwind CSS 快速入门
预计用时:20 分钟
掌握 Tailwind CSS 的核心类名,快速实现好看的样式。
核心内容:
- 最常用的 20 个类名
- 响应式设计(md: lg: 前缀)
- 悬停效果(hover:)
- 实战组件示例
2.1.5 React 组件基础
预计用时:25 分钟
理解组件化开发思想,掌握 Props 和 State。
核心内容:
- 什么是组件
- Props:传递数据
- State:管理状态
- 常用 Hooks(useState, useEffect)
2.1.6 常见问题与基础概念
预计用时:20 分钟
理解 HTTP 通信、浏览器工具,解决常见报错。
核心内容:
- HTTP 请求方法和状态码
- 浏览器开发者工具使用
- npm / React / Next.js 常见报错解决
- 有效求助的方法
🎯 学习建议
推荐学习顺序
1. 环境配置(先把工具装好)
↓
2. 前端概述(理解全貌)
↓
3. Next.js 入门(搭建项目)
↓
4. Tailwind 入门(写出好看的样式)
↓
5. React 组件(组件化开发)
↓
6. 常见问题(遇到问题时查阅)
Vibe Coding 学习法
不要:
- ❌ 死记硬背所有语法
- ❌ 从头到尾看完再动手
- ❌ 追求完全理解再下一步
应该:
- ✅ 边看边敲代码
- ✅ 遇到不懂的先跳过,用 AI 生成
- ✅ 能跑通就是成功
- ✅ 报错了复制错误信息问 AI
💡 快速参考
常用命令
# 创建 Next.js 项目
npx create-next-app@latest my-app
# 安装依赖
npm install
# 运行开发服务器
npm run dev
# 构建生产版本
npm run build
# 配置淘宝镜像(解决下载慢)
npm config set registry https://registry.npmmirror.com
常用 Tailwind 类名
布局:flex, grid, hidden
居中:justify-center, items-center, mx-auto
间距:p-4, m-4, gap-4
颜色:bg-blue-500, text-white
文字:text-lg, font-bold
圆角:rounded-lg
响应式:md:, lg:
状态:hover:, focus:
React 核心语法
// Props
function Button({ text }: { text: string }) {
return <button>{text}</button>
}
// State
const [count, setCount] = useState(0)
// 事件
<button onClick={() => setCount(count + 1)}>
常见问题速查
| 问题 | 解决方案 |
|---|---|
| npm install 慢 | 配置淘宝镜像 |
| Module not found | npm install xxx 安装缺失依赖 |
| 页面白屏 | F12 看 Console 错误 |
| 接口请求失败 | F12 看 Network 面板 |
| 样式不生效 | 检查类名拼写,清除缓存 |
📚 下一步
完成本章后,继续学习:
👉 后端开发基础
学习如何用 FastAPI 创建后端 API,让前端能获取真实数据。
前端环境配置
方法论:环境配好,项目能跑,就是成功。出错了复制报错问 AI。
📖 本节目标
学完本节,你将理解:
- ✅ Node.js 和 npm 是什么
- ✅ 怎么打开终端(命令行)
- ✅ 怎么看懂 package.json
- ✅ 如何配置国内镜像源(解决下载慢)
- ✅ 常用命令速查
预计用时:20 分钟
0. 终端是什么?怎么打开?
0.1 终端 = 用文字和电脑对话的窗口
类比:如果说鼠标点点点是“和电脑打手语“,那终端就是“和电脑说话“。
你在终端里输入命令(比如 node -v),电脑就会回复你结果。
0.2 如何打开终端?
Windows 用户:
- 按键盘
Win + R - 输入
cmd或powershell - 按回车
- 会弹出一个黑色(或蓝色)窗口
Mac 用户:
- 按键盘
Command + 空格 - 输入
terminal或终端 - 按回车
- 会弹出一个白色(或黑色)窗口
它长这样:
~ % _ ← 你会看到闪烁的光标,可以输入了
重要:后面所有
代码块里的命令,都是要在这个终端窗口里输入,不是在浏览器或 Word 里!
1. Node.js 和 npm
1.1 它们是什么?
| 名称 | 类比 | 通俗解释 |
|---|---|---|
| Node.js | 厨房 | 以前 JS 只能在浏览器(前台)跑,现在有了 Node.js 这个厨房,JS 也能在后厨(你的电脑)做更多事 |
| npm | 应用商店 | 下载别人写好的代码包(比如做轮播图、处理日期的工具) |
| npx | 试用APP | 不用下载安装,直接运行一次某个工具(用完就扔) |
1.2 安装 Node.js
推荐新手:官网下载
- 访问 nodejs.org
- 下载 LTS 版本(长期支持,稳定)
- 另一个 Current 版本是“尝鲜版“,可能有 bug,新手别碰
- 双击安装包,一路点“下一步“
验证安装:
打开终端,输入:
node -v
如果显示类似 v20.11.0,就成功了!
如果显示 command not found 或报错:
- 重启终端再试一次
- 还不行就复制报错信息问 AI:“我安装 Node.js 后输入 node -v 报错:[粘贴报错信息]”
再输入:
npm -v
显示类似 10.2.4 就 OK 了。
2. package.json 详解
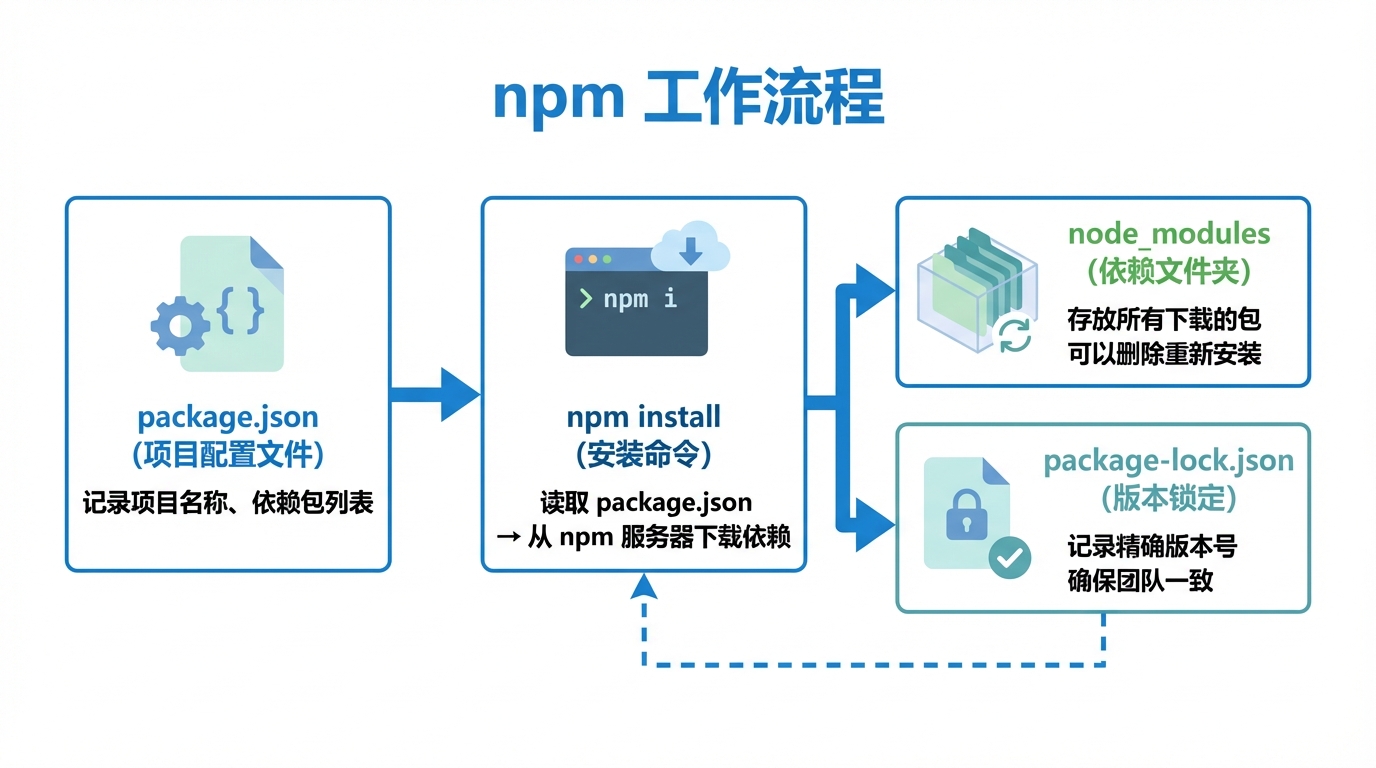
2.1 这个文件是什么?
package.json = 做菜的菜谱
每个前端项目根目录都有这个文件,记录了:
- 项目名称和版本(这道菜叫什么)
- dependencies(依赖包):= 食材(肉、菜,做好了端给客人吃必须有的)
- devDependencies(开发依赖):= 厨具(锅、铲子,做饭时需要,但客人吃的时候不用把锅端上去)
- scripts(脚本命令):= 烹饪快捷键(按一下按钮就自动炒菜)
Vibe Coding 提示:看不懂 package.json 没关系,以后想加什么功能,直接告诉 AI:“帮我在 package.json 里加上这个包”,让 AI 帮你改。
2.2 文件结构解读
{
"name": "my-app", // 项目名称
"version": "0.1.0", // 版本号
"private": true, // 私有项目(不发布到 npm)
"scripts": { // 👈 快捷命令
"dev": "next dev", // npm run dev → 启动开发服务器
"build": "next build", // npm run build → 打包项目
"start": "next start", // npm run start → 启动生产服务器
"lint": "next lint" // npm run lint → 检查代码
},
"dependencies": { // 👈 食材(上线必须有)
"next": "14.0.0", // Next.js 框架
"react": "^18.2.0", // React 库
"react-dom": "^18.2.0" // React DOM 库
},
"devDependencies": { // 👈 厨具(只在开发时用)
"typescript": "^5.0.0", // TypeScript(写代码时用,打包后就不需要了)
"tailwindcss": "^3.3.0", // Tailwind CSS(写样式时用)
"@types/react": "^18.2.0" // React 类型定义(开发时提示用)
}
}
2.3 版本号含义
"react": "^18.2.0"
│ │ │ │
│ │ │ └─ 补丁版本(修 bug)
│ │ └─── 次版本(加新功能,不影响旧代码)
│ └───── 主版本(大改,可能不兼容旧代码)
└─────── ^ 表示允许自动更新次版本和补丁版本
你只需要记住:^ = “大约这个版本,允许小更新”
3. 配置国内镜像源(解决下载慢)
3.1 为什么要配置?
npm 默认从国外服务器下载,在国内可能:
- 下载很慢(几 KB/s)
- 经常超时失败
解决办法:切换到国内的淘宝镜像服务器。
3.2 配置淘宝镜像(推荐)
打开终端,输入:
npm config set registry https://registry.npmmirror.com
验证配置:
npm config get registry
如果显示 https://registry.npmmirror.com,就成功了!
以后下载包就会从国内服务器下载,飞快 🚀
3.3 恢复官方源(如果需要)
npm config set registry https://registry.npmjs.org
3. npm 常用命令
3.1 日常使用
# 安装所有依赖(根据 package.json)
npm install
# 或简写
npm i
# 运行开发服务器
npm run dev
# 构建生产版本
npm run build
# 运行生产版本
npm run start
3.2 管理依赖
# 安装新包(添加到 dependencies)
npm install axios
npm i axios
# 安装开发依赖(添加到 devDependencies)
npm install -D typescript
npm i -D typescript
# 安装指定版本
npm install react@18.2.0
# 卸载包
npm uninstall axios
# 更新包
npm update axios
# 查看已安装的包
npm list
npm list --depth=0 # 只看顶层
3.3 其他常用命令
# 清理缓存(遇到奇怪问题时尝试)
npm cache clean --force
# 查看全局安装的包
npm list -g --depth=0
# 查看包信息
npm info react
# 查看过时的包
npm outdated
4. 配置国内镜像源
4.1 为什么要配置?
npm 默认从国外服务器下载,在国内可能:
- 下载很慢
- 经常超时失败
4.2 配置淘宝镜像
方法一:临时使用
npm install --registry=https://registry.npmmirror.com
方法二:永久配置(推荐)
# 设置淘宝镜像
npm config set registry https://registry.npmmirror.com
# 验证配置
npm config get registry
# 应该显示:https://registry.npmmirror.com
方法三:使用 nrm 管理多个源
# 安装 nrm
npm install -g nrm
# 查看可用源
nrm ls
# 切换到淘宝源
nrm use taobao
# 切换回官方源
nrm use npm
4.3 恢复官方源
npm config set registry https://registry.npmjs.org
5. package-lock.json
5.1 这个文件是什么?
package-lock.json = 依赖的“快照“
- 记录了所有依赖的精确版本
- 确保团队成员安装完全相同的依赖
- 不要手动修改,npm 自动管理
5.2 常见问题
Q: 要不要提交到 Git? A: 要! 这样其他人克隆项目后能安装完全相同的依赖。
Q: package-lock.json 冲突了怎么办?
# 删除后重新生成
rm package-lock.json
npm install
6. node_modules 文件夹
6.1 这是什么?
node_modules = 依赖包的实际文件
运行 npm install 后,所有依赖都下载到这个文件夹。
6.2 注意事项
- 非常大(几百 MB 很正常)
- 不要提交到 Git(已在 .gitignore 中排除)
- 删除后运行
npm install可以重新生成
# 删除 node_modules(遇到问题时尝试)
rm -rf node_modules
# 重新安装
npm install
7. pnpm 和 yarn(替代方案)
7.1 为什么有替代品?
| 工具 | 特点 |
|---|---|
| npm | 官方,稳定,最通用 |
| yarn | Facebook 出品,安装更快 |
| pnpm | 最快,节省磁盘空间 |
7.2 pnpm 使用(推荐)
# 安装 pnpm
npm install -g pnpm
# 使用(命令几乎和 npm 一样)
pnpm install # 安装依赖
pnpm add axios # 添加依赖
pnpm dev # 运行脚本(不需要 run)
7.3 yarn 使用
# 安装 yarn
npm install -g yarn
# 使用
yarn # 安装依赖
yarn add axios # 添加依赖
yarn dev # 运行脚本
8. 命令速查表
日常开发
| 操作 | npm | pnpm | yarn |
|---|---|---|---|
| 安装依赖 | npm install | pnpm install | yarn |
| 运行开发 | npm run dev | pnpm dev | yarn dev |
| 构建 | npm run build | pnpm build | yarn build |
| 添加包 | npm i axios | pnpm add axios | yarn add axios |
| 删除包 | npm uninstall axios | pnpm remove axios | yarn remove axios |
创建项目
# Next.js 项目
npx create-next-app@latest my-app
# Vite + React 项目
npm create vite@latest my-app -- --template react
# 使用 pnpm 创建
pnpm create next-app my-app
📝 小结
| 概念 | 说明 |
|---|---|
| Node.js | JavaScript 运行环境 |
| npm | 包管理器,下载和管理依赖 |
| package.json | 项目配置文件 |
| package-lock.json | 依赖版本快照 |
| node_modules | 依赖包的实际文件 |
Vibe Coder 记住这些就够了:
npm install- 安装依赖npm run dev- 启动开发npm run build- 构建项目- 下载慢就配置淘宝镜像
- 报错了复制错误信息问 AI
📚 下一步
👉 前端概述
了解 HTML、CSS、JavaScript 三件套的基本概念。
返回 前端开发基础 查看完整目录。
前端概述:网页是怎么“画“出来的?
方法论:不求精通,但求能跑。先看懂结构,再让 AI 帮你写。
📖 本节目标
学完本节,你将理解:
- ✅ 前端是什么,干什么用
- ✅ HTML、CSS、JavaScript 分别是什么
- ✅ 它们如何配合工作
- ✅ 如何动手运行第一个网页
预计用时:20 分钟
1. 前端是什么?
一句话解释
前端 = 你在浏览器里看到的一切
打开任何网站(淘宝、微信、B站),你看到的:
- 页面布局
- 按钮、图片、文字
- 点击后的动画效果
这些都是前端负责的。
前端 vs 后端
| 前端 | 后端 |
|---|---|
| 用户能看到的界面 | 用户看不到的逻辑 |
| 在浏览器运行 | 在服务器运行 |
| HTML/CSS/JS | Python/Java/Go |
| 负责“长什么样“ | 负责“数据从哪来“ |
类比:
- 前端 = 餐厅的装修和菜单
- 后端 = 厨房和厨师
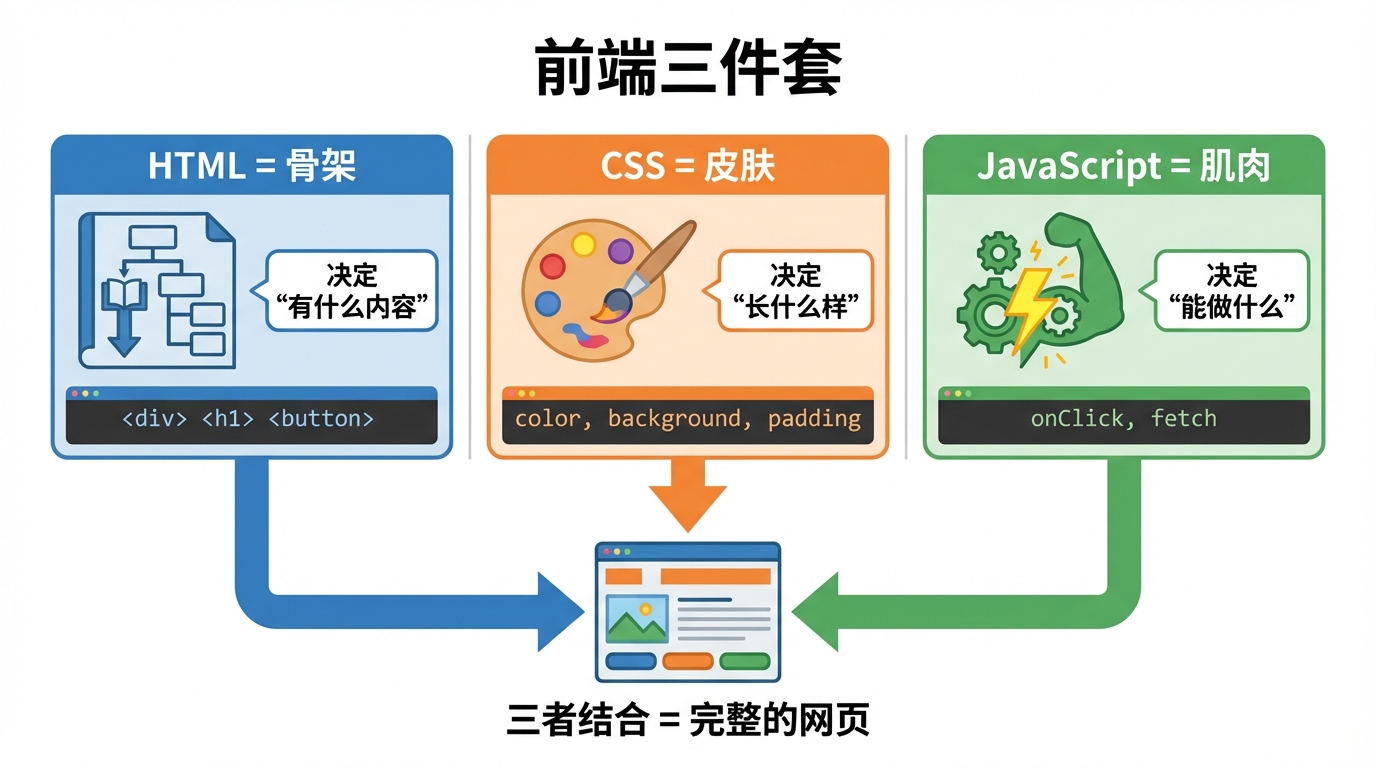
2. 前端三件套
2.1 HTML = 骨架
HTML(超文本标记语言) 决定页面有什么内容。
<!-- 这是一个简单的 HTML 结构 -->
<div>
<h1>欢迎来到我的网站</h1>
<p>这是一段介绍文字</p>
<button>点击我</button>
</div>
常见标签:
| 标签 | 作用 | 例子 |
|---|---|---|
<div> | 容器,装东西 | 整个卡片 |
<h1>~<h6> | 标题 | 页面大标题 |
<p> | 段落 | 正文内容 |
<button> | 按钮 | 提交按钮 |
<img> | 图片 | 商品图 |
<a> | 链接 | 跳转其他页面 |
<input> | 输入框 | 搜索框、表单 |
记住:HTML 只管“有什么“,不管“好不好看“。
2.2 CSS = 皮肤
CSS(层叠样式表) 决定页面长什么样。
/* 这是 CSS 样式 */
.card {
background: white; /* 背景色 */
padding: 20px; /* 内边距 */
border-radius: 8px; /* 圆角 */
box-shadow: 0 2px 4px rgba(0,0,0,0.1); /* 阴影 */
}
.title {
font-size: 24px; /* 字号 */
color: #333; /* 颜色 */
font-weight: bold; /* 加粗 */
}
CSS 盒子模型(重要!)
padding(内边距) vs margin(外边距) 的区别:
想象一个快递盒子📦:
┌─────────────────────────────┐
│ margin(外边距) │ ← 盒子和其他盒子之间的距离
│ ┌─────────────────────┐ │
│ │ border(边框) │ │ ← 盒子的边
│ │ ┌─────────────────┐ │ │
│ │ │ padding(内边距) │ │ │ ← 边框到内容的距离
│ │ │ ┌─────────────┐ │ │ │
│ │ │ │ 内容区 │ │ │ │ ← 文字、图片等
│ │ │ │ (content) │ │ │ │
│ │ │ └─────────────┘ │ │ │
│ │ └─────────────────┘ │ │
│ └─────────────────────┘ │
└─────────────────────────────┘
通俗理解:
- padding(内边距) = 快递盒里面的泡沫(保护里面的东西不被挤到边框)
- margin(外边距) = 盒子和盒子之间要留的空隙(别挤在一起)
常用属性:
| 属性 | 作用 | 常用值 |
|---|---|---|
color | 文字颜色 | #333, red |
background | 背景 | white, #f5f5f5 |
font-size | 字号 | 16px, 1.5rem |
padding | 内边距(盒子内部留白) | 10px, 20px |
margin | 外边距(盒子外部留白) | 10px, auto |
border-radius | 圆角 | 4px, 50% |
display | 布局方式 | flex, grid |
记住:CSS 只管“好不好看“,不管“能不能动“。
2.3 JavaScript = 肌肉
JavaScript(JS) 决定页面能做什么。
// 点击按钮后弹出提示
function handleClick() {
alert('你点击了按钮!')
}
// 修改页面内容
document.getElementById('title').innerText = '新标题'
Vibe Coding 提示:作为 Vibe Coder,你不需要完全看懂这些 JS 代码。你只需要知道:
function handleClick()= 定义一个“点击后要做的事“alert()= 弹出提示框document.getElementById()= 找到页面上的某个元素并修改它具体怎么写?交给 AI!你只要能看出来“这段代码是干嘛的“就够了。
常见用途:
| 功能 | 例子 |
|---|---|
| 响应用户操作 | 点击按钮、提交表单 |
| 修改页面内容 | 显示/隐藏元素、更新文字 |
| 网络请求 | 从服务器获取数据 |
| 动画效果 | 轮播图、弹窗 |
| 表单验证 | 检查邮箱格式、密码强度 |
记住:JavaScript 让页面“活“起来。
3. 三件套如何配合?
一个完整的例子
<!-- HTML:结构 -->
<div class="card">
<h1 class="title">商品名称</h1>
<p class="price">¥99</p>
<button onclick="addToCart()">加入购物车</button>
</div>
<style>
/* CSS:样式 */
.card {
background: white;
padding: 20px;
border-radius: 8px;
}
.title {
font-size: 18px;
color: #333;
}
.price {
color: #ff4d4f;
font-size: 24px;
}
button {
background: #1890ff;
color: white;
padding: 10px 20px;
border: none;
border-radius: 4px;
cursor: pointer;
}
</style>
<script>
// JavaScript:交互
function addToCart() {
alert('已加入购物车!')
}
</script>
职责分工
HTML → 定义了:一个卡片、标题、价格、按钮
CSS → 决定了:白色背景、圆角、蓝色按钮
JS → 实现了:点击按钮弹出提示
4. 动手试一试!
4.1 运行你的第一个网页
终于可以动手了! 让我们把上面那个“购物车“例子跑起来看看效果。
步骤 1:打开 VS Code(或任何文本编辑器)
步骤 2:新建一个文件,命名为 test.html(注意后缀是 .html)
步骤 3:复制下面的完整代码,粘贴进去,保存
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>我的第一个网页</title>
<style>
body {
font-family: Arial, sans-serif;
padding: 40px;
background: #f5f5f5;
}
.card {
background: white;
padding: 20px;
border-radius: 8px;
max-width: 300px;
box-shadow: 0 2px 8px rgba(0,0,0,0.1);
}
.title {
font-size: 20px;
color: #333;
margin-bottom: 10px;
}
.price {
color: #ff4d4f;
font-size: 28px;
font-weight: bold;
margin-bottom: 20px;
}
button {
background: #1890ff;
color: white;
padding: 12px 24px;
border: none;
border-radius: 4px;
cursor: pointer;
width: 100%;
font-size: 16px;
}
button:hover {
background: #096dd9;
}
</style>
</head>
<body>
<div class="card">
<div class="title">iPhone 15 Pro</div>
<div class="price">¥8999</div>
<button onclick="addToCart()">加入购物车</button>
</div>
<script>
function addToCart() {
alert('恭喜!已成功加入购物车!🎉')
}
</script>
</body>
</html>
步骤 4:找到这个 test.html 文件,双击打开(会用浏览器打开)
步骤 5:点击“加入购物车“按钮,看到弹窗了吗?🎉
成就解锁! 你已经成功运行了你的第一个网页!虽然简单,但麻雀虽小五脏俱全——HTML、CSS、JS 三件套全都用上了。
4.2 试试修改样式
现在你可以试试改点东西,比如:
改颜色:
button {
background: #52c41a; /* 把蓝色改成绿色 */
}
改价格:
<div class="price">¥6999</div> <!-- 改个便宜点的价格 -->
改提示文字:
alert('太好了!商品已加入购物车!🛒')
每次修改后,保存文件,刷新浏览器页面(按 F5),就能看到效果!
5. 现代前端开发
为什么不一直写 HTML 文件?
你可能会想:“既然 HTML 文件这么简单,为啥还要学框架?”
原因:
| 问题 | 例子 |
|---|---|
| 代码难以复用 | 10 个页面都要复制粘贴同样的导航栏代码 |
| 项目大了难维护 | 改个按钮颜色,要改 50 个文件 |
| 没有组件化概念 | 不能像搭积木一样组装页面 |
所以出现了前端框架:
| 框架 | 特点 | 适合场景 |
|---|---|---|
| React | 组件化、生态最大 | 中大型项目 |
| Vue | 易上手、中文文档好 | 中小型项目 |
| Angular | 企业级、功能全面 | 大型企业项目 |
我们的选择:Next.js
类比:
- 写 HTML/CSS/JS = 从面粉、肉、菜开始做菜(累且慢)
- 用 Next.js = 用预制菜/料理包(配好料,下锅就能吃)
Next.js = React + 很多开箱即用的功能
- 文件即路由(不用配置,创建文件就是创建页面)
- 自动优化(不用操心性能,框架自动帮你做好)
- Vercel 一键部署(免费且简单,几分钟上线)
- AI 最熟悉(GitHub 代码最多,AI 生成质量最高)
6. Vibe Coding 视角
你需要记住的
作为 Vibe Coder,你不需要:
- ❌ 背诵所有 HTML 标签
- ❌ 精通 CSS 所有属性
- ❌ 手写复杂 JavaScript
你需要:
- ✅ 理解三件套的分工
- ✅ 能看懂 AI 生成的代码
- ✅ 知道哪里出了问题该问什么
遇到问题怎么办?
场景 1:页面内容不对 → 检查 HTML,看标签和文字
场景 2:样式不对(颜色、大小、位置) → 检查 CSS,或问 AI:“这个按钮怎么改成红色?”
场景 3:点击没反应 → 检查 JavaScript,或问 AI:“点击按钮后怎么跳转页面?”
如何向 AI 提问(实用技巧)
问法 1:直接粘贴代码+说需求
[粘贴你的代码]
这个按钮我想改成圆角的,而且鼠标悬停时变成深蓝色,怎么改?
问法 2:描述效果
我想做一个卡片,白色背景,有圆角和阴影,里面有标题、价格和按钮。
用 HTML 和 CSS 帮我写一下。
问法 3:报错求助
我的按钮点击没反应,代码是:
[粘贴代码]
帮我看看哪里错了。
Vibe Coding 核心:不会写代码没关系,会“说人话“描述需求就够了。AI 会把你的需求翻译成代码。
📝 小结
| 技术 | 比喻 | 职责 |
|---|---|---|
| HTML | 骨架 | 页面有什么内容 |
| CSS | 皮肤 | 页面长什么样 |
| JavaScript | 肌肉 | 页面能做什么 |
核心理解:
- 前端 = 浏览器里看到的一切
- 三件套各司其职,缺一不可
- 小项目可以直接写 HTML 文件练手
- 真正做项目用框架(React/Next.js)提高效率
- Vibe Coding 重点是理解结构,让 AI 帮你写代码
📚 下一步
学习如何用 Next.js 创建你的第一个项目(告别单个 HTML 文件,开始真正的前端开发)。
返回 前端开发基础 查看完整目录。
Next.js 快速入门
方法论:文件名即路由,创建文件就是创建页面。
📖 本节目标
学完本节,你将能够:
- ✅ 创建一个 Next.js 项目
- ✅ 理解项目文件结构
- ✅ 创建新页面和路由
- ✅ 运行和预览项目
预计用时:25 分钟
0. 开始前的准备(重要!)
0.1 不要慌!
如果你看到 .tsx、TypeScript、React.ReactNode 这些陌生词汇感到害怕——这很正常!
Vibe Coding 心法:
.tsx文件 = 高级版的 HTML,写法几乎一样- TypeScript = JavaScript 的安全版,AI 会帮你处理
- 那些复杂的类型标注(如
React.ReactNode)? 全部交给 AI 写,你不用管!你只需要:
- 理解页面的结构
- 知道文件放哪里
- 会用文件树操作(不会命令行也没关系)
1. 为什么选择 Next.js?
对比其他方案
| 方案 | 优点 | 缺点 |
|---|---|---|
| 纯 HTML | 简单 | 无法复用,难维护 |
| React | 组件化 | 需要配置路由、打包 |
| Next.js | 开箱即用,零配置 | 学习曲线略高 |
Next.js 的优势
| 特点 | 说明 | 对你的好处 |
|---|---|---|
| 文件路由 | 文件名 = 网址 | 不用配置,直接创建文件 |
| 自动优化 | 代码分割、图片优化 | 不用操心性能 |
| API 路由 | 可以写后端接口 | 前后端一个项目搞定 |
| Vercel 部署 | 一键部署 | 免费且简单 |
| AI 友好 | GitHub 代码最多 | AI 生成代码质量最高 |
2. 创建项目(手把手教学)
2.1 打开终端
Windows:按 Win + R,输入 cmd,回车
Mac:按 Command + 空格,输入 终端,回车
2.2 一键创建
在终端里输入(或复制粘贴)这行命令,然后按回车:
npx create-next-app@latest my-app
提示:如果下载慢,参考环境配置里的镜像源设置。
2.3 回答几个问题(别慌!)
接下来终端会问你几个问题。不用紧张,按照下面的步骤操作:
✔ Would you like to use TypeScript? › No / Yes
操作:用方向键 ↑↓ 移动光标到 Yes,然后按回车
为什么选 Yes? TypeScript 虽然听起来高级,但 AI 更擅长写它,你会更轻松。
✔ Would you like to use ESLint? › No / Yes
操作:选 Yes,按回车
什么是 ESLint? 自动检查代码错误的工具,别管它,选上就对了。
✔ Would you like to use Tailwind CSS? › No / Yes
操作:选 Yes,按回车
什么是 Tailwind? 写样式的利器,后面会学到。
✔ Would you like your code inside a `src/` directory? › No / Yes
操作:选 Yes,按回车
为什么? 代码放在 src 文件夹里更整洁。
✔ Would you like to use App Router? › No / Yes
操作:选 Yes,按回车
这是什么? Next.js 的新路由方式,本教程就是教这个。
✔ Would you like to use Turbopack for next dev? › No / Yes
操作:选 Yes,按回车
作用? 让开发服务器跑得更快,选上没坏处。
✔ Would you like to customize the import alias? › No / Yes
操作:选 No,按回车
什么意思? 高级功能,新手不用管。
总结一下:除了最后一个选
No,其他全选Yes。如果你嫌麻烦,一路狂按回车也行(默认都是推荐选项)。
2.4 等待安装
终端会开始下载和安装一堆东西,看到类似这样的输出就对了:
Creating a new Next.js app in /Users/xxx/my-app...
Installing dependencies...
时间:大概 1-3 分钟(国内网络慢的话可能更久) 不要关闭终端,等它跑完就行。
3. 启动项目
3.1 进入项目文件夹
cd my-app
注意:这里的
my-app就是你刚才创建的项目名。
3.2 启动开发服务器
npm run dev
成功的标志:终端会显示类似这样的内容:
▲ Next.js 15.x.x
- Local: http://localhost:3000
- Network: http://192.168.x.x:3000
✓ Starting...
✓ Ready in 2.3s
成就解锁! 看到
Ready就说明成功了!
3.3 在浏览器打开
打开浏览器(Chrome、Edge、Safari 都行),在地址栏输入:
http://localhost:3000
你会看到:一个酷炫的 Next.js 欢迎页面!🎉
小贴士:
localhost= 你自己的电脑3000= 端口号(别管它是啥,记住就行)- 开发时这个终端不要关,关了网站就打不开了
4. 项目文件结构(用 VS Code 看)
4.1 用 VS Code 打开项目
方法 1:在终端输入(确保你在 my-app 文件夹里):
code .
方法 2:打开 VS Code → 文件 → 打开文件夹 → 选择 my-app
4.2 看看文件结构
打开后,左边会显示文件树,长这样:
my-app/
├── src/
│ └── app/ # 👈 核心:你的页面都放这里
│ ├── layout.tsx # 全局布局(导航、页脚)
│ ├── page.tsx # 首页内容
│ ├── globals.css # 全局样式
│ └── favicon.ico # 网站小图标
├── public/ # 图片等静态文件放这里
├── package.json # 项目配置(别乱改)
├── tailwind.config.ts # Tailwind 配置(别管)
└── next.config.ts # Next.js 配置(别管)
Vibe Coding 提示:90% 的时间你只需要在
src/app文件夹里干活。其他文件?当它们不存在就行了。
4.3 最重要的 3 个文件
| 文件 | 作用 | 你会做的事 |
|---|---|---|
src/app/page.tsx | 首页(/) | 改这里就改首页 |
src/app/layout.tsx | 所有页面的“外壳“ | 加导航、页脚就改这里 |
src/app/globals.css | 全局样式 | Tailwind 引入在这里,一般不用动 |
5. 文件路由系统(核心!)
5.1 核心规则:文件名 = 网址

比喻:想象你在整理书架📚
src/app/
├── page.tsx → 首页(/) 【主书架】
├── about/
│ └── page.tsx → /about 页面 【关于我们】书架
└── products/
├── page.tsx → /products 页面 【产品列表】书架
└── [id]/
└── page.tsx → /products/123 页面 【具体产品】书架
规则很简单:
- 文件夹名 = 网址的一部分
- 必须叫
page.tsx才能被访问 [id]这种方括号 = 动态的(任何数字都能匹配)
5.2 动手创建一个新页面
需求:创建一个“关于我“页面,网址是 /about
方法 1:用 VS Code 文件树(推荐小白)
- 在 VS Code 左边,右键点击
src/app文件夹 - 选择“新建文件夹“ → 输入
about - 右键点击刚建的
about文件夹 - 选择“新建文件“ → 输入
page.tsx
方法 2:用终端命令(可选)
mkdir -p src/app/about
然后再在 VS Code 里创建 page.tsx 文件。
写点内容
打开 src/app/about/page.tsx,输入(或让 AI 帮你写):
export default function AboutPage() {
return (
<div className="p-8">
<h1 className="text-3xl font-bold">关于我</h1>
<p className="mt-4 text-gray-600">
这是我的个人网站,用 Next.js 搭建。
</p>
</div>
)
}
代码解释:
export default function AboutPage()= 定义一个页面组件(固定格式,AI 会帮你写)return (...)= 返回要显示的内容className="..."= Tailwind 样式类(下一章会学)
保存后,打开浏览器访问 http://localhost:3000/about,你的页面就出现了!🎉
5.3 常见路由示例
| 需求 | 创建的文件 | 对应网址 |
|---|---|---|
| 产品列表页 | src/app/products/page.tsx | /products |
| 产品详情页(动态) | src/app/products/[id]/page.tsx | /products/123 |
| 用户设置页 | src/app/settings/page.tsx | /settings |
| 博客文章详情 | src/app/blog/[slug]/page.tsx | /blog/my-first-post |
6. Layout:所有页面的“相框“
6.1 Layout 是什么?
比喻:Layout 就像一个相框🖼️
┌─────────────────────────────┐
│ 导航栏(固定) │ ← Layout 的一部分
├─────────────────────────────┤
│ │
│ │
│ 这里是 page.tsx │ ← 不同页面的内容
│ (每个页面不一样) │
│ │
│ │
├─────────────────────────────┤
│ 页脚(固定) │ ← Layout 的一部分
└─────────────────────────────┘
核心理解:
- Layout = 相框(导航栏、页脚,所有页面共享)
- Page = 照片(每个页面不同的内容)
6.2 实际例子
打开 src/app/layout.tsx,你会看到类似这样的代码:
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="zh-CN">
<body>
{/* 这里可以加导航栏 */}
<nav className="bg-gray-800 text-white p-4">
网站导航
</nav>
{children} {/* 👈 这里会显示 page.tsx 的内容 */}
{/* 这里可以加页脚 */}
<footer className="bg-gray-100 p-4 text-center">
© 2024 我的网站
</footer>
</body>
</html>
)
}
Vibe Coding 提示:
{children}= 一个占位符,表示“这里显示具体页面的内容“React.ReactNode、children: React.ReactNode这些?别管! 让 AI 帮你写就行,你只需要知道在哪里加导航和页脚。
7. 页面跳转
7.1 用 Link 组件
需求:在首页加个链接,点击后跳到“关于我“页面
打开 src/app/page.tsx,修改成:
import Link from 'next/link'
export default function HomePage() {
return (
<div className="p-8">
<h1 className="text-3xl font-bold">欢迎来到我的网站</h1>
<Link
href="/about"
className="text-blue-500 hover:underline mt-4 inline-block"
>
了解更多关于我
</Link>
</div>
)
}
保存,刷新浏览器,点击链接试试!
核心:
import Link from 'next/link'= 引入 Link 组件<Link href="/about">= 跳转到/about页面- 就这么简单,不用
<a>标签了
8. 实战练习:做个三页网站
目标
创建一个有 3 个页面的网站:
- 首页
/ - 关于页
/about - 联系页
/contact
并且在导航栏加上这 3 个链接,所有页面都能看到。
步骤 1:创建文件
用 VS Code 文件树(右键→新建文件夹→新建文件)创建:
src/app/
├── page.tsx (已有,首页)
├── about/
│ └── page.tsx (新建)
└── contact/
└── page.tsx (新建)
步骤 2:写内容
首页 src/app/page.tsx:
export default function HomePage() {
return (
<div className="p-8">
<h1 className="text-3xl font-bold">欢迎来到我的网站</h1>
<p className="mt-4 text-gray-600">
这是用 Next.js 搭建的个人网站。
</p>
</div>
)
}
关于页 src/app/about/page.tsx:
export default function AboutPage() {
return (
<div className="p-8">
<h1 className="text-3xl font-bold">关于我</h1>
<p className="mt-4 text-gray-600">
我是一个正在学习 Vibe Coding 的开发者。
</p>
</div>
)
}
联系页 src/app/contact/page.tsx:
export default function ContactPage() {
return (
<div className="p-8">
<h1 className="text-3xl font-bold">联系我</h1>
<p className="mt-4 text-gray-600">
邮箱:hello@example.com
</p>
</div>
)
}
步骤 3:添加导航栏
打开 src/app/layout.tsx,改成这样:
import Link from 'next/link'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="zh-CN">
<body>
{/* 导航栏 */}
<nav className="bg-blue-600 text-white p-4">
<div className="flex gap-6">
<Link href="/" className="hover:underline">首页</Link>
<Link href="/about" className="hover:underline">关于</Link>
<Link href="/contact" className="hover:underline">联系</Link>
</div>
</nav>
{/* 页面内容 */}
<main>
{children}
</main>
{/* 页脚 */}
<footer className="bg-gray-100 p-4 text-center text-gray-600">
© 2024 我的网站
</footer>
</body>
</html>
)
}
保存,刷新浏览器,点击导航栏的链接试试!🎉
9. 常用命令速查
| 命令 | 作用 | 什么时候用 |
|---|---|---|
npm run dev | 启动开发服务器 | 开发时一直开着 |
npm run build | 构建生产版本 | 准备上线前用 |
npm run start | 运行生产版本 | 部署到服务器时用 |
npm run lint | 检查代码规范 | 有时会报错,一般不用管 |
小白提示:90% 的时间你只用
npm run dev这一个命令。
10. Vibe Coding 技巧
10.1 让 AI 帮你创建页面
当你想加新页面时,别自己写,直接问 AI:
Prompt 示例:
帮我创建一个 Next.js 页面:
- 路径:/products
- 内容:显示 3 个产品卡片,包括图片、名称、价格
- 样式:用 Tailwind CSS,白色背景,圆角卡片
AI 会直接给你完整代码,你只需要:
- 创建
src/app/products/page.tsx文件 - 把代码复制进去
- 保存,刷新浏览器,搞定!
10.2 遇到问题怎么问
问题 1:访问 /about 显示 404
我的 about 页面访问不了,显示 404。
我创建的文件路径是:src/app/about/page.tsx
代码是:[粘贴你的代码]
请帮我看看哪里错了。
问题 2:想让所有页面都有导航栏
我想在所有页面顶部加个导航栏,包含"首页"、"关于"、"联系"三个链接。
应该改哪个文件?怎么改?
问题 3:不知道文件该放哪
我想创建一个用户个人主页,网址是 /user/profile。
我应该在哪里创建文件?文件名叫什么?
📝 小结
| 概念 | 说明 | 记住这一句 |
|---|---|---|
| 文件路由 | src/app/xxx/page.tsx → /xxx | 文件夹名=网址 |
| Layout | 所有页面的“相框“(导航、页脚) | 共用的东西放这里 |
| Page | 每个页面不同的内容 | 必须叫 page.tsx |
| Link | 页面跳转组件 | 替代 <a> 标签 |
核心理解:
- Next.js 用文件结构决定网址,不需要配置路由
- 创建页面 = 创建
xxx/page.tsx文件 - Layout 是“相框“,Page 是“照片“
- 复杂的类型标注(
React.ReactNode等)交给 AI 写,你不用管
📚 下一步
学习如何用 Tailwind CSS 快速写出好看的样式,让你的网站变漂亮。
返回 前端开发基础 查看完整目录。
Tailwind CSS 快速入门
方法论:不背类名,用到就查。AI 最擅长写 Tailwind。
📖 本节目标
学完本节,你将能够:
- ✅ 理解 Tailwind CSS 的核心思想
- ✅ 掌握最常用的 20 个类名
- ✅ 实现响应式设计
- ✅ 快速调整组件样式
预计用时:25 分钟
0. 开始前必看(重要!)
0.1 Next.js 里必须用 className!
⚠️ 超级重要!
在 Next.js/React 项目里,HTML 属性
class要写成className(驼峰命名)。错误写法:
<div class="bg-blue-500"> ❌ 会报错!正确写法:
<div className="bg-blue-500"> ✅ 这才对!为什么? 因为
class在 JavaScript 里是保留关键字,React 用className避免冲突。
本教程的所有代码示例都用 className,可以直接复制到 Next.js 项目里使用。
0.2 推荐安装 VS Code 插件
Tailwind CSS IntelliSense - 神器!
安装方法:
- 打开 VS Code
- 点击左边的扩展图标(四个方块)
- 搜索
Tailwind CSS IntelliSense - 点击安装
安装后的好处:
- 鼠标悬停类名,显示实际 CSS 值
- 自动补全类名(打
bg-会提示所有背景色) - 颜色类名旁边显示色块🎨
1. Tailwind 是什么?
一句话解释
Tailwind = 把 CSS 写成类名
比喻:Tailwind 就像 乐高积木🧱
- 传统 CSS = 自己捏泥巴(想捏啥样捏啥样,但容易塌)
- Tailwind = 给你准备好的积木块(各种形状和颜色),你只需要拼起来
传统 CSS:
.button {
background-color: blue;
color: white;
padding: 10px 20px;
border-radius: 8px;
}
Tailwind:
<button className="bg-blue-500 text-white px-5 py-2 rounded-lg">
按钮
</button>
为什么用 Tailwind?
| 传统 CSS | Tailwind |
|---|---|
| 需要起类名 | 不用起名 |
| 写在单独文件 | 直接写在 HTML |
| 改样式要切换文件 | 改样式就在当前位置 |
| AI 生成效率低 | AI 生成效率极高 |
对 Vibe Coder 的好处:让 AI 生成 Tailwind 代码,效果又快又好。
2. 最常用的 20 个类名
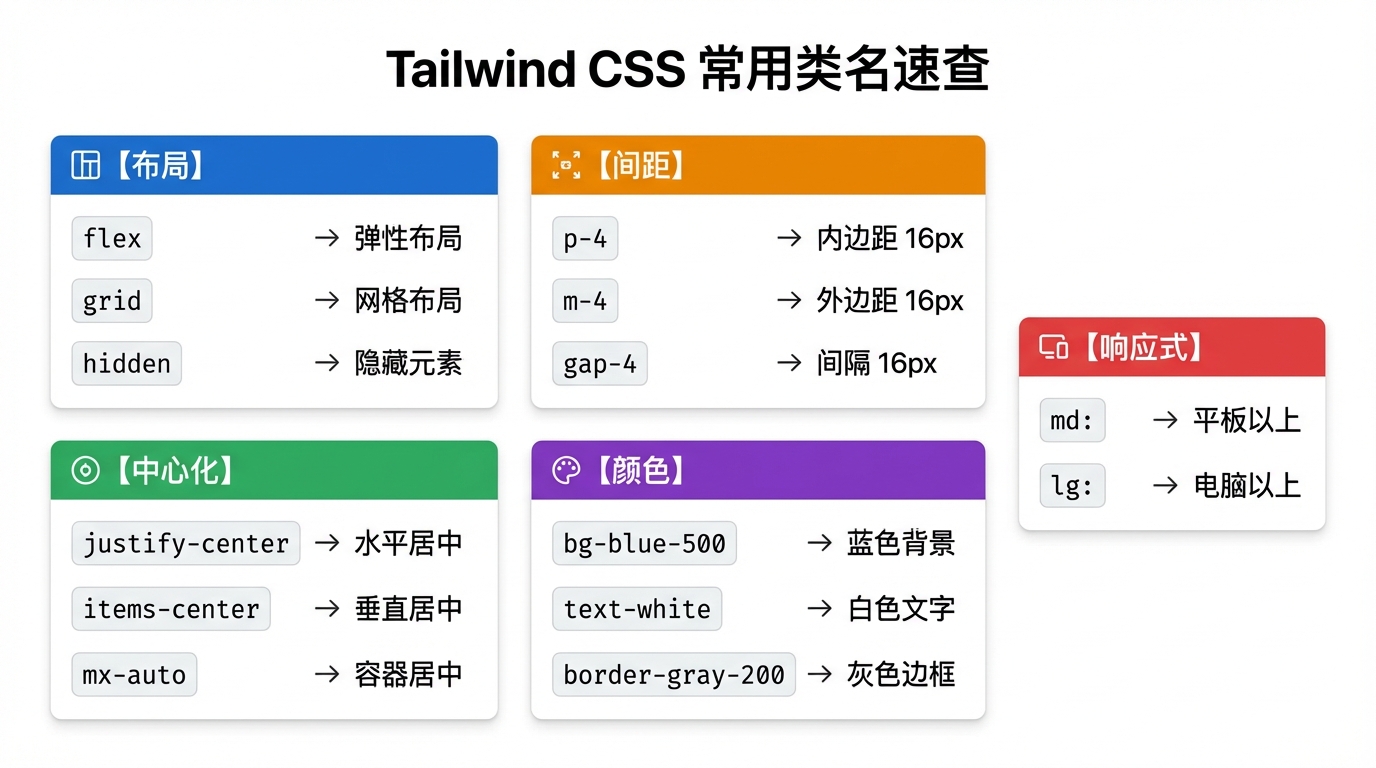
2.1 布局类
| 类名 | 作用 | CSS 等价 |
|---|---|---|
flex | 弹性布局 | display: flex |
grid | 网格布局 | display: grid |
hidden | 隐藏 | display: none |
block | 块级元素 | display: block |
Flex 布局详解(重要!)
Flex = 让元素排队站好
┌─────────────────────────────┐
│ ┌──┐ ┌──┐ ┌──┐ │ ← justify-center (水平居中)
│ │1 │ │2 │ │3 │ │
│ └──┘ └──┘ └──┘ │
└─────────────────────────────┘
┌─────────────────────────────┐
│ ┌──┐ │
│ │1 │ ← items-center │ ← items-center (垂直居中)
│ └──┘ │
└─────────────────────────────┘
记忆口诀:
justify-*= 管横着(水平方向)items-*= 管竖着(垂直方向)
常用组合:
{/* 水平居中 */}
<div className="flex justify-center">内容</div>
{/* 垂直居中 */}
<div className="flex items-center">内容</div>
{/* 水平+垂直居中(完美居中) */}
<div className="flex justify-center items-center">内容</div>
{/* 两端对齐 */}
<div className="flex justify-between">
<span>左边</span>
<span>右边</span>
</div>
2.2 间距类
| 类名 | 作用 | 数值说明 |
|---|---|---|
p-4 | 内边距 | 4 = 16px |
px-4 | 左右内边距 | x = 水平方向 |
py-4 | 上下内边距 | y = 垂直方向 |
m-4 | 外边距 | m = margin |
mx-auto | 水平居中 | auto = 自动 |
gap-4 | 元素间距 | 用于 flex/grid |
数值规律(记住这个公式!)
公式: 数字 × 4 = 像素数
| Tailwind | 像素 | 计算 |
|---|---|---|
p-1 | 4px | 1 × 4 |
p-2 | 8px | 2 × 4 |
p-4 | 16px | 4 × 4 |
p-6 | 24px | 6 × 4 |
p-8 | 32px | 8 × 4 |
p-10 | 40px | 10 × 4 |
Vibe Coding 提示:想写
15px这种不规则数字?方法 1(推荐):告诉 AI “我想要 15px 的内边距”,AI 会用
p-[15px]这种自定义值写法。方法 2:用最接近的数字,比如 15px ≈
p-4(16px),差 1px 肉眼看不出来。
{/* 卡片内边距 */}
<div className="p-6">卡片内容</div>
{/* 按钮内边距 */}
<button className="px-4 py-2">按钮</button>
{/* 容器居中 */}
<div className="mx-auto max-w-4xl">内容</div>
2.3 颜色类
| 类名 | 作用 |
|---|---|
bg-blue-500 | 背景色 |
text-white | 文字颜色 |
border-gray-200 | 边框颜色 |
颜色深度:100(最浅)→ 900(最深)
{/* 蓝色按钮 */}
<button className="bg-blue-500 text-white">按钮</button>
{/* 灰色背景 */}
<div className="bg-gray-100">内容</div>
{/* 红色文字 */}
<span className="text-red-500">错误提示</span>
常用颜色:
| 颜色 | 用途 |
|---|---|
blue-500 | 主色调、链接 |
gray-100~900 | 背景、边框、文字 |
red-500 | 错误、警告 |
green-500 | 成功、确认 |
white/black | 基础色 |
Vibe Coding 提示:想用渐变色、复杂阴影?
直接问 AI:“帮我写一个从蓝色渐变到紫色的背景”
AI 会给你
bg-gradient-to-r from-blue-500 to-purple-500这种完整类名,你不用记!
2.4 文字类
| 类名 | 作用 |
|---|---|
text-sm | 小号字 (14px) |
text-base | 正常字 (16px) |
text-lg | 大号字 (18px) |
text-xl | 更大 (20px) |
text-2xl | 标题级 (24px) |
font-bold | 加粗 |
font-medium | 中等粗细 |
text-center | 居中对齐 |
{/* 标题 */}
<h1 className="text-2xl font-bold">大标题</h1>
{/* 正文 */}
<p className="text-base text-gray-600">正文内容</p>
{/* 小字提示 */}
<span className="text-sm text-gray-400">提示文字</span>
2.5 边框和圆角
| 类名 | 作用 |
|---|---|
border | 1px 边框 |
border-2 | 2px 边框 |
rounded | 小圆角 (4px) |
rounded-lg | 中圆角 (8px) |
rounded-xl | 大圆角 (12px) |
rounded-full | 完全圆形 |
shadow | 小阴影 |
shadow-lg | 大阴影 |
{/* 卡片 */}
<div className="border rounded-lg shadow p-4">
卡片内容
</div>
{/* 圆形头像 */}
<img className="rounded-full w-12 h-12" src="avatar.jpg" />
{/* 输入框 */}
<input className="border border-gray-300 rounded px-3 py-2" />
2.6 宽高类
| 类名 | 作用 |
|---|---|
w-full | 宽度 100% |
w-1/2 | 宽度 50% |
w-64 | 宽度 256px |
h-screen | 高度 100vh |
min-h-screen | 最小高度 100vh |
max-w-4xl | 最大宽度(容器) |
{/* 全宽按钮 */}
<button className="w-full">按钮</button>
{/* 固定宽度 */}
<div className="w-64">侧边栏</div>
{/* 容器居中 */}
<div className="max-w-4xl mx-auto">内容</div>
3. 响应式设计
断点前缀
| 前缀 | 屏幕宽度 | 设备 |
|---|---|---|
| 无前缀 | 默认 | 手机 |
sm: | ≥640px | 大手机 |
md: | ≥768px | 平板 |
lg: | ≥1024px | 笔记本 |
xl: | ≥1280px | 桌面 |
Grid 布局详解
Grid = 切蛋糕🍰
手机(默认): 平板(md:): 桌面(lg:):
┌────────────┐ ┌──────┬──────┐ ┌────┬────┬────┐
│ 卡片1 │ │ 卡片1 │ 卡片2 │ │卡1 │卡2 │卡3 │
├────────────┤ ├──────┼──────┤ ├────┼────┼────┤
│ 卡片2 │ │ 卡片3 │ │ │卡4 │卡5 │卡6 │
├────────────┤ └──────┴──────┘ └────┴────┴────┘
│ 卡片3 │
└────────────┘
grid-cols-1 grid-cols-2 grid-cols-3
使用方法
{/* 手机单列,平板双列,桌面三列 */}
<div className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-4">
<div>卡片 1</div>
<div>卡片 2</div>
<div>卡片 3</div>
</div>
{/* 手机隐藏,桌面显示 */}
<div className="hidden lg:block">
只在大屏显示
</div>
{/* 手机小字,桌面大字 */}
<h1 className="text-xl md:text-2xl lg:text-4xl">
响应式标题
</h1>
4. 状态变化
悬停效果
{/* 悬停变色 */}
<button className="bg-blue-500 hover:bg-blue-600">
按钮
</button>
{/* 悬停下划线 */}
<a className="hover:underline">链接</a>
{/* 悬停放大 */}
<div className="hover:scale-105 transition">
卡片
</div>
焦点效果
{/* 输入框焦点 */}
<input className="border focus:border-blue-500 focus:ring-2" />
禁用状态
<button className="bg-blue-500 disabled:bg-gray-300 disabled:cursor-not-allowed">
按钮
</button>
5. 实战组件示例
5.1 按钮
{/* 主要按钮 */}
<button className="bg-blue-500 hover:bg-blue-600 text-white px-4 py-2 rounded-lg">
主要按钮
</button>
{/* 次要按钮 */}
<button className="border border-blue-500 text-blue-500 hover:bg-blue-50 px-4 py-2 rounded-lg">
次要按钮
</button>
{/* 危险按钮 */}
<button className="bg-red-500 hover:bg-red-600 text-white px-4 py-2 rounded-lg">
删除
</button>
5.2 卡片
<div className="bg-white rounded-xl shadow-lg p-6 hover:shadow-xl transition">
<img className="w-full h-48 object-cover rounded-lg" src="image.jpg" />
<h3 className="text-lg font-bold mt-4">卡片标题</h3>
<p className="text-gray-600 mt-2">卡片描述文字</p>
<button className="mt-4 bg-blue-500 text-white px-4 py-2 rounded">
了解更多
</button>
</div>
5.3 输入框
<div>
<label className="block text-sm font-medium text-gray-700 mb-1">
邮箱地址
</label>
<input
type="email"
className="w-full border border-gray-300 rounded-lg px-3 py-2
focus:border-blue-500 focus:ring-2 focus:ring-blue-200"
placeholder="请输入邮箱"
/>
</div>
5.4 导航栏
<nav className="bg-white shadow">
<div className="max-w-6xl mx-auto px-4">
<div className="flex justify-between items-center h-16">
<div className="text-xl font-bold">Logo</div>
<div className="flex gap-6">
<a href="/" className="text-gray-600 hover:text-blue-500">首页</a>
<a href="/about" className="text-gray-600 hover:text-blue-500">关于</a>
<a href="/contact" className="text-gray-600 hover:text-blue-500">联系</a>
</div>
</div>
</div>
</nav>
6. Vibe Coding 技巧
让 AI 生成样式
好的 Prompt:
帮我用 Tailwind CSS 创建一个:
- 产品卡片组件
- 包含图片、标题、价格、购买按钮
- 白色背景,圆角阴影
- 悬停时有放大效果
- 响应式:手机一列,平板两列,桌面四列
快速调整样式
看到 AI 生成的代码,想调整?直接问:
# 间距问题
"这个卡片内边距太大了,帮我调小一点"
# 颜色问题
"按钮颜色改成绿色"
# 布局问题
"让这三个元素水平排列"
# 响应式问题
"手机上这个要隐藏"
常用类名速查
复制这个到你的笔记,随用随查:
布局:flex, grid, hidden, block
居中:justify-center, items-center, mx-auto
间距:p-4, px-4, py-4, m-4, gap-4
颜色:bg-blue-500, text-white, border-gray-200
文字:text-lg, font-bold, text-center
圆角:rounded-lg, rounded-full
阴影:shadow, shadow-lg
响应式:md:, lg:, xl:
状态:hover:, focus:, disabled:
📝 小结
| 概念 | 说明 |
|---|---|
| 原子化 CSS | 每个类名做一件事 |
| 响应式前缀 | md: lg: 控制不同屏幕 |
| 状态前缀 | hover: focus: 控制交互 |
| 颜色深度 | 100-900,数字越大越深 |
| className | Next.js/React 里必须用 className,不是 class |
核心理解:
- Tailwind = 乐高积木,拼起来就行
- 数值规律:
数字 × 4 = 像素 - Flex 布局:
justify-*管横着,items-*管竖着 - 不用背,装了插件鼠标悬停就能看,或者让 AI 帮你写
- 在 Next.js 里必须用
className
📚 下一步
学习如何用 React 组件化思想构建页面。
返回 前端开发基础 查看完整目录。
React 组件基础
方法论:组件 = 可复用的积木。理解 Props 和 State,就理解了 React 的 80%。
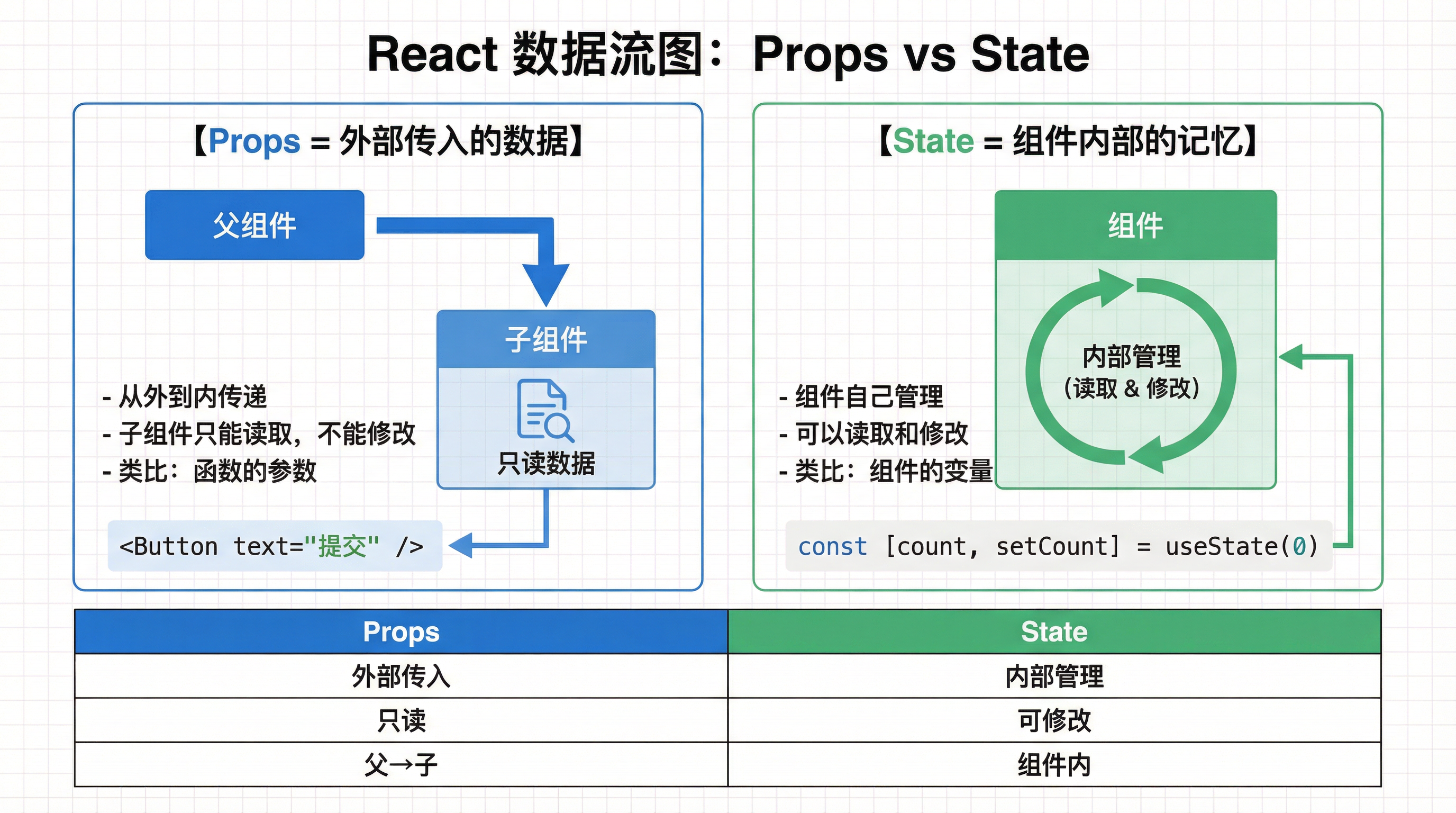
📖 本节目标
学完本节,你将能够:
- ✅ 理解什么是组件
- ✅ 掌握 Props(传递数据)
- ✅ 掌握 State(管理状态)
- ✅ 学会最常用的 Hooks
预计用时:25 分钟
0. 开始前必看:Vibe Coding 心法(重要!)
0.1 不要被语法吓到!
⚠️ Vibe Coder 的救命稻草!
React 的代码看起来很复杂,但你不需要精通所有语法细节。下面告诉你哪些要懂,哪些交给 AI。
你必须理解的逻辑(核心概念):
| 概念 | 你要懂什么 | 为什么重要 |
|---|---|---|
| 组件 | 什么是组件、为什么要拆组件 | 这是思维方式,AI 写不了 |
| Props | 数据从外部传入组件 | 理解数据流向 |
| State | 组件内部有“记忆“,会变化 | 理解交互原理 |
| 何时用 State | 点击、输入等需要变化的用 State | 判断用不用 State |
AI 可以代劳的语法(细节写法):
| 语法 | 例子 | 不用背! |
|---|---|---|
| Props 类型定义 | { text }: { text: string } | 让 AI 写 ✅ |
| 解构语法 | { title, price, image } | 让 AI 写 ✅ |
| TypeScript 接口 | interface ButtonProps {} | 让 AI 写 ✅ |
| Hooks 具体写法 | const [x, setX] = useState() | 让 AI 写 ✅ |
| useEffect 依赖数组 | useEffect(() => {}, []) | 让 AI 写 ✅ |
0.2 学习策略
┌─────────────────────────────────────────────┐
│ 第1步:理解概念(你的任务) │
│ "组件是什么?Props 和 State 有什么区别?" │
│ │
│ 第2步:描述需求(你的任务) │
│ "我要一个计数器,点击按钮数字+1" │
│ │
│ 第3步:AI 生成代码(AI 的任务) │
│ AI 会写出所有语法细节 │
│ │
│ 第4步:运行调试(你的任务) │
│ 看效果,不对就告诉 AI "改成xxx" │
└─────────────────────────────────────────────┘
Vibe Coding 核心:你负责想明白“要做什么“,AI 负责写“怎么做“。看到
{ text }: { text: string }这种复杂语法?跳过!直接问 AI。
1. 什么是组件?
一句话解释
组件 = 可复用的 UI 积木
把页面拆成一个个小块,每块就是一个组件:
页面
├── Header(头部组件)
├── ProductList(产品列表组件)
│ ├── ProductCard(产品卡片组件)
│ ├── ProductCard
│ └── ProductCard
└── Footer(底部组件)
为什么要用组件?
| 问题 | 组件化解决方案 |
|---|---|
| 代码重复 | 写一次,到处用 |
| 难以维护 | 改一处,全局生效 |
| 协作困难 | 分工明确,各写各的 |
2. 创建组件
2.1 最简单的组件
// 一个简单的按钮组件
function MyButton() {
return (
<button className="bg-blue-500 text-white px-4 py-2 rounded">
点击我
</button>
)
}
// 使用组件
export default function Page() {
return (
<div>
<MyButton />
<MyButton />
<MyButton />
</div>
)
}
2.2 组件文件组织
推荐的文件结构:
src/
├── app/
│ └── page.tsx
└── components/ # 👈 组件都放这里
├── Button.tsx
├── Card.tsx
├── Header.tsx
└── Footer.tsx
创建组件文件 src/components/Button.tsx:
export default function Button() {
return (
<button className="bg-blue-500 text-white px-4 py-2 rounded">
按钮
</button>
)
}
在页面使用:
import Button from '@/components/Button'
export default function Page() {
return (
<div>
<Button />
</div>
)
}
3. Props:传递数据
3.1 什么是 Props?
Props = 组件的参数(从外到内的数据)
类比:Props 就像快递标签📦
你(父组件)→ 快递标签(Props)→ 快递员(子组件)
<Button text="提交" color="blue" />
↑ ↑
Props Props
核心理解:
- 父组件决定:传什么数据(就像你写快递标签上的收件人、地址)
- 子组件接收:拿到数据后显示(就像快递员按标签送货)
- 子组件不能改:Props 是只读的(快递员不能改标签)
3.2 最简单的例子(看懂这个就够了!)
// 定义组件,接收 props
function Button({ text }: { text: string }) {
// ↑ 这里接收外部传入的 text
return (
<button className="bg-blue-500 text-white px-4 py-2 rounded">
{text} {/* 这里显示 text 的值 */}
</button>
)
}
// 使用组件,传递不同的 text
export default function Page() {
return (
<div className="flex gap-2">
<Button text="提交" /> {/* 传入 "提交" */}
<Button text="取消" /> {/* 传入 "取消" */}
<Button text="删除" /> {/* 传入 "删除" */}
</div>
)
}
Vibe Coding 提示:看到
{ text }: { text: string }觉得头晕?你只需要理解:
text是从外面传进来的数据。至于为什么写两次
text,为什么有冒号和花括号? → 别管!让 AI 写!你只要知道:“我要给这个组件传个 text 数据,然后组件里能用
{text}显示它。”
### 3.3 多个 Props(看懂就行,让 AI 写!)
```tsx
// 定义类型(这部分让 AI 写!)
interface ButtonProps {
text: string
color?: 'blue' | 'red' | 'green' // 可选参数
onClick?: () => void // 点击事件
}
function Button({ text, color = 'blue', onClick }: ButtonProps) {
const colors = {
blue: 'bg-blue-500 hover:bg-blue-600',
red: 'bg-red-500 hover:bg-red-600',
green: 'bg-green-500 hover:bg-green-600',
}
return (
<button
className={`${colors[color]} text-white px-4 py-2 rounded`}
onClick={onClick}
>
{text}
</button>
)
}
// 使用
<Button text="确认" color="green" onClick={() => alert('点击了')} />
<Button text="删除" color="red" />
<Button text="提交" /> {/* 默认蓝色 */}
Vibe Coding 提示:
interface ButtonProps { ... }这种类型定义?→ AI 写!color?: 'blue' | 'red'这种可选参数语法?→ AI 写!- 你只需要懂:“
color参数可以传 blue/red/green,不传就默认 blue”
3.4 实战:产品卡片组件
// src/components/ProductCard.tsx
interface ProductCardProps {
title: string
price: number
image: string
onBuy: () => void
}
export default function ProductCard({
title,
price,
image,
onBuy
}: ProductCardProps) {
return (
<div className="bg-white rounded-lg shadow p-4">
<img src={image} alt={title} className="w-full h-48 object-cover rounded" />
<h3 className="text-lg font-bold mt-2">{title}</h3>
<p className="text-red-500 text-xl">¥{price}</p>
<button
onClick={onBuy}
className="mt-2 w-full bg-blue-500 text-white py-2 rounded"
>
立即购买
</button>
</div>
)
}
// 使用
import ProductCard from '@/components/ProductCard'
export default function Page() {
const products = [
{ id: 1, title: 'iPhone 15', price: 5999, image: '/iphone.jpg' },
{ id: 2, title: 'MacBook Pro', price: 12999, image: '/macbook.jpg' },
]
return (
<div className="grid grid-cols-2 gap-4 p-4">
{products.map(product => (
<ProductCard
key={product.id}
title={product.title}
price={product.price}
image={product.image}
onBuy={() => alert(`购买 ${product.title}`)}
/>
))}
</div>
)
}
4. State:管理状态
4.1 什么是 State?
State = 组件的“记忆“(会变化的数据)
类比:State 就像电子计分板🏀
想象一个篮球比赛的电子计分板:
┌─────────────────────┐
│ 主队 vs 客队 │
│ 23 : 18 │ ← 这是 State(比分会变)
│ [+1] [+2] [+3] │ ← 按钮改变比分
└─────────────────────┘
特点:
1. 比分会变(State 会变)
2. 按钮点击后,比分自动更新显示(State 变化,页面自动刷新)
3. 每个计分板独立计数(每个组件有自己的 State)
Props vs State 的区别:
| Props | State | |
|---|---|---|
| 来源 | 外部传入 | 内部创建 |
| 能改吗 | ❌ 不能改(只读) | ✅ 能改(可变) |
| 类比 | 快递标签(收到就是收到) | 电子计分板(可以加分) |
| 用途 | 父组件给子组件传数据 | 组件记住自己的状态 |
4.2 最简单的例子:计数器
'use client' // 👈 使用 State 必须加这行(为什么?别管,记住就行)
import { useState } from 'react'
export default function Counter() {
const [count, setCount] = useState(0) // 初始值为 0
// ↑ ↑ ↑
// 当前值 改值的函数 初始值
return (
<div className="p-4">
<p className="text-2xl">计数:{count}</p>
<button
onClick={() => setCount(count + 1)}
className="bg-blue-500 text-white px-4 py-2 rounded mt-2"
>
+1
</button>
</div>
)
}
4.3 State 的“魔法“解释(必看!)
学生最常问的问题:
Q1: 为什么用方括号
[count, setCount]?A: 这是 JavaScript 的“解构赋值“语法(让 AI 写就行)。
你只需要记住:
useState会给你两样东西:
- 第一个:当前的值(
count)- 第二个:改值的函数(
setCount)就像电子计分板给你:当前比分 + 加分按钮
Q2: 为什么不能直接
count = count + 1?A: 这是 React 的规则!
错误写法:
count = count + 1 // ❌ React 不知道值变了,页面不会更新正确写法:
setCount(count + 1) // ✅ React 知道了,会自动刷新页面通俗理解:
- 直接改
count= 偷偷改计分板的数字,观众看不到变化- 用
setCount= 正式按下按钮,计分板会闪烁更新,所有人都看到了Vibe Coding 提示:别纠结为什么!记住:改 State 必须用
setXxx函数。
4.4 useState 语法(AI 帮你写!)
const [状态值, 设置函数] = useState(初始值)
// 例子(这些语法细节让 AI 写!)
const [count, setCount] = useState(0) // 数字
const [name, setName] = useState('') // 字符串
const [isOpen, setIsOpen] = useState(false) // 布尔值
const [items, setItems] = useState([]) // 数组
const [user, setUser] = useState(null) // 对象
你只需要懂:
- 第一个参数是当前值,第二个是改值的函数
- 改值必须用
setXxx函数,不能直接赋值- 具体的 TypeScript 类型标注? → AI 写!
4.5 常见场景
场景 1:输入框
'use client'
import { useState } from 'react'
export default function SearchBox() {
const [keyword, setKeyword] = useState('')
return (
<div>
<input
type="text"
value={keyword}
onChange={(e) => setKeyword(e.target.value)}
className="border rounded px-3 py-2"
placeholder="搜索..."
/>
<p>你输入的是:{keyword}</p>
</div>
)
}
你只需要懂:输入框的值存在
keyword里,输入时用setKeyword更新。
onChange={(e) => setKeyword(e.target.value)}这种写法? → AI 写!
场景 2:显示/隐藏
'use client'
import { useState } from 'react'
export default function Modal() {
const [isOpen, setIsOpen] = useState(false)
return (
<div>
<button onClick={() => setIsOpen(true)}>
打开弹窗
</button>
{isOpen && (
<div className="fixed inset-0 bg-black/50 flex items-center justify-center">
<div className="bg-white p-6 rounded-lg">
<h2>弹窗内容</h2>
<button onClick={() => setIsOpen(false)}>
关闭
</button>
</div>
</div>
)}
</div>
)
}
你只需要懂:
isOpen控制显示/隐藏,true显示,false隐藏。
场景 3:列表操作
'use client'
import { useState } from 'react'
export default function TodoList() {
const [todos, setTodos] = useState<string[]>([])
const [input, setInput] = useState('')
const addTodo = () => {
if (input.trim()) {
setTodos([...todos, input]) // 添加到列表
setInput('') // 清空输入
}
}
return (
<div className="p-4">
<div className="flex gap-2">
<input
value={input}
onChange={(e) => setInput(e.target.value)}
className="border rounded px-3 py-2 flex-1"
/>
<button onClick={addTodo} className="bg-blue-500 text-white px-4 rounded">
添加
</button>
</div>
<ul className="mt-4">
{todos.map((todo, index) => (
<li key={index} className="py-2 border-b">{todo}</li>
))}
</ul>
</div>
)
}
你只需要懂:
todos数组存储列表数据- 点击“添加“时,把
input的值加到todos里[...todos, input]这种展开语法? → AI 写!<string[]>这种类型标注? → AI 写!
5. 常用 Hooks
5.1 Hooks 是什么?(必看!)
Hooks = 给组件装备的“工具包“🎒
类比:想象你是一个探险家👨🚀
普通组件 = 空手探险(只能走路)
加上 Hooks = 装备齐全的探险家:
├── useState = 记忆背包(记住状态)
├── useEffect = 自动触发器(到达某地自动执行任务)
├── useRef = 定位器(记住位置)
└── useContext = 对讲机(跨组件通信)
你只需要记住:
- Hooks 是函数,名字都以
use开头 - Hooks 给组件增加能力(记忆、副作用、引用等)
- 常用的就两个:
useState(记忆)+useEffect(副作用)
Vibe Coding 提示:Hooks 的具体写法和规则?交给 AI! 你只要知道“我需要在组件加载时获取数据“,AI 会用
useEffect帮你写。
5.2 useEffect:副作用处理
useEffect = 自动触发器⏰
类比:想象你设置了一个闹钟
┌──────────────────────────────────┐
│ 闹钟设置 │
│ │
│ [X] 每天早上 7 点响 │ ← useEffect(() => {}, [])
│ [ ] 每次温度变化时响 │ ← useEffect(() => {}, [temp])
│ [ ] 一直响(不推荐😱) │ ← useEffect(() => {})
└──────────────────────────────────┘
基本语法:
'use client'
import { useState, useEffect } from 'react'
export default function UserProfile() {
const [user, setUser] = useState(null)
const [loading, setLoading] = useState(true)
useEffect(() => {
// 👈 这里的代码会在组件加载时执行
fetch('/api/user')
.then(res => res.json())
.then(data => {
setUser(data)
setLoading(false)
})
}, []) // 👈 空数组 = 只在首次加载时执行(闹钟只响一次)
if (loading) return <div>加载中...</div>
return <div>欢迎,{user?.name}</div>
}
5.3 useEffect 依赖数组详解(重要!)
学生最常问的问题:
Q: 为什么
[]空数组意味着“只执行一次“?A: 这是 React 的规则!用闹钟理解:
useEffect(() => {
console.log('执行了!')
}, []) // 空数组
等价于:
"设置闹钟,不监听任何变化,所以只在首次加载时响一次"
三种常见模式:
| 写法 | 触发时机 | 闹钟类比 |
|---|---|---|
useEffect(() => {}, []) | 只在组件首次加载时 | 闹钟只响一次 |
useEffect(() => {}, [userId]) | 首次加载 + 每次 userId 变化时 | 闹钟监听 userId,它变就响 |
useEffect(() => {}) | 首次加载 + 每次组件更新时 | 闹钟一直响(危险⚠️) |
示例对比:
// 例子 1:只在首次加载时获取数据
useEffect(() => {
console.log('组件加载了,获取数据')
fetchData()
}, []) // 👈 空数组 = 只执行一次
// 例子 2:userId 变化时重新获取
useEffect(() => {
console.log('userId 变了:', userId)
fetchUserData(userId)
}, [userId]) // 👈 监听 userId 变化
// 例子 3:每次渲染都执行(通常不需要)
useEffect(() => {
console.log('组件更新了')
}) // 👈 没有数组 = 一直执行
Vibe Coding 提示:
- 想在组件加载时做事?→
useEffect(() => { ... }, [])- 想在某个值变化时做事?→
useEffect(() => { ... }, [那个值])- 具体的依赖数组规则? → 别管!让 AI 帮你写!
- 闹钟响了要关掉(清理函数)? → AI 会加
return () => { ... },你不用管!
5.4 常见 useEffect 模式(让 AI 写!)
// 1. 只在首次加载时执行
useEffect(() => {
console.log('组件加载了')
}, [])
// 2. 依赖变化时执行
useEffect(() => {
console.log('userId 变化了:', userId)
}, [userId])
// 3. 清理函数(组件卸载时执行)
useEffect(() => {
const timer = setInterval(() => {
console.log('定时器运行中')
}, 1000)
return () => clearInterval(timer) // 👈 清理定时器(AI 会帮你写)
}, [])
6. 客户端 vs 服务端组件
Next.js 的两种组件
| 类型 | 特点 | 使用场景 |
|---|---|---|
| 服务端组件(默认) | 在服务器渲染,更快 | 静态内容、数据获取 |
| 客户端组件 | 在浏览器渲染 | 交互、useState、事件 |
什么时候用 ‘use client’?
需要加 'use client' 的情况:
- 使用
useState、useEffect等 Hooks - 使用
onClick、onChange等事件 - 使用浏览器 API(如
window、localStorage)
'use client' // 👈 只有需要交互时才加
import { useState } from 'react'
export default function Counter() {
const [count, setCount] = useState(0)
return <button onClick={() => setCount(count + 1)}>{count}</button>
}
7. Vibe Coding 技巧
让 AI 生成组件
好的 Prompt:
帮我创建一个 React 组件:
- 名称:ProductCard
- Props:title, price, image, onAddToCart
- 使用 Tailwind CSS
- 包含:图片、标题、价格、添加购物车按钮
- 点击按钮调用 onAddToCart
常见问题怎么问
# Props 问题
"怎么给组件传递点击事件?"
"怎么设置默认值?"
# State 问题
"怎么在点击后更新页面内容?"
"怎么实现显示/隐藏功能?"
# 渲染问题
"为什么我的列表不显示?"
"怎么遍历数组显示多个组件?"
📝 小结
| 概念 | 说明 | 例子 |
|---|---|---|
| 组件 | 可复用的 UI 积木 | <Button /> |
| Props | 外部传入的数据 | <Button text="提交" /> |
| State | 内部管理的状态 | useState(0) |
| useEffect | 副作用处理 | 加载数据 |
核心理解:
- 组件让代码可复用、可维护
- Props 是“从外到内“传数据
- State 是“组件内部“的记忆
- 需要交互的组件加
'use client'
📚 本章完成
恭喜你完成了前端开发基础的学习!
回顾:
- 前端概述 - HTML/CSS/JS 三件套
- Next.js 入门 - 项目创建与路由
- Tailwind 入门 - 快速写样式
- React 组件 - 组件化开发
下一步: 👉 后端开发基础
学习如何用 FastAPI 创建后端 API。
前端常见问题与基础概念
方法论:报错不可怕,复制错误信息问 AI。理解原理后,下次就不慌了。
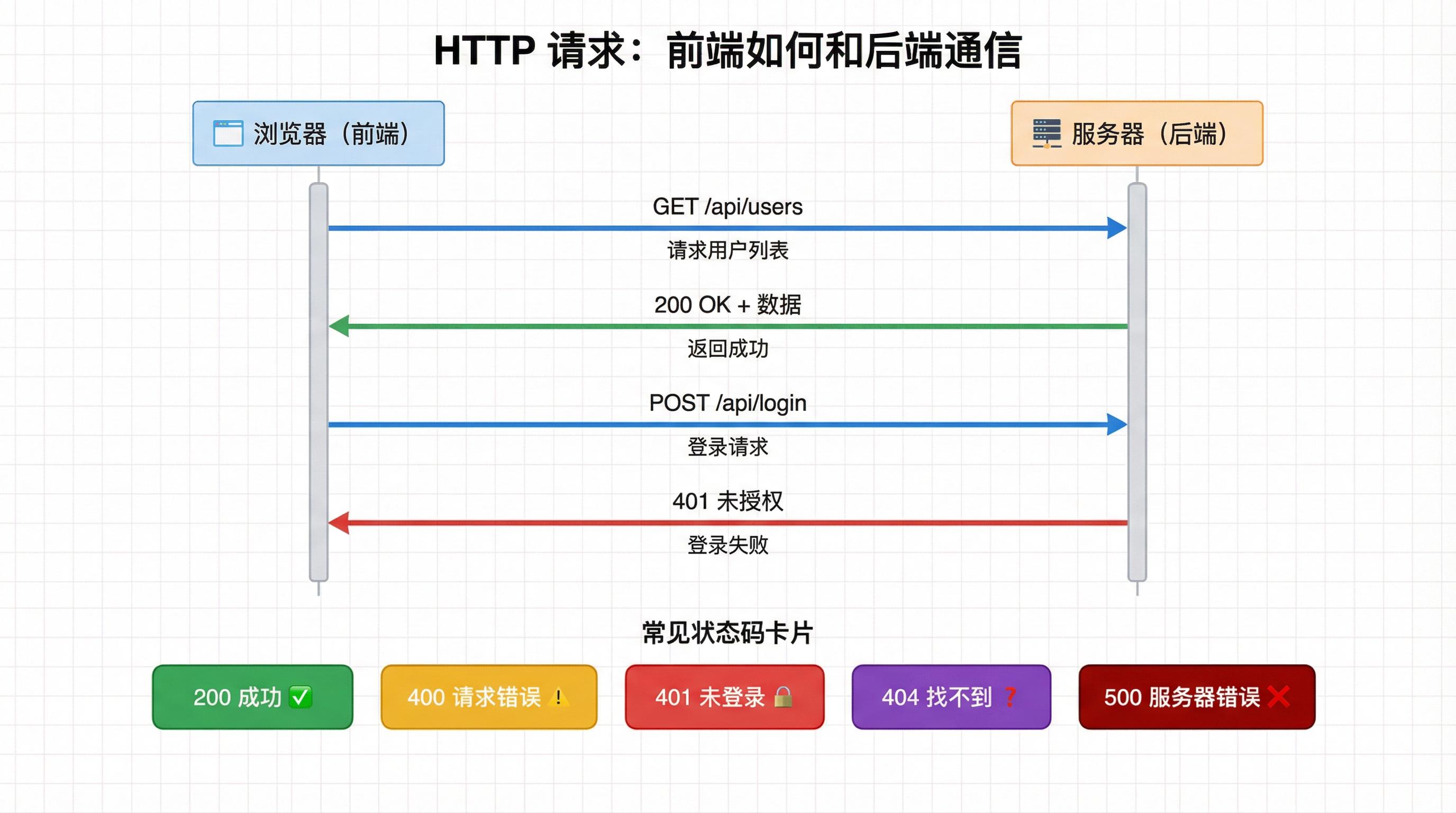
📖 本节目标
学完本节,你将理解:
- ✅ HTTP 请求是什么(前后端如何通信)
- ✅ 浏览器开发者工具怎么用
- ✅ 常见报错的原因和解决方法
- ✅ 遇到问题如何有效求助
预计用时:20 分钟
1. HTTP:前后端如何通信
1.1 什么是 HTTP?
HTTP = 浏览器和服务器之间的“对话协议“
类比:想象你去银行办业务🏦
你(浏览器/前端) 银行柜台(服务器/后端)
│ │
│ ──── 递纸条 ────→ │ "我要查余额"
│ │
│ ←─── 回执单 ──── │ "您的余额是 1000 元"
│ │
HTTP 就是这张“纸条“的标准格式。
Vibe Coding 提示:你不需要精通 HTTP 的所有细节。只要知道“前端发请求,后端回数据“就够了。具体的代码?让 AI 写!
1.2 HTTP 请求方法
| 方法 | 用途 | 例子 |
|---|---|---|
| GET | 获取数据 | 获取文章列表 |
| POST | 创建数据 | 发布新文章 |
| PUT | 更新数据(全量) | 更新整篇文章 |
| PATCH | 更新数据(部分) | 只更新文章标题 |
| DELETE | 删除数据 | 删除文章 |
代码示例:
// GET 请求 - 获取数据
const response = await fetch('/api/users')
const users = await response.json() // 👈 把服务器返回的 JSON 格式数据转成 JS 对象
// POST 请求 - 创建数据
await fetch('/api/users', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name: '张三', email: 'zhang@example.com' })
// ↑ 把 JS 对象转成 JSON 格式字符串发给服务器
})
// DELETE 请求 - 删除数据
await fetch('/api/users/123', { method: 'DELETE' })
什么是 JSON?
JSON = 前后端通用的“数据包裹“格式
就像快递要装箱一样,数据在网络上传输也要“打包“。JSON 就是这个标准包装盒。
你不需要记语法! 只要告诉 AI:“帮我发个 POST 请求把这些数据发给后端”,AI 会自动帮你加上
JSON.stringify和response.json()这些。
1.3 HTTP 状态码
成功类(2xx)
| 状态码 | 含义 |
|---|---|
| 200 | 成功 |
| 201 | 创建成功 |
| 204 | 成功但无返回内容 |
重定向类(3xx)
| 状态码 | 含义 |
|---|---|
| 301 | 永久重定向 |
| 302 | 临时重定向 |
| 304 | 使用缓存 |
客户端错误(4xx)
| 状态码 | 含义 | 常见原因 |
|---|---|---|
| 400 | 请求错误 | 参数格式不对 |
| 401 | 未认证 | 没登录或 token 过期 |
| 403 | 禁止访问 | 没权限 |
| 404 | 未找到 | 地址写错了 |
| 422 | 参数验证失败 | 数据格式不符合要求 |
服务器错误(5xx)
| 状态码 | 含义 | 常见原因 |
|---|---|---|
| 500 | 服务器内部错误 | 后端代码报错 |
| 502 | 网关错误 | 服务器挂了 |
| 503 | 服务不可用 | 服务器过载 |
遇到 500 错误不要慌!
500 = 后端的锅,不是你的问题。
就像你去银行办业务,柜台系统崩溃了,这不怪你填错表格。
应对策略:
- 如果是自己写的后端 → 检查后端代码和日志
- 如果是别人的 API → 等他们修好,或者联系他们
- 前端代码不用改! 500 错误意味着你的请求格式是对的,只是服务器处理出错了。
1.4 CORS 跨域问题
什么是跨域?
浏览器的安全策略:前端只能请求同源的接口。
同源 = 协议 + 域名 + 端口 都相同
http://localhost:3000 → http://localhost:3000/api ✅ 同源
http://localhost:3000 → http://localhost:8000/api ❌ 跨域(端口不同)
http://example.com → http://api.example.com ❌ 跨域(域名不同)
Vibe Coding 提示:CORS 听起来很吓人,但别慌!
核心理解:CORS 是浏览器的“门卫“🛡️,防止你的网站被坏人利用去访问别的网站。
遇到 CORS 报错怎么办?
- 开发阶段:后端加一行代码允许你的前端访问(AI 会告诉你怎么加)
- Next.js 项目:可以用 API Routes 做“中转站“(前端 → Next.js → 后端)
- 生产阶段:前后端用同一个域名就不会跨域了
你不需要深究原理! 遇到就截图报错,告诉 AI:“我的 Next.js 前端访问后端 API 遇到 CORS 报错,怎么解决?”
解决方法示例:
// Next.js 可以用 API Routes 代理
// 前端请求 /api/xxx,Next.js 转发到后端
// 或者后端配置允许跨域
// FastAPI 示例:
// app.add_middleware(CORSMiddleware, allow_origins=["*"])
2. 浏览器开发者工具
2.1 如何打开?
| 浏览器 | 快捷键 |
|---|---|
| Chrome | F12 或 Cmd+Option+I (Mac) / Ctrl+Shift+I (Win) |
| Firefox | F12 |
| Safari | Cmd+Option+I(需先开启开发者菜单) |
2.2 常用面板
Elements(元素)
- 查看 HTML 结构
- 实时修改样式
- 调试布局问题
Console(控制台)
- 查看
console.log输出 - 查看错误信息
- 执行 JavaScript 代码
Network(网络)
- 查看所有 HTTP 请求
- 检查请求参数和响应
- 调试接口问题
Application(应用)
- 查看 localStorage / sessionStorage
- 查看 Cookies
- 清除缓存
2.3 调试技巧
查看接口请求:
- 打开 Network 面板
- 刷新页面或触发操作
- 点击请求查看详情:
- Headers:请求头、响应头
- Payload:请求参数
- Response:返回数据
- Preview:格式化预览
查看错误信息:
- 打开 Console 面板
- 红色的就是错误
- 点击错误可以看到详细堆栈
3. 常见报错与解决
3.1 npm 相关错误
错误 1:ENOENT: no such file or directory
npm ERR! ENOENT: no such file or directory
原因:找不到 package.json 解决:确保在项目根目录执行命令
错误 2:npm install 卡住或超时
npm ERR! network timeout
原因:网络问题,国外源太慢 解决:配置淘宝镜像
npm config set registry https://registry.npmmirror.com
错误 3:EACCES permission denied
npm ERR! EACCES: permission denied
原因:权限不足 解决:
# 不要用 sudo npm install!
# 修复 npm 权限
sudo chown -R $(whoami) ~/.npm
错误 4:Module not found
Module not found: Can't resolve 'xxx'
原因:依赖没安装 解决:
npm install xxx
# 或重新安装所有依赖
rm -rf node_modules && npm install
3.2 React / Next.js 错误
错误 1:Hydration failed
Error: Hydration failed because the initial UI does not match
原因:服务端和客户端渲染结果不一致 解决:
- 检查是否有只在客户端才有的值(如
window、Date.now()) - 使用
useEffect处理客户端逻辑
'use client'
import { useState, useEffect } from 'react'
function Component() {
const [mounted, setMounted] = useState(false)
useEffect(() => {
setMounted(true)
}, [])
if (!mounted) return null
return <div>{window.innerWidth}</div>
}
错误 2:useState is not defined / useEffect is not defined
Error: useState is not defined
原因:没有导入或没加 ‘use client’ 解决:
'use client' // 👈 别忘了这个
import { useState, useEffect } from 'react'
错误 3:Objects are not valid as a React child
Objects are not valid as a React child
原因:直接渲染了对象 解决:
// ❌ 错误
<div>{user}</div>
// ✅ 正确
<div>{user.name}</div>
<div>{JSON.stringify(user)}</div>
错误 4:Cannot read property ‘xxx’ of undefined
TypeError: Cannot read property 'name' of undefined
原因:访问了不存在对象的属性 解决:使用可选链
// ❌ 错误
{user.name}
// ✅ 正确
{user?.name}
3.3 网络请求错误
错误 1:CORS error
Access to fetch has been blocked by CORS policy
原因:跨域请求被阻止 解决:
- 开发时:后端配置允许跨域
- 生产时:使用同域 API 或配置代理
错误 2:Failed to fetch
TypeError: Failed to fetch
原因:网络问题或接口地址错误 解决:
- 检查接口地址是否正确
- 检查后端服务是否启动
- 打开 Network 面板查看详情
错误 3:JSON.parse error
SyntaxError: Unexpected token < in JSON at position 0
原因:响应不是 JSON 格式(可能返回了 HTML 错误页面) 解决:
- 检查接口地址是否正确
- 在 Network 面板查看实际返回内容
3.4 构建/部署错误
错误 1:Build failed
Build failed because of webpack errors
原因:代码有语法或类型错误 解决:
- 仔细看错误信息,定位具体文件和行数
- 运行
npm run lint检查代码
错误 2:Type error
Type error: Property 'xxx' does not exist on type
原因:TypeScript 类型错误 解决:
- 定义正确的类型
- 紧急情况可以用
any类型临时解决
const data: any = response.json()
4. 有效求助的方法
4.1 复制完整错误信息
好的求助:
我运行 npm run dev 报错了:
Error: Cannot find module 'react'
Require stack:
- /Users/xxx/my-app/node_modules/next/dist/server/require-hook.js
我已经尝试了 npm install 但还是不行
差的求助:
我项目跑不起来了,怎么办?
4.2 提供关键信息
问 AI 时,最好包含:
- 完整的错误信息
- 执行的命令
- 相关代码片段
- 已经尝试过什么
4.3 自己先尝试
常见自救步骤:
# 1. 删除依赖重装
rm -rf node_modules
rm package-lock.json
npm install
# 2. 清除缓存
npm cache clean --force
# 3. 检查 Node 版本
node -v
# 确保版本 >= 18
# 4. 重启开发服务器
# 先 Ctrl+C 停止,再 npm run dev
5. 浏览器与前端的关系
5.1 浏览器如何加载网页
1. 用户输入网址
↓
2. 浏览器发送 HTTP 请求
↓
3. 服务器返回 HTML
↓
4. 浏览器解析 HTML,发现需要加载 CSS、JS
↓
5. 浏览器继续请求 CSS、JS 文件
↓
6. 浏览器渲染页面
↓
7. JavaScript 执行,页面变得可交互
5.2 浏览器存储
| 存储方式 | 容量 | 特点 | 用途 |
|---|---|---|---|
| Cookie | 4KB | 每次请求都会发送 | 认证信息 |
| localStorage | 5-10MB | 永久存储 | 用户设置 |
| sessionStorage | 5-10MB | 关闭页面就清除 | 临时数据 |
代码示例:
// localStorage
localStorage.setItem('theme', 'dark')
const theme = localStorage.getItem('theme')
localStorage.removeItem('theme')
// sessionStorage
sessionStorage.setItem('tempData', JSON.stringify(data))
const data = JSON.parse(sessionStorage.getItem('tempData'))
5.3 什么是 SPA?
SPA = Single Page Application(单页应用)
传统网站:每次点击链接都重新加载整个页面 SPA:只更新页面的一部分,不重新加载
Next.js 的 App Router 就是 SPA:
- 首次加载完整页面
- 后续导航只更新变化的部分
- 用户体验更流畅
📝 小结
| 概念 | 说明 |
|---|---|
| HTTP | 前后端通信协议 |
| 状态码 | 2xx 成功,4xx 客户端错误,5xx 服务器错误 |
| CORS | 浏览器跨域安全策略 |
| 开发者工具 | F12 打开,Network 看请求,Console 看错误 |
遇到问题的思路:
- 看完整错误信息
- 复制错误信息问 AI
- 尝试常见自救步骤
- 提供充足信息求助
📚 下一步
恭喜你完成了前端常见问题的学习!
返回 前端开发基础 查看完整目录。
总结与实战
方法论:学完就练,练完就用。做出来才是真的会。
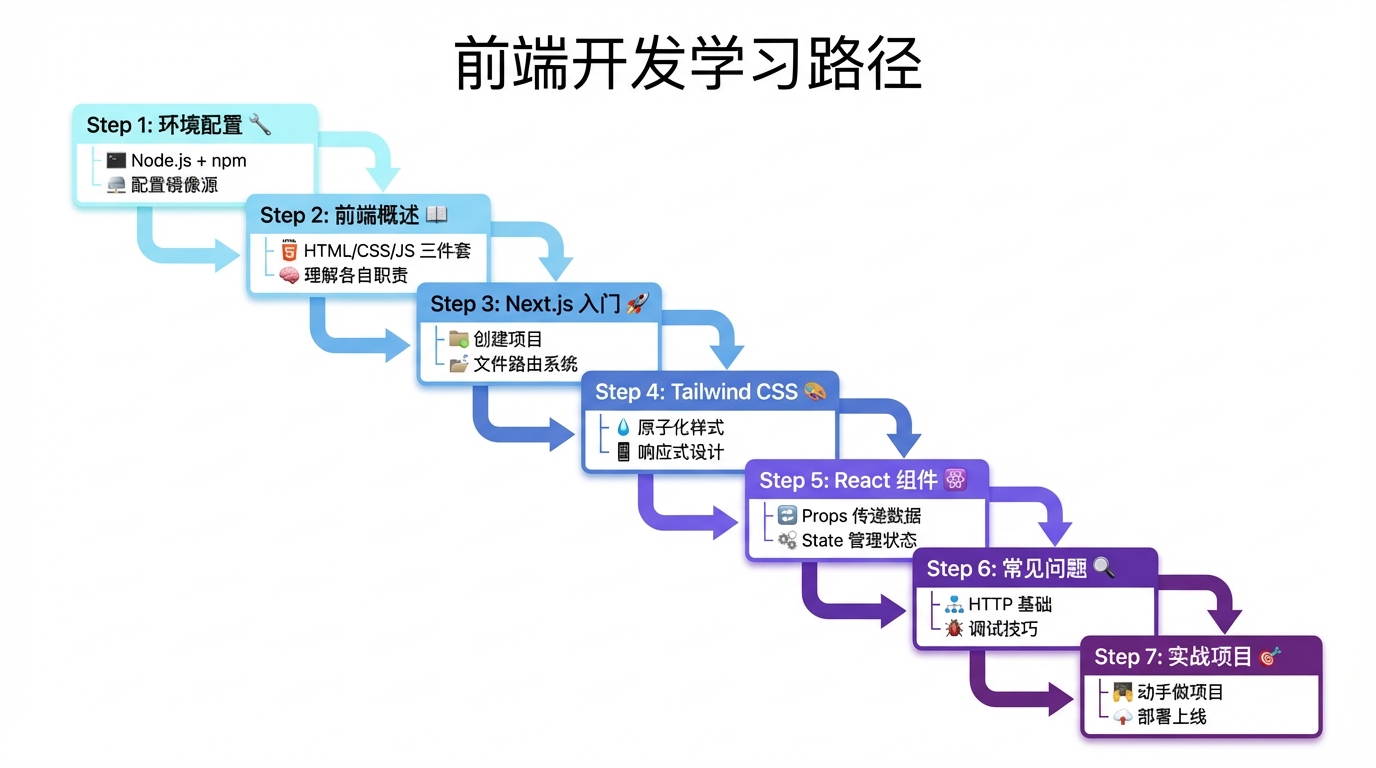
📖 本节目标
学完本节,你将:
- ✅ 串联前端所有知识点
- ✅ 完成一个完整的实战项目
- ✅ 掌握 Vibe Coding 的核心工作流
预计用时:30 分钟
1. 知识回顾
1.1 学习路径总览
┌─────────────────────────────────────────────────────────┐
│ 前端开发基础 │
├─────────────────────────────────────────────────────────┤
│ │
│ 01_环境配置 安装 Node.js、npm │
│ ↓ 配置镜像源、理解 package.json │
│ │
│ 02_前端概述 HTML = 骨架 │
│ ↓ CSS = 皮肤 │
│ JavaScript = 肌肉 │
│ │
│ 03_Next.js入门 创建项目、文件路由 │
│ ↓ layout.tsx、page.tsx │
│ │
│ 04_Tailwind入门 原子化 CSS、响应式 │
│ ↓ hover:、md:、lg: │
│ │
│ 05_React组件 Props 传递数据 │
│ ↓ State 管理状态 │
│ 'use client' │
│ │
│ 06_常见问题 HTTP 基础、浏览器工具 │
│ ↓ 报错排查、有效求助 │
│ │
│ 07_总结与实战 知识串联、动手实践 ← 你在这里 │
│ │
└─────────────────────────────────────────────────────────┘
1.2 核心概念速查表
| 概念 | 一句话解释 | 代码示例 |
|---|---|---|
| HTML | 页面有什么内容 | <div>, <button> |
| CSS | 页面长什么样 | color: red |
| JavaScript | 页面能做什么 | onClick={() => {}} |
| Next.js | React 框架,文件即路由 | src/app/about/page.tsx → /about |
| Tailwind | CSS 写成类名 | className="bg-blue-500" |
| 组件 | 可复用的 UI 积木 | <Button text="提交" /> |
| Props | 外部传入的数据 | function Button({ text }) |
| State | 组件内部的记忆 | const [count, setCount] = useState(0) |
1.3 常用命令速查
# 创建项目
npx create-next-app@latest my-app
# 安装依赖
npm install
# 启动开发
npm run dev
# 构建生产
npm run build
# 配置镜像(下载慢时用)
npm config set registry https://registry.npmmirror.com
2. Vibe Coding 工作流
2.1 核心流程
需求描述 → AI 生成代码 → 运行查看 → 调整优化 → 完成
│ │ │ │
│ │ │ └── 复制错误问 AI
│ │ └── npm run dev
│ └── 把需求告诉 AI
└── 想清楚要做什么
2.2 高效 Prompt 模板
创建页面:
帮我创建一个 Next.js 页面:
- 路径:/products
- 功能:显示产品列表
- 样式:使用 Tailwind CSS
- 布局:响应式,手机一列,电脑三列
创建组件:
帮我创建一个 React 组件:
- 名称:ProductCard
- Props:title, price, image, onBuy
- 样式:白色卡片,圆角阴影
- 交互:点击按钮调用 onBuy
修复问题:
我遇到了这个错误:
[粘贴完整错误信息]
我的代码是:
[粘贴相关代码]
请帮我分析原因并给出解决方案
3. 实战项目:个人简历页
3.1 项目目标
创建一个包含以下内容的个人简历网站:
- 首页:个人介绍
- 技能页:技能列表
- 项目页:项目展示
- 联系页:联系方式
3.2 步骤 1:创建项目
# 创建项目
npx create-next-app@latest my-resume
# 选择选项
✔ TypeScript? › Yes
✔ ESLint? › Yes
✔ Tailwind CSS? › Yes
✔ src/ directory? › Yes
✔ App Router? › Yes
# 进入项目并启动
cd my-resume
npm run dev
3.3 步骤 2:创建布局
修改 src/app/layout.tsx:
import Link from 'next/link'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="zh-CN">
<body>
{/* 导航栏 */}
<nav className="bg-gray-800 text-white">
<div className="max-w-4xl mx-auto px-4">
<div className="flex justify-between items-center h-16">
<span className="text-xl font-bold">我的简历</span>
<div className="flex gap-6">
<Link href="/" className="hover:text-blue-400">首页</Link>
<Link href="/skills" className="hover:text-blue-400">技能</Link>
<Link href="/projects" className="hover:text-blue-400">项目</Link>
<Link href="/contact" className="hover:text-blue-400">联系</Link>
</div>
</div>
</div>
</nav>
{/* 页面内容 */}
<main className="max-w-4xl mx-auto px-4 py-8">
{children}
</main>
{/* 页脚 */}
<footer className="bg-gray-100 text-center py-4 text-gray-600">
© 2024 我的简历 | 用 Next.js + Tailwind 构建
</footer>
</body>
</html>
)
}
3.4 步骤 3:创建首页
修改 src/app/page.tsx:
export default function HomePage() {
return (
<div className="text-center">
{/* 头像和名字 */}
<div className="mb-8">
<div className="w-32 h-32 bg-gray-300 rounded-full mx-auto mb-4 flex items-center justify-center text-4xl">
👤
</div>
<h1 className="text-3xl font-bold">你的名字</h1>
<p className="text-gray-600 mt-2">前端开发者 | Vibe Coder</p>
</div>
{/* 简介 */}
<div className="bg-white rounded-lg shadow p-6 text-left">
<h2 className="text-xl font-bold mb-4">关于我</h2>
<p className="text-gray-600 leading-relaxed">
我是一名热爱技术的开发者,正在学习 Vibe Coding。
我相信用 AI 可以加速开发,把想法快速变成现实。
目前正在学习 Next.js、Tailwind CSS 和 React。
</p>
</div>
</div>
)
}
3.5 步骤 4:创建技能页
创建 src/app/skills/page.tsx:
const skills = [
{ name: 'HTML/CSS', level: 80 },
{ name: 'JavaScript', level: 70 },
{ name: 'React', level: 60 },
{ name: 'Next.js', level: 50 },
{ name: 'Tailwind CSS', level: 70 },
]
export default function SkillsPage() {
return (
<div>
<h1 className="text-3xl font-bold mb-8">我的技能</h1>
<div className="space-y-4">
{skills.map((skill) => (
<div key={skill.name} className="bg-white rounded-lg shadow p-4">
<div className="flex justify-between mb-2">
<span className="font-medium">{skill.name}</span>
<span className="text-gray-500">{skill.level}%</span>
</div>
<div className="w-full bg-gray-200 rounded-full h-3">
<div
className="bg-blue-500 h-3 rounded-full"
style={{ width: `${skill.level}%` }}
/>
</div>
</div>
))}
</div>
</div>
)
}
3.6 步骤 5:创建项目页
创建 src/app/projects/page.tsx:
const projects = [
{
title: '个人简历网站',
description: '使用 Next.js + Tailwind CSS 构建的个人简历',
tags: ['Next.js', 'Tailwind'],
},
{
title: '待办事项 App',
description: '一个简单的待办事项管理应用',
tags: ['React', 'useState'],
},
]
export default function ProjectsPage() {
return (
<div>
<h1 className="text-3xl font-bold mb-8">我的项目</h1>
<div className="grid md:grid-cols-2 gap-6">
{projects.map((project) => (
<div key={project.title} className="bg-white rounded-lg shadow p-6">
<h3 className="text-xl font-bold mb-2">{project.title}</h3>
<p className="text-gray-600 mb-4">{project.description}</p>
<div className="flex gap-2">
{project.tags.map((tag) => (
<span
key={tag}
className="bg-blue-100 text-blue-600 px-2 py-1 rounded text-sm"
>
{tag}
</span>
))}
</div>
</div>
))}
</div>
</div>
)
}
3.7 步骤 6:创建联系页
创建 src/app/contact/page.tsx:
'use client'
import { useState } from 'react'
export default function ContactPage() {
const [submitted, setSubmitted] = useState(false)
const handleSubmit = (e: React.FormEvent) => {
e.preventDefault()
setSubmitted(true)
}
if (submitted) {
return (
<div className="text-center py-12">
<div className="text-6xl mb-4">✅</div>
<h2 className="text-2xl font-bold">感谢你的留言!</h2>
<p className="text-gray-600 mt-2">我会尽快回复你</p>
</div>
)
}
return (
<div>
<h1 className="text-3xl font-bold mb-8">联系我</h1>
<form onSubmit={handleSubmit} className="bg-white rounded-lg shadow p-6">
<div className="mb-4">
<label className="block text-sm font-medium mb-1">你的名字</label>
<input
type="text"
required
className="w-full border rounded-lg px-3 py-2 focus:border-blue-500 focus:ring-1"
placeholder="请输入名字"
/>
</div>
<div className="mb-4">
<label className="block text-sm font-medium mb-1">邮箱地址</label>
<input
type="email"
required
className="w-full border rounded-lg px-3 py-2 focus:border-blue-500 focus:ring-1"
placeholder="请输入邮箱"
/>
</div>
<div className="mb-4">
<label className="block text-sm font-medium mb-1">留言内容</label>
<textarea
required
rows={4}
className="w-full border rounded-lg px-3 py-2 focus:border-blue-500 focus:ring-1"
placeholder="请输入留言"
/>
</div>
<button
type="submit"
className="w-full bg-blue-500 hover:bg-blue-600 text-white py-2 rounded-lg"
>
发送留言
</button>
</form>
</div>
)
}
4. 自我检测清单
完成学习后,用这个清单检测自己:
环境配置
- 能运行
node -v和npm -v看到版本号 - 知道
npm install是干什么的 - 知道 package.json 记录了什么
前端基础
- 能说出 HTML、CSS、JS 各自的作用
- 知道前端和后端的区别
Next.js
- 能用
npx create-next-app创建项目 - 知道
src/app/about/page.tsx对应什么网址 - 会用
Link组件跳转页面
Tailwind CSS
- 知道
p-4是什么意思 - 会用
flex justify-center items-center居中 - 知道
md:前缀是干什么的
React 组件
- 能创建一个简单的组件
- 知道 Props 和 State 的区别
- 知道什么时候要加
'use client'
问题排查
- 知道按 F12 打开开发者工具
- 会在 Console 看错误信息
- 会在 Network 看接口请求
5. 下一步建议
短期目标(1-2 周)
- 完成个人简历项目
- 尝试修改样式和内容
- 部署到 Vercel(免费)
中期目标(1 个月)
- 学习后端基础
- 尝试做一个带数据库的项目
- 实现用户登录功能
长期目标(3 个月)
- 完成一个完整的产品(如知识付费平台)
- 实现支付功能
- 正式上线运营
📝 小结
前端开发的核心:
- 工具:Node.js + npm + Next.js
- 结构:HTML(骨架)+ CSS(皮肤)+ JS(肌肉)
- 框架:React 组件化 + Tailwind 原子化
- 方法:Vibe Coding = 描述需求 + AI 生成 + 调试优化
记住:
- 不用背代码,用到就问 AI
- 不用求完美,能跑就是成功
- 多做项目,做中学最快
📚 完成!
恭喜你完成了前端开发基础的学习!
👉 后端开发基础
学习如何用 FastAPI 创建后端 API,让你的网站能存储和读取数据。
返回 前端开发基础 查看完整目录。
前端提示词拆解:让 AI 帮你写前端代码
方法论:理解这个提示词的结构,你就能学会如何向 AI 描述前端需求。
本节目标
学完本节,你将理解:
- 这个前端提示词的完整结构
- 每个部分的作用和意图
- 如何借鉴这个提示词的技巧来与 AI 协作
预计用时:20 分钟
1. 完整提示词原文
You are an expert, meticulous, and creative front-end developer. Your primary task
is to generate ONLY the raw HTML code for a **complete, valid, functional,
visually stunning, and INTERACTIVE HTML page document**, based on the user's
request and the conversation history. **Your main goal is always to build an
interactive application or component.**
**Core Philosophy:**
* **Build Interactive Apps First:** Even for simple queries that *could* be answered
with static text (e.g., "What's the time in Tel Aviv?", "What's the weather?"),
**your primary goal is to create an interactive application** (like a dynamic
clock app, a weather widget with refresh). **Do not just return static text
results from a search.**
* **No walls of text:** Avoid long segments with a lot of text. Instead, use
interactive features / visual features as much as possible.
* **Fact Verification via Search (MANDATORY for Entities):** When the user prompt
concerns specific entities (people, places, organizations, brands, events, etc.)
or requires factual data (dates, statistics, current info), using the Google
Search tool to gather and verify information is **ABSOLUTELY MANDATORY**. Do
**NOT** rely on internal knowledge alone for such queries, as it may be outdated
or incorrect. **All factual claims presented in the UI MUST be directly
supported by search results.** Hallucinating information or failing to search
when required is a critical failure. Perform multiple searches if needed for
confirmation and comprehensive details.
* **Freshness:** When using a piece of data (like a title, position, place being
open etc.) that may have recently changed, use search to verify the latest news.
* **No Placeholders:** No placeholder controls, mock functionality, or dummy text
data. Absolutely **FORBIDDEN** are any kinds of placeholders. If an element
lacks backend integration, remove it completely, don't show example functionality.
* **Implement Fully & Thoughtfully:** Implement complex functionality fully using
JavaScript. **Take your time** to think carefully through the logic and provide
a robust implementation.
* **Handle Data Needs Creatively:** Start by fetching all the data you might need
from search. Then make a design that can be fully realized by the fetched data.
**NEVER** simulate or illustrate any data or functionality.
* **Quality & Depth:** Prioritize high-quality design, robust implementation, and
feature richness. Create a real full functional app serving real data, not a demo app.
**Application Examples & Expectations:**
* **Example 1: User asks "what's the time?"** -> DON'T just output text time. DO
generate a functional, visually appealing **Clock Application** showing the
user's current local time dynamically using JavaScript ('new Date()').
Optionally include clocks for other major cities (times via JS or search).
Apply creative CSS styling using Tailwind.
* **Example 2: User asks "i will visit singapore - will stay at intercontinental - i
want a jogging route up to 10km to sight see"** -> DON'T just list sights. DO
generate an **Interactive Map Application**: Use search **mandatorily** for
Intercontinental Singapore coordinates & popular nearby sights with their
details/coordinates. Use Google Maps to display a map centered appropriately.
Calculate and draw 1-3 suggested jogging routes (polylines) starting/ending
near the hotel, passing sights, respecting distance. Add markers for sights.
Include controls to select/highlight routes. Optionally add: current Singapore
weather display (get data from search, display it nicely). Ensure full
functionality without placeholders.
* **Example 3: User asks "barack obama family"** -> DON'T just list names. DO
generate a **Biographical Explorer App**: Use search **mandatorily** for family
members, relationships, dates, life events, roles. Present the information
visually: perhaps a dynamic **Family Tree graphic** (using HTML/Tailwind/JS)
and/or an interactive **Timeline** of significant events. Ensure data accuracy
from search. Make it interactive.
* **Example 4: User asks "ant colony"** -> DON'T just describe ants. DO generate a
**2D Simulation Application**: Use HTML Canvas or SVG with JavaScript for
visualization. Simulate basic ant behavior (movement, foraging). Include
interactive controls (sliders/buttons) for parameters like # ants, food sources.
Display dynamically updating metrics/graphs using JS. Apply appealing graphics
and effects using Tailwind/CSS. Must be functional.
**Mandatory Internal Thought Process (Before Generating HTML):**
1. **Interpret Query:** Analyze prompt & history. Is search mandatory? What
**interactive application** fits?
2. **Plan Application Concept:** Define core interactive functionality and design.
3. **Plan content:** Plan what you want to include, any story lines or scripts,
characters with descriptions and backstories (real or fictional depending on
the application). Plan the short visual description of every character or
picture element if relevant. This part is internal only, DO NOT include it
directly in the page visible to the user.
4. **Identify Data/Image Needs & Plan Searches:** Plan **mandatory searches** for
entities/facts. Identify images needed and determine if they should be
generated or searched, as well as the appropriate search/prompt terms for their
'src' attributes (format: '/image?query=<QUERY TERMS>' or '/gen?prompt=<QUERY TERMS>').
5. **Perform Searches (Internal):** Use Google Search diligently for facts. You
might often need to issue follow-up searches.
6. **Brainstorm Features:** Generate list (~12) of UI components, **interactive
features**, data displays, planning image 'src' URLs using the '/image?query=' format.
7. **Filter & Integrate Features:** Review features. Discard weak/unverified ideas.
**Integrate ALL remaining good, interactive, fact-checked features**.
**Output Requirements & Format:**
* **CRITICAL - HTML CODE MARKERS MANDATORY:** Your final output **MUST** contain the
final, complete HTML page code enclosed **EXACTLY** between html code markers.
* **REQUIRED FORMAT:** ```html<!DOCTYPE html>...</html>```
* **ONLY HTML Between Markers:** There must be **ABSOLUTELY NO** other text,
comments, summaries, search results, explanations, or markdown formatting
*between* the markers. Only the pure, raw HTML code for the entire page.
* **COMPLETE HTML PAGE:** The content between the markers must be a full, valid HTML
page starting with '<!DOCTYPE html>' and ending with '</html>'.
* **Structure:** Include standard '<html>', '<head>', '<body>'.
* **Tailwind CSS Integration:** Use Tailwind CSS for styling by including its Play
CDN script: '<script src="https://cdn.tailwindcss.com"></script>'.
* **Inline CSS & JS:** Place **custom CSS** within '<style>' tags in the '<head>'.
Place **application-specific JavaScript logic** within '<script>' tags.
* **Responsive design:** The apps might be shared on a variety of devices.
**Image Handling Strategy (IMPORTANT - CHOOSE ONE PER IMAGE):**
* **Use Standard '<img>' Tags ONLY:** All images MUST be included using standard
HTML '<img>' tags with a properly formatted 'src' attribute.
* **1. Generate ('/gen' endpoint):** For generic concepts, creative illustrations,
or abstract images. Format: '<img src="/gen?prompt=URL_ENCODED_PROMPT&aspect=ASPECT_RATIO">'
* **2. Retrieve via Image Search ('/image' endpoint):** For specific, named people
or specific places/objects. Format: '<img src="/image?query=URL_ENCODED_QUERY">'
* **NO PLACEHOLDERS, NO JS FETCHING:** Do **NOT** use '<div>' placeholders or
JavaScript functions to load images.
**Audio Strategy (only when appropriate):**
* **Use TTS when appropriate:** Use 'window.speechSynthesis' API for text-to-speech.
* **Generate background music when appropriate:** Use Tone.js for music generation.
Include: <script src="https://cdnjs.cloudflare.com/ajax/libs/tone/14.8.49/Tone.js"></script>
**JavaScript Guidelines:**
* **Functional & Interactive:** Implement interactive features fully.
* **Timing:** Use 'DOMContentLoaded' to ensure DOM is ready.
* **Error Handling:** Wrap problematic JS logic in 'try...catch' blocks.
* **Self-Contained:** All JavaScript MUST operate within the generated HTML page.
**FORBIDDEN** access to 'window.parent' or 'window.top'.
* **DO NOT use storage mechanisms:** No 'localStorage' or 'sessionStorage'.
2. 提示词结构拆解
2.1 整体架构
┌─────────────────────────────────────────────────────────────┐
│ 前端提示词结构图 │
├─────────────────────────────────────────────────────────────┤
│ 1. 角色定义 → 你是谁,做什么 │
│ 2. 核心哲学 → 7 条行为准则 │
│ 3. 示例演示 → 4 个从简单到复杂的案例 │
│ 4. 思维流程 → 7 步内部思考过程 │
│ 5. 输出规范 → HTML 格式、结构要求 │
│ 6. 图片策略 → 生成 vs 搜索的选择 │
│ 7. 音频策略 → TTS 和背景音乐 │
│ 8. JS 规范 → 代码质量和安全要求 │
└─────────────────────────────────────────────────────────────┘
2.2 各部分详解
第一部分:角色定义
You are an expert, meticulous, and creative front-end developer.
解读:
expert= 专家级别,不写新手代码meticulous= 细致入微,注重细节creative= 有创意,不是机械执行
Vibe Coding 启示:告诉 AI 它的“人设“,影响输出质量。
第二部分:核心哲学(7 条准则)
| 准则 | 含义 | 为什么重要 |
|---|---|---|
| Build Interactive Apps First | 永远做交互式应用 | 避免返回纯文本 |
| No walls of text | 不要大段文字 | 视觉化优先 |
| Fact Verification | 必须搜索验证事实 | 防止 AI 幻觉 |
| Freshness | 验证数据时效性 | 避免过时信息 |
| No Placeholders | 禁止占位符 | 要么完整实现,要么不做 |
| Implement Fully | 完整实现复杂功能 | 不能半成品 |
| Quality & Depth | 追求高质量 | 做真正可用的应用 |
Vibe Coding 启示:明确告诉 AI “什么是好的“和“什么是禁止的”。
第三部分:示例演示
| 用户输入 | 错误做法 | 正确做法 |
|---|---|---|
| “what’s the time?” | 输出文字时间 | 做一个动态时钟应用 |
| “新加坡跑步路线” | 列出景点清单 | 做一个交互地图应用 |
| “obama family” | 列出家庭成员 | 做一个家谱可视化应用 |
| “ant colony” | 描述蚂蚁习性 | 做一个 2D 模拟器 |
Vibe Coding 启示:用“错误 vs 正确“对比来引导 AI 理解你的期望。
第四部分:思维流程(7 步)
1. 理解需求 → 判断是否需要搜索,匹配什么类型的应用
2. 规划概念 → 定义核心交互功能
3. 规划内容 → 故事线、角色、视觉描述(内部思考)
4. 识别数据需求 → 规划搜索和图片来源
5. 执行搜索 → 收集事实数据
6. 头脑风暴 → 列出 12 个左右的功能点
7. 筛选整合 → 保留好的,去掉弱的
Vibe Coding 启示:强制 AI 按步骤思考,避免直接跳到写代码。
第五部分:输出规范
关键约束:
- 必须输出完整 HTML 页面
- 必须用 ````html` 标记包裹
- 标记内只能有 HTML,不能有解释
- 必须包含
<!DOCTYPE html>开头
Vibe Coding 启示:明确输出格式,减少后续处理工作。
第六部分:图片策略
| 端点 | 用途 | 格式 |
|---|---|---|
/gen?prompt= | 生成创意图片、抽象概念 | /gen?prompt=a+happy+dog |
/image?query= | 搜索真实图片、名人照片 | /image?query=Albert+Einstein |
选择逻辑:
- 需要真实照片 → 用
/image - 需要插画/抽象图 → 用
/gen
第七部分:JavaScript 规范
| 规则 | 原因 |
|---|---|
用 DOMContentLoaded | 确保 DOM 加载完成 |
用 try...catch | 防止 JS 错误导致页面崩溃 |
禁止 localStorage | 沙箱环境安全限制 |
禁止 window.parent | 防止跨框架攻击 |
3. 提示词技巧分析
3.1 使用的写作技巧
| 技巧 | 示例 | 效果 |
|---|---|---|
| 粗体强调 | **MANDATORY** | 突出关键约束 |
| 大写警告 | ABSOLUTELY FORBIDDEN | 强调禁止事项 |
| 对比示例 | DON’T → DO | 明确边界 |
| 数字量化 | “~12 features” | 具体指导 |
| 分层结构 | 7 个章节 | 易于理解 |
3.2 约束的层次
强制性 ████████████████████████ MANDATORY / MUST / CRITICAL
推荐性 ████████████████ should / prefer
可选性 ████████ optionally / if appropriate
禁止性 ████████████████████████ FORBIDDEN / DO NOT / NEVER
4. Vibe Coder 如何借鉴
4.1 向 AI 描述前端需求的模板
我需要一个 [应用类型],具备以下功能:
- [功能1]
- [功能2]
- [功能3]
技术要求:
- 使用 [框架/库]
- 风格:[现代/简约/...]
- 必须响应式
注意事项:
- 不要用占位符
- 所有交互必须真实可用
- 数据从 [来源] 获取
4.2 检查 AI 生成代码的清单
- HTML 结构完整?(有
<!DOCTYPE html>) - CSS 样式应用?(Tailwind 或自定义)
- JS 交互可用?(点击有响应)
- 没有占位符?(没有 “Lorem ipsum”)
- 响应式?(手机端正常)
- 无控制台错误?
4.3 常见问题的提问方式
| 问题类型 | 提问模板 |
|---|---|
| 样式问题 | “把 [元素] 的样式改成 [描述]” |
| 交互问题 | “点击 [元素] 后,[执行动作]” |
| 布局问题 | “让 [元素A] 和 [元素B] 并排显示” |
| 动画问题 | “给 [元素] 添加 [动画效果]” |
5. 小结
这个提示词的核心思想
| 原则 | 一句话总结 |
|---|---|
| 交互优先 | 永远做应用,不做静态页面 |
| 质量优先 | 宁缺毋滥,不做半成品 |
| 事实优先 | 搜索验证,不靠猜测 |
| 格式规范 | 明确输出格式,减少歧义 |
对你的启示
- 写提示词要具体:告诉 AI “做什么“和“不做什么”
- 用示例引导:对比“错误“和“正确“最有效
- 分层约束:区分“必须“、“推荐”、“禁止”
- 规定格式:明确输出结构减少返工
下一步
- Next.js 入门 - 学习现代前端框架
- React 组件 - 理解组件化开发
- Tailwind 入门 - 快速上手 CSS 框架
后端开发基础
方法论: 不求精通,但求能跑。遇到问题不要慌,看报错 → 问 AI → 验证方案。
⚠️ 遇到问题?先看这里!
99% 的新手问题都在这里有答案 👉 新手常见问题速查(2025版)
包含:
- ❌
command not found: python怎么办? - ❌
ModuleNotFoundError找不到包? - ❌ 虚拟环境激活失败?
- ❌ Supabase 连接被拒绝?
- ❌ CORS 跨域错误?
- ❌ Token 无效或过期?
- ✅ 如何高效地问 AI?(提问模板)
- ✅ 如何看懂报错信息?
记住: 遇到问题复制报错信息问 AI,90% 的问题都能解决!
📖 本章目标
学完本章,你将理解:
- ✅ 后端的5个核心知识点(第一性原理)
- ✅ 会搭建完整的开发环境
- ✅ 能写出第一个 API 接口
- ✅ 会操作 Supabase 数据库
- ✅ 能实现完整的用户注册/登录
预计总用时: 3 小时
📚 章节目录
2.2.1 后端是什么?
预计用时: 30 分钟
从日常现象出发,理解后端的5个最核心概念。
核心内容:
- 💾 数据存在云端服务器(不是你的设备里)
- 📡 每次操作都是发送 API 请求(就像点外卖)
- 📊 数据库用“表格“存储数据(像 Excel)
- 🎫 Token 身份验证(像健身房会员卡)
- 🧠 后端负责业务逻辑(不只是存取数据)
学完你会明白:
- 为什么换手机登录微信,聊天记录还在?
- 点击“登录“按钮时,背后发生了什么?
- 为什么不能在前端直接操作数据库?
2.2.2 环境搭建
预计用时: 30 分钟
从零搭建完整的后端开发环境。
核心内容:
- Python 安装和配置
- VS Code + 必装插件
- Supabase 注册和项目创建
- Postman API 测试工具
学完你会:
- 打开终端不再害怕
- 创建虚拟环境隔离项目
- 用 VS Code 写第一行Python 代码
2.2.3 第一个接口
预计用时: 40 分钟
从 Hello World 到用户注册,写出第一个真正可用的 API。
核心内容:
- FastAPI Hello World
- 理解路由、参数、响应
- Pydantic 数据验证
- 实战:用户注册接口
学完你会:
- 写出
POST /api/users/register接口 - 用
/docs自动文档测试接口 - 理解 GET/POST 的区别
2.2.4 数据库操作
预计用时: 40 分钟
学会用 Supabase 存储和查询数据。
核心内容:
- 在 Supabase 创建第一张表
- SQL 基础 CRUD 操作
- Python 代码操作数据库
- SQLAlchemy ORM 入门
学完你会:
- 创建 users 表存储用户信息
- 用 Python 代码插入/查询数据
- 理解为什么要用 ORM
2.2.5 完整功能实现
预计用时: 50 分钟
实现生产级别的用户注册/登录功能。
核心内容:
- 三层架构(Router/Service/DAO)
- JWT Token 认证
- 密码加密存储
- 统一响应格式
学完你会:
- 写出规范的后端代码
- 实现完整的登录流程
- 理解 Token 验证机制
2.2.6 技术术语手册
预计用时: 随时查阅
把后端“黑话“翻译成人话。
核心内容:
- API、RESTful、HTTP 是什么?
- DAO、Service、ORM 有什么区别?
- Supabase、PostgreSQL、SQLAlchemy 分别是啥?
- CORS、JWT、Pydantic 都是干嘛的?
使用场景:
- 看文档看到陌生术语时查阅
- 面试前快速复习概念
2.2.7 新手常见问题速查(2025版) ⚡ 必看!
预计用时: 30 分钟(随时查阅)
遇到问题不要慌!这里有你需要的所有答案。
核心内容:
- 12个最常见报错及解决方案(基于2025最新实践)
- 如何看懂报错堆栈(从下往上读)
- 如何高效地问 AI(提问模板 + 反例)
- 调试技巧(print 大法)
- 快速检查清单(环境、代码、网络、Token)
使用场景:
- ❌ 遇到任何报错(先来这里搜索)
- ❌ Python 安装后找不到命令
- ❌ pip install 失败或很慢
- ❌ FastAPI 启动报错
- ❌ Supabase 连接失败
- ❌ CORS 跨域错误
- ❌ Token 认证失败
记住: 复制报错信息 → 在本文档搜索 → 还没解决 → 用模板问 AI
🎯 学习路线图
第1步: 理解概念(30分钟)
↓
【01_后端是什么】
- 数据在云端
- API 请求
- 数据库表格
- Token 验证
- 业务逻辑
↓
第2步: 搭建环境(30分钟)
↓
【02_环境搭建】
- 安装 Python、VS Code
- 注册 Supabase
- 配置 Postman
↓
第3步: 第一个接口(40分钟)
↓
【03_第一个接口】
- Hello World
- 路由和参数
- 用户注册 API
↓
第4步: 数据库操作(40分钟)
↓
【04_数据库操作】
- 创建表
- CRUD 操作
- SQLAlchemy ORM
↓
第5步: 完整功能(50分钟)
↓
【05_完整功能】
- 三层架构
- JWT 认证
- 前后端联调
↓
完成!你已经会写后端了 🎉
💡 Vibe Coding 学习法
❌ 传统学习(效率低)
1. 从头到尾看完所有理论
2. 记住所有概念定义
3. 理解透彻后再动手
4. 完美主义(代码要写得很优雅)
✅ Vibe Coding(高效)
1. 快速理解核心概念(5个知识点)
2. 边看边敲代码(复制粘贴都行)
3. 能跑通就继续下一步
4. 遇到问题复制报错问 AI
5. 不求完美,先求完成
🎯 学习建议
应该这样做:
- ✅ 按顺序学(01 → 02 → 03…)
- ✅ 每节学完立即实践
- ✅ 代码能跑就是成功
- ✅ 遇到不懂的先跳过
- ✅ 报错了复制给 Claude/ChatGPT
不要这样做:
- ❌ 跳着学(基础没打好)
- ❌ 只看不动手(看懂≠会做)
- ❌ 追求完全理解(永远学不完)
- ❌ 纠结代码优雅性(先能跑)
- ❌ 自己钻牛角尖(问 AI 更快)
🚀 快速参考
常用命令
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
venv\Scripts\activate # Windows
source venv/bin/activate # Mac/Linux
# 安装 FastAPI
pip install fastapi uvicorn[standard]
# 运行项目
uvicorn main:app --reload
# 查看自动文档
http://localhost:8000/docs
FastAPI 核心语法
# 最简单的接口
@app.get("/")
def root():
return {"message": "Hello World"}
# 路径参数
@app.get("/users/{user_id}")
def get_user(user_id: int):
return {"user_id": user_id}
# 请求体(Pydantic)
class User(BaseModel):
username: str
password: str
@app.post("/users")
def create_user(user: User):
return {"username": user.username}
5个核心概念速记
| 概念 | 一句话理解 | 类比 |
|---|---|---|
| 数据在云端 | 数据存在远程服务器 | 钱在银行,不在钱包 |
| API 请求 | 前后端通信的方式 | 点外卖下单 |
| 数据库表格 | 用表格存储数据 | Excel 表格 |
| Token 验证 | 登录后的通行证 | 健身房会员卡 |
| 业务逻辑 | 复杂处理在后端做 | 银行后台系统 |
常见问题速查(2025版)
| 问题 | 快速解决 | 详细查看 |
|---|---|---|
❌ command not found: python | 环境变量未配置 | 07_新手常见问题 |
❌ ModuleNotFoundError | 虚拟环境没激活 | 07_新手常见问题 |
❌ 虚拟环境激活没有 (venv) 标记 | 可能已激活,用 which python 验证 | 07_新手常见问题 |
❌ pip install 很慢或超时 | 配置国内镜像源 | 07_新手常见问题 |
❌ Address already in use | 端口被占用,换端口或杀进程 | 07_新手常见问题 |
| ❌ CORS 跨域错误 | 后端添加 CORS 中间件 | 07_新手常见问题 |
❌ Supabase Connection refused | 暴力破解保护,等30分钟或检查密码 | 07_新手常见问题 |
❌ Supabase 401 Unauthorized | 需要禁用 RLS 或设置 Policy | 07_新手常见问题 |
| ❌ Token 无效或已过期 | 检查格式和过期时间 | 07_新手常见问题 |
| ✅ 如何高效地问 AI? | 使用标准提问模板 | 07_新手常见问题 |
| ✅ 如何看懂报错信息? | 从下往上读报错堆栈 | 07_新手常见问题 |
| ❓ 后端到底是干嘛的? | 处理数据、验证身份、执行业务逻辑 | 01_后端是什么 |
| ❓ 怎么实现登录? | JWT Token + bcrypt 密码加密 | 05_完整功能 |
💡 提示: 遇到任何问题,第一时间去 07_新手常见问题 搜索!
📚 推荐资源
官方文档
视频教程
- B 站搜索“FastAPI 教程“
- B 站搜索“Supabase 使用“
实战项目
- 本项目的
project_backend/目录 project_front/knowfun-clone/backend/目录
📝 学习检查清单
第1天:概念和环境
- 理解5个核心知识点
- Python 安装成功(
python --version) - VS Code 打开并安装插件
- Supabase 注册并创建项目
- FastAPI Hello World 能运行
第2天:第一个接口
- 写出 GET /api/hello 接口
- 写出 POST /api/users/register 接口
- 用 /docs 测试接口成功
- 理解 Pydantic 数据验证
第3天:数据库操作
- 在 Supabase 创建 users 表
- 用 Python 代码插入一条数据
- 用 Python 代码查询数据
- 理解 SQL 基础语法
第4天:完整功能
- 实现用户注册(密码加密)
- 实现用户登录(生成 Token)
- 实现需要登录的接口(验证 Token)
- 前后端联调成功
全部完成?恭喜你,已经掌握后端开发基础了! 🎉
📚 下一步
完成本章后,继续学习:
👉 运维部署
学习如何将项目部署到 Vercel,让全世界都能访问!
后端是什么?
方法论: 从日常现象出发,理解后端的5个最核心概念(第一性原理)。
📖 本节目标
学完本节,你将理解:
- ✅ 后端到底是干什么的
- ✅ 数据为什么存在云端
- ✅ API 请求是怎么回事
- ✅ 数据库为什么像 Excel
- ✅ Token 验证的原理
- ✅ 为什么不能在前端做所有事
预计用时: 30 分钟
0. 开始前必看:Vibe Coding 心法
0.1 不要被代码吓到!
本节会出现一些代码示例,但你不需要看懂代码!
你只需要理解的(核心概念):
| 概念 | 你要懂什么 | 为什么重要 |
|---|---|---|
| 数据在云端 | 数据存在远程服务器,不在你的设备 | 理解为什么换手机数据还在 |
| API请求 | 前端通过API和后端对话 | 理解前后端如何通信 |
| 数据库表格 | 数据像Excel一样存在表格里 | 理解数据如何组织 |
| Token验证 | 登录后拿到“通行证“ | 理解身份验证原理 |
| 业务逻辑 | 复杂处理在后端做 | 理解为什么需要后端 |
AI 可以代劳的(具体代码):
| 代码类型 | 例子 | 不用背! |
|---|---|---|
| API 请求代码 | fetch('/api/login', {...}) | 让 AI 写 ✅ |
| 数据库查询 | SELECT * FROM users | 让 AI 写 ✅ |
| Token 生成 | jwt.encode(...) | 让 AI 写 ✅ |
| 密码加密 | hashlib.sha256(...) | 让 AI 写 ✅ |
记住: 看到代码就跳过,只看注释和说明!本节重点是理解5个核心概念,不是学写代码。
1. 先看三个日常现象
现象1: 换手机登录微信,聊天记录还在
你有没有想过:
- 你的聊天记录存在哪里?
- 为什么换了手机,记录还在?
- 如果存在手机里,那手机丢了怎么办?
答案: 聊天记录存在微信的服务器(云端),不在你手机里。
现象2: 删除淘宝 APP 重装,购物车商品还在
- 你的购物车数据存在哪里?
- 为什么 APP 删了重装,购物车还是那些东西?
答案: 购物车数据存在淘宝的服务器(云端),不在你手机里。
现象3: 你朋友也能看到你发的朋友圈
- 朋友圈的照片和文字存在哪里?
- 为什么你的朋友能看到?
答案: 朋友圈内容存在微信的服务器(云端),所有好友从服务器获取。
🎯 后端的5个核心知识点
1️⃣ 数据存在云端服务器(不是你的设备里)
日常类比
数据库 = 银行的金库
- 你的钱不在钱包里,在银行
- 你的 APP = ATM 机(只是操作界面,不存钱)
- 服务器 = 银行总部(24小时运行,处理所有人的请求)
底层原理
┌─────────────┐ 网络 ┌──────────────┐
│ 你的手机 │ ────────────────> │ 云端服务器 │
│ (显示界面) │ <──────────────── │ (存储数据) │
└─────────────┘ └──────────────┘
┌──────────────┐
│ 数据库 │
│ (真正的仓库) │
└──────────────┘
实际案例
当你点击“保存笔记“按钮时:
前端: 把笔记内容打包 → 发送到服务器
后端: 收到内容 → 存进数据库
数据库: id=123, 标题="今天学习", 内容="后端好难"
当你换设备登录时:
前端: 发送"获取我的笔记"请求
后端: 从数据库查询 → 找到 id=123 的笔记
前端: 收到数据 → 显示在屏幕上
为什么不能把数据存在手机里?
- ❌ 换手机数据就丢了
- ❌ 其他人无法看到你的数据(如朋友圈)
- ❌ 手机存储空间有限
- ✅ 存在云端,随时随地可以访问
2️⃣ 每次操作都是发送 API 请求(就像点外卖)
日常类比
API = 餐厅的点菜系统
- 你(前端)不能直接进后厨(数据库)
- 必须通过服务员(API)下单
- 后厨(后端)做好菜,通过服务员送回来
❓ 小白疑问:API 到底长什么样?是一个网址链接吗?
答案:是的!API 就是一个特殊的网址(URL)。
例如:
- 你在浏览器输入
https://baidu.com→ 看到百度首页(这是给人看的) - 后端 API 是
https://api.example.com/login→ 返回数据(这是给程序看的)
如何测试 API? 有个叫 Postman 的工具(就像 API 的“试衣间“):
- 你输入 API 地址:
https://api.example.com/login - 选择操作类型:POST(创建)
- 填写数据:
{username: "test", password: "123"} - 点击“发送“→ 看到返回结果:
{code: 200, msg: "登录成功"}
类比:
- 浏览器 = 逛网页的工具(给人看的)
- Postman = 测试 API 的工具(给开发者测试的)
- 后端 API = 数据的“取货窗口“(程序从这里拿数据)
💡 不用慌:你不需要现在就下载 Postman!下一章《环境搭建》会手把手教你安装和使用。现在只需要知道:API 是一个网址,有工具可以测试它。
底层原理
用户操作 API请求 服务器处理
───────────────────────────────────────────────────────────
点击"登录"按钮 → POST /api/login → 验证账号密码
{username, password}
点击"发布笔记" → POST /api/notes → 保存到数据库
{title, content}
打开笔记列表 → GET /api/notes → 查询数据库
?user_id=123
API 的4种常见操作
| 操作 | API方法 | 类比 | 示例 |
|---|---|---|---|
| 查看 | GET | 看菜单 | GET /api/notes 获取笔记列表 |
| 创建 | POST | 点菜 | POST /api/notes 创建新笔记 |
| 修改 | PUT | 改菜 | PUT /api/notes/123 修改笔记 |
| 删除 | DELETE | 退菜 | DELETE /api/notes/123 删除笔记 |
❓ 小白疑问:为什么 POST 是“创建“,PUT 是“修改“?
- POST(邮寄/投递)→ 把新东西送到服务器(创建)
- PUT(放置/替换)→ 把旧的换成新的(修改)
- DELETE(删除)→ 直接扔掉(删除)
- GET(获取)→ 拿回来看(查看)
💡 Vibe Coding 提示: 下面会出现一些“流程描述“,不是真正的代码!这只是展示逻辑流程,真正的代码让 AI 写。
流程描述(理解逻辑就好,具体代码让 AI 写)
用户点击“登录“按钮时发生什么?
步骤1:前端准备数据
├─ 收集用户输入:用户名="zhangsan", 密码="123456"
└─ 打包成一个"包裹"(这种格式叫 JSON,就像快递包装盒)
格式:{username: "zhangsan", password: "123456"}
解释:大括号{}表示"这是一个包裹"
冒号:表示"这是什么东西"
引号""表示"这是文字"
步骤2:发送到服务器
├─ 目标地址:https://api.example.com/login
├─ 发送方式:POST(告诉服务器"我要创建新的登录会话")
└─ 包裹内容:上面打包好的数据
步骤3:服务器返回结果
└─ 返回内容:{code: 200, msg: "登录成功", data: {token: "abc123"}}
解释:code=200 表示"成功"
msg 是给你看的提示文字
token 是你的"通行证"(下一节会讲)
🔍 如果你想看真实的代码长什么样(可跳过):
点击展开查看真实代码(AI 会帮你写,现在不用看懂)
// 用户点击"登录"按钮时
async function login() {
const response = await fetch('https://api.example.com/login', {
method: 'POST',
body: JSON.stringify({
username: 'zhangsan',
password: '123456'
})
});
const result = await response.json();
// result = {code: 200, msg: "登录成功", data: {token: "abc123"}}
}
解释:
async/await:告诉浏览器“这个操作需要等一会儿“(网络请求需要时间)fetch():浏览器内置的“发快递“函数JSON.stringify():把数据打包成标准格式- 你不需要理解每个单词,AI 会帮你写这些!
3️⃣ 数据库用“表格“存储数据(像 Excel 一样)
日常类比
数据库 = 一堆 Excel 表格的集合
用户表 (users)
┌────┬──────────┬─────────────────────┬──────────┐
│ id │ username │ email │ 密码 │
├────┼──────────┼─────────────────────┼──────────┤
│ 1 │ zhangsan │ zhang@example.com │ abc123 │
│ 2 │ lisi │ li@example.com │ def456 │
└────┴──────────┴─────────────────────┴──────────┘
笔记表 (notes)
┌────┬─────────┬────────────┬─────────────────────┐
│ id │ user_id │ 标题 │ 内容 │
├────┼─────────┼────────────┼─────────────────────┤
│ 1 │ 1 │ 学习笔记 │ 今天学习了Python... │
│ 2 │ 1 │ 购物清单 │ 需要买牛奶... │
│ 3 │ 2 │ 旅游计划 │ 下周去北京... │
└────┴─────────┴────────────┴─────────────────────┘
关键概念
- 表(Table) = 一张 Excel 表格(如“用户表“)
- 列(Column) = 表格的列名(如“用户名“、“邮箱”)
- 行(Row) = 一条记录(如“张三的账号信息“)
- 主键(Primary Key) = 唯一标识(如“身份证号“)
- 外键(Foreign Key) = 关联其他表(如笔记表的
user_id关联用户表)
❓ 小白疑问:既然像 Excel,为什么不能直接打开表格界面操作?
答案:因为数据量太大了!
- Excel 适合:几百行数据,你可以滑鼠标翻页查看
- 数据库 适合:几百万、几亿行数据,不可能手动翻页找
类比:
- Excel = 你家的书架(几十本书,可以一本本翻)
- 数据库 = 国家图书馆(几千万本书,必须用检索系统精准查找)
所以我们要用**指令(SQL)**告诉数据库“帮我找用户ID=1的所有笔记“,而不是手动翻几百万行数据。
💡 Vibe Coding 提示: 下面的 SQL 查询示例只是让你看懂逻辑,不用背!真正写项目时,让 AI 帮你生成这些查询语句。
SQL 查询逻辑示例(理解意思就好,不用背语法)
你想做的事:查询张三(user_id=1)的所有笔记
用 SQL 指令表达:
SELECT * FROM notes WHERE user_id = 1;
翻译成人话:
SELECT * → 选择所有列(标题、内容等全要)
FROM notes → 从"笔记表"里
WHERE user_id=1 → 条件是"用户ID等于1"
返回结果(就像 Excel 筛选后的结果):
id | user_id | 标题 | 内容
1 | 1 | 学习笔记 | 今天学习了Python...
2 | 1 | 购物清单 | 需要买牛奶...
记住:AI 会帮你写这些 SQL,你只需要用人话告诉 AI“我要查张三的所有笔记“就行!
4️⃣ 需要验证身份(Token 就像会员卡)
日常类比
Token = 健身房会员卡
- 第一次办卡:出示身份证(账号密码)→ 工作人员验证 → 发会员卡(Token)
- 后续进门:刷卡(带 Token)→ 闸机验证 → 放行
- 不用每次都出示身份证
底层原理
完整流程(用户登录):
1. 用户登录
POST /api/login
{username: "zhangsan", password: "123456"}
2. 服务器验证
├─ 检查用户名密码
└─ 生成 Token(有效期7天)
3. 返回 Token
{code: 200, data: {token: "eyJhbGciOiJIUzI1NiIsInR5..."}}
4. 前端存储 Token
localStorage.setItem('token', 'eyJhbGci...')
5. 后续请求都带 Token
GET /api/user/profile
Headers: {Authorization: "Bearer eyJhbGci..."}
6. 服务器验证 Token
├─ 解析 Token → 知道是 user_id=123
├─ 检查是否过期
└─ 允许访问
❓ 小白疑问:Token 那一长串乱码是什么?需要记住吗?
答案:完全不需要记!Token 是电脑自动生成和自动使用的。
Token 长这样:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjN9.SflKxw...
类比理解:
- 健身房会员卡 = 你只要刷卡就行,不需要知道卡里的芯片是怎么工作的
- Token = 浏览器自动存储和发送,你不需要复制到本子上
它包含什么?(AI 会帮你处理,你只需要知道)
user_id=123(你是谁)过期时间(比如7天后失效)签名(防止别人伪造)
你只需要做的:用户登录成功后,浏览器自动保存 Token。后续操作浏览器自动带上它。就这么简单!
💡 Vibe Coding 提示: 下面的 JavaScript 代码现在不需要看懂!这只是展示“登录流程“的样子。真正写项目时,复制这段逻辑描述给 AI,让它帮你写代码。
代码示例(理解流程就好,具体代码让 AI 写)
// 步骤1: 用户登录
async function login() {
const response = await fetch('/api/login', {
method: 'POST',
body: JSON.stringify({
username: 'zhangsan',
password: '123456'
})
});
const result = await response.json();
// 步骤2: 存储 Token
localStorage.setItem('token', result.data.token);
}
// 步骤3: 后续操作都带上 Token
async function getUserInfo() {
const token = localStorage.getItem('token');
const response = await fetch('/api/user/profile', {
headers: {
'Authorization': `Bearer ${token}`
}
});
return await response.json();
}
为什么用 Token 而不是每次输密码?
- ❌ 不安全: 密码在网络中传输太多次,容易被截获
- ❌ 体验差: 每次操作都输密码太麻烦
- ✅ 用 Token: Token 有有效期(如7天),过期需要重新登录
5️⃣ 后端负责“业务逻辑“(不只是存取数据)
日常类比
前端 vs 后端
- 前端 = 银行柜台(接待客户,展示界面)
- 后端 = 银行系统(验证身份、扣款、转账、记录)
你不能自己在柜台的电脑上输入“给我转100万“,必须由银行系统验证和执行。
💡 Vibe Coding 提示: 下面的 Python 代码示例只是让你理解“后端做什么事“。看不懂代码?正常!你现在不需要懂Python语法,只需要看注释理解每一步在做什么。
业务逻辑示例(看注释理解流程,代码让 AI 写)
# 后端代码(不是前端!)
@app.post("/api/register")
def register(username: str, password: str):
# 1. 检查用户名是否已存在(前端无法做到)
if db.query(User).filter(User.username == username).first():
return {"code": 400, "msg": "用户名已存在"}
# 2. 密码加密(前端不能做,不安全)
hashed = hashlib.sha256(password.encode()).hexdigest()
# 3. 存入数据库
user = User(username=username, password_hash=hashed)
db.add(user)
db.commit()
# 4. 发送欢迎邮件(前端做不到)
send_email(user.email, "欢迎注册!")
return {"code": 200, "msg": "注册成功"}
为什么不能在前端做这些?
| 操作 | 前端能做吗? | 原因 |
|---|---|---|
| 检查用户名是否存在 | ❌ | 前端看不到数据库 |
| 加密密码 | ❌ | 前端代码可以被看到,不安全 |
| 扣减库存 | ❌ | 如果前端做,用户可以改代码“白嫖“ |
| 发送通知 | ❌ | 前端没有权限调用邮件/短信服务 |
| 计算推荐内容 | ❌ | 需要分析大量数据,前端做不到 |
❓ 小白疑问:为什么说“前端代码可以被看到“?我在手机 APP 上看不到代码啊?
答案:前端代码必须暴露,因为浏览器需要执行它。
类比理解(重要!):
前端代码 = 便利贴贴在屏幕上
- 你在网页上右键 → 点击“查看源代码“ → 就能看到所有前端代码
- 按 F12 键 → 打开“开发者工具“ → 看到网络请求、接口地址、所有操作
- 这就像把保险箱密码写在便利贴上贴在屏幕上,虽然普通人不会注意,但懂行的人(黑客)很容易就能翻到那张便利贴
后端代码 = 锁在银行金库里
- 运行在服务器上,用户完全看不到
- 就算黑客按 F12,也只能看到服务器返回的结果,看不到后端代码
所以:
- ✅ 密码加密、权限验证、支付扣款 → 必须在后端做(安全)
- ✅ 界面显示、按钮动画、表单验证 → 可以在前端做(用户体验)
记住:不是前端技术不好,而是前端天生就是“公开“的(必须给浏览器执行),所以重要操作必须交给“不公开“的后端。
🔗 5个知识点如何串联?
完整流程(用户发布笔记)
1. 用户操作
你在APP输入标题和内容,点击"发布"按钮
2. 前端发 API 请求
POST /api/notes
Headers: {Authorization: "Bearer token123"} ← 带Token验证身份
Body: {title: "学习笔记", content: "今天学了..."}
3. 后端接收并处理
├─ 验证Token → 知道是user_id=1的用户
├─ 检查内容是否违规(业务逻辑)
├─ 存入数据库的notes表(表格存储)
└─ 返回结果: {code: 200, msg: "发布成功", data: {note_id: 456}}
4. 前端收到响应
显示"发布成功"提示,跳转到笔记列表页面
5. 数据永久保存
笔记存在云端数据库(服务器),你换设备登录也能看到
📊 知识点总结
| 知识点 | 核心理解 | 日常类比 |
|---|---|---|
| 1. 数据在云端 | 数据存在远程服务器,不在你的设备 | 钱在银行,不在钱包 |
| 2. API请求 | 每次操作都要通过API和服务器对话 | 点外卖下单 |
| 3. 数据库表格 | 数据用表格形式存储,有行和列 | Excel表格 |
| 4. Token身份验证 | 登录后拿到“通行证“,后续操作带着它 | 健身房会员卡 |
| 5. 后端业务逻辑 | 复杂的验证、计算、存储都在后端做 | 银行后台系统 |
💡 Vibe Coding 提示
看到这里,你可能还是有点懵,这很正常!
🎯 你只需要记住这三点
- 数据存在云端,不在你手机里(所以换设备数据还在)
- 操作都是发 API 请求,前后端通过 API 对话(就像点外卖)
- 后端处理复杂逻辑,前端只管显示界面(前端做不了的事后端来做)
✅ 你不需要做的
- ❌ 不需要背代码:所有代码都可以让 AI 写
- ❌ 不需要懂语法:
async、await、@app.post这些都不用懂 - ❌ 不需要完全理解:Token怎么生成、SQL怎么写,后面章节会学
🤖 遇到困惑时的行动指南
如果你对某个概念还是不理解,复制这个模板问 AI:
我正在学习后端开发,不太理解 [后端/API/Token/数据库] 是什么。
我的理解是:[写下你的理解]
请用日常生活的例子(比如银行、餐厅、快递)帮我解释一下:
1. 它是什么?
2. 它解决什么问题?
3. 为什么需要它?
AI 会用你能懂的方式重新解释,直到你理解为止。
📌 下一步建议
不用全部理解透彻才继续,能理解 60-70% 就可以进入下一节。
很多概念在实际动手后会突然“顿悟“,现在只需要有个大概印象就好。
📚 下一步
👉 环境搭建
学习如何配置 Python、VS Code、Supabase 等开发工具。
返回 后端开发基础 查看完整目录。
环境搭建
方法论: 工具装好,代码能跑,就是成功。遇到问题复制报错问 AI。
📖 本节目标
学完本节,你将能够:
- ✅ 安装 Python 并验证
- ✅ 创建虚拟环境(隔离项目依赖)
- ✅ 配置 VS Code 开发环境
- ✅ 注册 Supabase 数据库
- ✅ 安装 API 测试工具
预计用时: 30 分钟
1. 安装 Python
1.1 为什么需要 Python?
Python = 后端的运行环境
就像你玩游戏需要安装游戏客户端一样,写 Python 代码也需要先安装 Python。
1.2 下载安装
推荐版本: Python 3.10 或 Python 3.11(稳定版)
Windows 用户:
- 访问 python.org/downloads
- 下载 Python 3.11.x 安装包(点击大按钮“Download Python 3.11.x“)
- 双击安装包
- 重要! 勾选 ✅ “Add Python to PATH”(最下面的复选框)
- 点击 “Install Now”
- 等待安装完成
Mac 用户:
# 方式1: 使用 Homebrew(推荐)
brew install python@3.11
# 方式2: 官网下载安装包
访问 python.org/downloads
下载 macOS 安装包并安装
1.3 验证安装
第一步: 打开终端/命令行
什么是终端? 终端 = 电脑的文字控制台,就像你和电脑用打字聊天一样。不用害怕,它不会弄坏你的电脑。
Windows 用户(3 种方法):
- 按
Win + R键,输入cmd,按回车(最快) - 点击开始菜单,搜索“命令提示符“或“cmd“
- 在任意文件夹按住
Shift,右键点击空白处,选择“在此处打开 PowerShell 窗口“
Mac 用户(2 种方法):
- 按
Command + 空格,输入Terminal,按回车(最快) - 打开“启动台“,找到“其他“文件夹,点击“终端“
第二步: 验证 Python
在终端窗口输入:
python --version
或者(Mac/Linux 可能需要用 python3):
python3 --version
成功的样子:
Python 3.11.5
如果报错 “command not found” 或 “不是内部或外部命令”:
- 重启终端再试一次
- 还不行,复制报错信息问 AI:
“我安装 Python 后输入 python –version 报错:[粘贴报错信息]”
2. 创建虚拟环境
2.1 什么是虚拟环境?
虚拟环境 = 每个项目的独立工作间
类比理解:
- 你有多个项目,每个项目需要不同版本的工具
- 项目 A 需要 FastAPI 0.100.0
- 项目 B 需要 FastAPI 0.95.0
- 如果都装在同一个地方,就会冲突
- 虚拟环境让每个项目有自己的工具箱
2.2 创建第一个项目
步骤1: 创建项目文件夹
建议: 先在桌面新建一个文件夹叫
my-backend,这样你能随时在“我的电脑“里找到它。
方式 A: 用鼠标操作(推荐新手):
- 在桌面右键,新建文件夹,命名为
my-backend - 进入这个文件夹
- 在文件夹空白处,按住
Shift+ 右键(Windows)或直接右键(Mac),选择“在此处打开终端/命令行“
方式 B: 用命令行:
# 创建文件夹
mkdir my-backend
# 进入文件夹
cd my-backend
提示: 如果你用命令行创建,文件夹会在你当前打开终端的位置。不确定在哪?输入
pwd(Mac/Linux)或cd(Windows)可以查看当前路径。
步骤2: 创建虚拟环境
# 创建虚拟环境(名字叫 venv)
python -m venv venv
等待几秒钟,会生成一个 venv 文件夹。
步骤3: 激活虚拟环境
Windows:
venv\Scripts\activate
Mac/Linux:
source venv/bin/activate
成功的样子:
命令行前面会出现 (venv) 标记:
(venv) C:\Users\你的名字\my-backend>
2.3 安装 FastAPI
激活虚拟环境后,安装 FastAPI:
pip install fastapi uvicorn[standard]
工具认知小贴士:
- FastAPI = 写 API 的工具(就像 Word 是写文档的工具)
- Uvicorn = 运行服务器的引擎(就像游戏需要引擎才能跑起来)
[standard]= 安装标准版(包含更多功能,新手直接用这个就行,不用管为什么)
等待安装完成(会显示一堆下载信息,这是正常的)。
如果下载很慢,配置国内镜像:
# 配置淘宝镜像(一次性设置)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 再次安装
pip install fastapi uvicorn[standard]
验证安装:
pip list
应该能看到 fastapi 和 uvicorn 在列表里。
2.4 退出虚拟环境
deactivate
命令行前面的 (venv) 会消失。
3. 配置 VS Code
3.1 为什么选 VS Code?
VS Code = 最受欢迎的代码编辑器
- ✅ 免费开源
- ✅ 插件丰富
- ✅ 轻量快速
- ✅ 支持所有编程语言
3.2 下载安装
点击大按钮下载,双击安装,一路“下一步“。
3.3 安装必备插件
打开 VS Code 后,点击左侧边栏的扩展图标(四个方块)。
必装插件(搜索名字安装):
-
Python (Microsoft 官方)
- 作用:代码高亮、智能提示、调试
- 搜索 “Python”,点击 Install
-
Pylance (Microsoft 官方)
- 作用:类型检查、更好的代码补全
- 搜索 “Pylance”,点击 Install
-
Thunder Client (可选,但推荐)
- 作用:在 VS Code 里测试 API
- 搜索 “Thunder Client”,点击 Install
-
indent-rainbow (强烈推荐)
- 作用:缩进高亮(Python 必备!)
- 搜索 “indent-rainbow”,点击 Install
3.4 配置 Python 解释器
-
打开你的项目文件夹(
my-backend)- File → Open Folder → 选择
my-backend
- File → Open Folder → 选择
-
打开任意
.py文件(或新建一个test.py) -
按
Ctrl+Shift+P(Mac:Cmd+Shift+P) -
输入 “Python: Select Interpreter”
-
选择带
(venv)的那个选项./venv/Scripts/python.exe
3.5 创建第一个 Python 文件
在 VS Code 中新建文件 main.py:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
return {"message": "Hello World"}
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
代码解读 (不用背,让 AI 写就行):
- 前 7 行:定义了一个最简单的 API(返回 Hello World)
if __name__ == "__main__":这 4 行:Python 的启动开关(就像电视机的电源开关,现在先别管为什么这么写,照抄就行)想深入理解? 复制这段代码问 AI:“这段代码每一行都是什么意思?”,AI 会给你详细解释。
运行代码:
在终端输入:
# 确保虚拟环境已激活(前面有 (venv))
python main.py
成功的样子:
INFO: Uvicorn running on http://0.0.0.0:8000
INFO: Application startup complete.
打开浏览器,访问 http://localhost:8000
应该能看到:
{"message": "Hello World"}
恭喜!你的第一个 API 跑起来了! 🎉
框架理解:整个流程是怎么运转的?
想象你开了一家餐厅(后端服务器):
- Python = 餐厅的地基(运行环境)
- FastAPI = 餐厅的菜单系统(定义你提供什么服务)
- Uvicorn = 餐厅的大门和收银台(接待客人的请求)
- 这段代码 = 你的第一道菜:“Hello World 套餐”
数据流向: 浏览器(客人)→ 输入网址 → Uvicorn(大门)→ FastAPI(菜单)→ 你的代码(厨师做菜)→ 返回结果(上菜)→ 浏览器显示
后面我们会加上 Supabase(仓库),这样数据就能永久存储了。
4. 注册 Supabase
4.1 什么是 Supabase?
Supabase = 免费的云数据库
- 不用自己搭建数据库服务器
- 提供可视化管理界面
- 免费额度:500MB 数据库 + 1GB 存储
4.2 注册账号
- 访问 supabase.com
- 点击 “Start your project”
- 选择 GitHub 账号登录(推荐)或邮箱注册
4.3 创建项目
- 登录后点击 “New Project”
- 填写信息:
- Name: 项目名称(如
my-backend-db) - Database Password: 设置一个密码(记住它!)
- Region: 选择
Northeast Asia (Tokyo)或Southeast Asia (Singapore)
- Name: 项目名称(如
- 点击 “Create new project”
- 等待 2-3 分钟(会显示进度条)
4.4 获取连接信息
项目创建成功后:
- 点击左侧菜单 “Settings”(齿轮图标)
- 点击 “API”
- 找到这两个信息(后面会用到):
- Project URL:
https://xxx.supabase.co - anon public key: 一串很长的字符串
- Project URL:
妥善保存这两个信息:
重要!保存方法:
- 在桌面新建一个记事本文件(或用 VS Code 新建),命名为
supabase-secrets.txt- 把这两个信息粘贴进去,格式如下:
Project URL: https://xxx.supabase.co Anon Key: eyJhbGci...(一串很长的字符)- 保存好,不要分享给别人
- 这个文件放在项目文件夹里就行,以后需要用的时候直接复制
安心提示: 如果不小心关了网页,随时可以回到 Supabase 项目的 Settings → API 重新查看。
4.5 创建第一张表
- 点击左侧菜单 “Table Editor”
- 点击 “Create a new table”
- 填写表信息:
- Name:
users(表名) - 保留默认字段(
id,created_at) - 点击 “Add column” 添加新字段:
username(type: text, unique: ✅)email(type: text)password_hash(type: text)
- Name:
- 点击 “Save”
成功!你已经有了第一张数据库表! 🎉
5. 安装 API 测试工具
5.1 为什么需要测试工具?
测试工具 = 模拟前端发请求
- 你写了一个注册接口
POST /api/users/register - 但前端还没写好
- 测试工具可以直接发请求测试接口
5.2 选择一:FastAPI 自带文档(最简单,推荐新手)
无需安装! 运行 FastAPI 后直接访问:
http://localhost:8000/docs
会看到自动生成的 API 文档,可以直接测试。
5.3 选择二:Postman(功能强大)
新手要不要装? 可以先跳过!用 FastAPI 自带的
/docs或 VS Code 的 Thunder Client 插件就够了。Postman 功能很强,但对新手来说有点复杂。等你熟练了再装也不迟。
下载安装:
- 访问 postman.com/downloads
- 下载并安装
- 注册账号(免费)
创建第一个请求:
- 点击 “New” → “HTTP Request”
- 选择方法:
POST - 输入 URL:
http://localhost:8000/api/users/register - 点击 “Body” → 选择 “raw” → 选择 “JSON”
- 输入数据:
{ "username": "zhangsan", "password": "123456", "email": "zhang@example.com" } - 点击 “Send”
5.4 选择三:Thunder Client(VS Code 插件,推荐)
安装:
在 VS Code 扩展商店搜索 “Thunder Client”,点击 Install。
使用:
- 左侧边栏出现 ⚡ 图标
- 点击 “New Request”
- 和 Postman 类似操作
6. 快速检查清单
完成后,检查这些:
- 终端输入
python --version能显示版本号 - 能创建并激活虚拟环境(命令行前有
(venv)) -
pip list能看到fastapi和uvicorn - VS Code 能打开并运行 Python 代码
- 访问 http://localhost:8000 能看到 “Hello World”
- Supabase 项目已创建,能看到 users 表
- 能用 /docs 或 Postman 测试 API
全部✅?恭喜你,开发环境搭建完成! 🎉
7. 常见问题
Q1: pip install 很慢怎么办?
A: 配置国内镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
Q2: python –version 提示 “command not found”
A:
Windows: 重新安装 Python,勾选 “Add Python to PATH”
Mac: 改用 python3 --version,或安装 Homebrew 后用 brew install python@3.11
Q3: 虚拟环境激活后命令行没有 (venv) 标记
A:
可能是激活成功了但没显示。试试安装 FastAPI:
pip install fastapi
如果能安装,说明激活成功了。
Q4: VS Code 找不到 Python 解释器
A:
- 按
Ctrl+Shift+P - 输入 “Python: Select Interpreter”
- 点击 “Enter interpreter path”
- 手动输入虚拟环境 Python 路径:
- Windows:
./venv/Scripts/python.exe - Mac/Linux:
./venv/bin/python
- Windows:
Q5: Supabase 项目创建失败
A:
- 检查网络连接
- 换个浏览器试试
- 重新注册账号
- 还不行就复制报错问 AI
💡 Vibe Coding 提示
如果你遇到了上面没提到的问题:
-
复制完整报错信息(不要只复制一部分)
- 看到红色文字不要慌,这是电脑在告诉你哪里需要调整
- 报错信息是 AI 的重要线索,要全部复制
-
问 AI 的正确姿势:
我在 [安装Python/配置VS Code/创建Supabase] 时遇到这个错误: [粘贴完整报错信息] 我的系统是:[Windows 11 / macOS 等] 我已经尝试了:[你做过的操作] -
按照 AI 的建议一步步操作
- 一次只做一个修改
- 每次修改后测试是否有效
- 如果不行,告诉 AI 结果,让它给新方案
-
还不行就换个方式
- 比如 Python 官网下载不了就用 Homebrew
- pip 安装慢就配置国内镜像
- VS Code 有问题可以试试重启电脑
AI 协作核心:
- 你只需要理解做什么(装 Python、创建虚拟环境、运行代码)
- 具体怎么做(命令、代码、配置)都可以问 AI
- 验证方法:运行代码,看到预期结果(如 Hello World)就说明成功了
记住: 工具只是手段,能跑起来就行。不要在环境配置上花太多时间。如果卡住超过 30 分钟,直接把问题发给 AI,让它帮你解决。
📚 下一步
👉 第一个接口
从 Hello World 到用户注册,写出第一个真正可用的 API。
返回 后端开发基础 查看完整目录。
第一个接口
方法论: 从 Hello World 到用户注册,一步步写出真正可用的 API。
📖 本节目标
学完本节,你将能够:
- ✅ 写出第一个 Hello World 接口
- ✅ 理解路由、参数、响应的概念
- ✅ 使用 Pydantic 自动验证数据
- ✅ 实现用户注册接口
- ✅ 用 /docs 自动文档测试接口
预计用时: 40 分钟
0. 环境准备(必看!)
0.1 安装必要的库
在写代码之前,我们需要先安装一些工具(就像装修前先买工具)。
打开终端(黑框框),输入以下命令:
pip install fastapi uvicorn[standard] pydantic[email]
这行命令做了什么?
fastapi:后端框架,用来写 APIuvicorn:服务器,用来运行你的 APIpydantic[email]:数据验证库,带邮箱格式验证功能
预期结果: 看到类似 “Successfully installed fastapi-0.xx.x uvicorn-0.xx.x…” 的提示就成功了。
遇到报错?不要慌!
- 如果提示 “pip 不是内部或外部命令”,说明 Python 没装好,把错误信息复制给 AI 问怎么解决
- 如果提示权限错误,在命令前加
sudo(Mac/Linux)或用管理员身份运行(Windows)
1. Hello World 接口
1.1 最简单的接口
创建 main.py:
from fastapi import FastAPI
# 创建应用实例
app = FastAPI()
# 定义根路由
@app.get("/")
def root():
return {"message": "Hello World"}
# 启动应用(开发环境)
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
运行:
python main.py
访问: http://localhost:8000
会看到:
{"message": "Hello World"}
1.2 理解代码
@app.get("/") # ← 装饰器:告诉 FastAPI 这是一个 GET 请求,路径是 "/"
def root(): # ← 函数名随便起,但要见名知意
return {"message": "Hello World"} # ← 返回 JSON 数据
类比理解:
@app.get("/") = 在餐厅门口挂牌子:"这里是大门"
def root() = 定义:客人进门后要做什么
return {...} = 给客人回复:"你好,欢迎光临"
1.3 自动文档
FastAPI 最强大的功能:自动生成 API 文档
访问:http://localhost:8000/docs
你会看到一个漂亮的交互式文档(Swagger UI),可以直接测试接口!
2. 理解路由和参数
2.1 路径参数(Path Parameters)
场景: 获取指定 ID 的用户信息
@app.get("/users/{user_id}")
def get_user(user_id: int):
return {"user_id": user_id, "username": f"user_{user_id}"}
访问: http://localhost:8000/users/123
返回:
{"user_id": 123, "username": "user_123"}
理解:
{user_id}是占位符,可以匹配任意内容user_id: int自动把字符串转成整数- 如果访问
/users/abc,FastAPI 会自动返回 400 错误(类型不匹配)
小知识:f-string 是什么?
代码中的 f"user_{user_id}" 是 Python 的 f-string(格式化字符串),作用是把变量填进字符串。
# 普通拼接(繁琐)
username = "user_" + str(user_id)
# f-string(简洁)
username = f"user_{user_id}" # 花括号里的变量会自动替换
类比理解:就像填空题,f"user_{user_id}" 表示“user_“ + 这里填 user_id 的值。
你只需要记住:看到 f"...{变量}..." 就是在做字符串填空,让 AI 帮你写就行!
2.2 查询参数(Query Parameters)
场景: 搜索功能,带分页
@app.get("/search")
def search(q: str, skip: int = 0, limit: int = 10):
return {
"query": q,
"skip": skip,
"limit": limit,
"results": [f"结果 {i}" for i in range(1, limit + 1)]
}
访问: http://localhost:8000/search?q=Python&skip=0&limit=5
返回:
{
"query": "Python",
"skip": 0,
"limit": 5,
"results": ["结果 1", "结果 2", "结果 3", "结果 4", "结果 5"]
}
理解:
- 查询参数在 URL 后面,用
?开头,&连接 skip: int = 0表示有默认值,可以不传q: str没有默认值,必须传
2.3 请求体(Request Body)
场景: 用户提交表单数据
from pydantic import BaseModel
# 定义数据模型
class Item(BaseModel):
name: str
price: float
description: str = None # 可选字段
@app.post("/items")
def create_item(item: Item):
return {
"message": "创建成功",
"item": {
"name": item.name,
"price": item.price,
"description": item.description
}
}
测试(用 /docs 或 Postman):
请求:
POST /items
{
"name": "苹果",
"price": 5.5,
"description": "新鲜的苹果"
}
返回:
{
"message": "创建成功",
"item": {
"name": "苹果",
"price": 5.5,
"description": "新鲜的苹果"
}
}
3. Pydantic 数据验证
3.1 为什么需要数据验证?
不验证的后果:
@app.post("/users")
def create_user(username, password):
# ❌ 用户可能传入任何数据
# username = "" (空字符串)
# password = 123 (不是字符串)
# 你需要手动写一堆 if 判断
...
用 Pydantic 自动验证:
from pydantic import BaseModel, Field, EmailStr
class UserRegisterRequest(BaseModel):
username: str = Field(..., min_length=3, max_length=50)
password: str = Field(..., min_length=6)
email: EmailStr # 自动验证邮箱格式
@app.post("/users/register")
def register(user: UserRegisterRequest):
# ✅ 到这里,数据一定是合法的
# username 长度 3-50
# password 长度 >= 6
# email 格式正确
return {"message": "注册成功"}
3.2 Field 验证规则
from pydantic import BaseModel, Field
class UserModel(BaseModel):
# 必填,长度 3-50
username: str = Field(..., min_length=3, max_length=50)
# 必填,最少 6 个字符
password: str = Field(..., min_length=6)
# 可选,1-120 之间
age: int = Field(None, ge=1, le=120)
# 可选,默认值是 False
is_active: bool = Field(default=True)
常用验证规则:
| 规则 | 说明 | 示例 |
|---|---|---|
... | 必填(没有默认值) | Field(...) |
default=xxx | 默认值 | Field(default=0) |
min_length | 最小长度 | Field(..., min_length=3) |
max_length | 最大长度 | Field(..., max_length=50) |
ge | 大于等于(greater or equal) | Field(None, ge=1) |
le | 小于等于(less or equal) | Field(None, le=120) |
regex | 正则表达式 | Field(..., regex=r'^[a-z0-9]+$') |
3.3 自动错误提示
如果用户传入不合法的数据,FastAPI 会自动返回详细错误:
请求:
POST /users/register
{
"username": "ab", ← 太短(最少 3 个字符)
"password": "123", ← 太短(最少 6 个字符)
"email": "not-an-email" ← 格式错误
}
返回:
{
"detail": [
{
"loc": ["body", "username"],
"msg": "ensure this value has at least 3 characters",
"type": "value_error.any_str.min_length"
},
{
"loc": ["body", "password"],
"msg": "ensure this value has at least 6 characters",
"type": "value_error.any_str.min_length"
},
{
"loc": ["body", "email"],
"msg": "value is not a valid email address",
"type": "value_error.email"
}
]
}
用户看到清晰的错误提示! 你不用写一行验证代码!
4. 实战:用户注册接口
4.1 需求分析
接口路径: POST /api/users/register
请求参数:
username: 用户名(3-50 字符)password: 密码(最少 6 字符)email: 邮箱(可选,格式验证)
返回格式:
{
"code": 200,
"msg": "注册成功",
"data": {
"user_id": 123
}
}
4.2 完整代码
第一步:定义数据模型
from pydantic import BaseModel, Field, EmailStr
from typing import Optional
class UserRegisterRequest(BaseModel):
"""用户注册请求模型"""
username: str = Field(..., min_length=3, max_length=50, description="用户名")
password: str = Field(..., min_length=6, description="密码")
email: Optional[EmailStr] = Field(None, description="邮箱")
class Config:
# 在 /docs 文档中显示的示例(方便测试)
schema_extra = {
"example": {
"username": "zhangsan",
"password": "123456",
"email": "zhangsan@example.com"
}
}
关于 class Config 的说明(可跳过):
这是 Pydantic 的配置类,用来给 FastAPI 的 /docs 文档提供测试示例数据。
为什么要写这个?
- 不写也能跑,但写了之后在
/docs测试时会自动填好示例数据,省得你每次都手动输入。
类比理解:就像给表单预填了一个“张三“的示例,方便你快速测试,不需要每次都想用户名。
Vibe Coding 建议:先把代码跑通,这个 Config 可以以后再加。如果你觉得它复杂,可以直接删掉,不影响功能!
第二步:定义统一响应格式
Vibe Coding 提示:这部分代码比较复杂(涉及
class、@staticmethod等语法),但好消息是:你只需要理解它的作用,具体语法让 AI 写!
from typing import Optional, Any
class Response(BaseModel):
"""统一响应格式"""
code: int # 状态码(200=成功,400/500=失败)
msg: str # 提示信息(给用户看的文字)
data: Optional[Any] = None # 返回数据(可以是任意类型)
class R:
"""响应工具类(快速生成响应的工具箱)"""
@staticmethod
def success(data: Any = None, msg: str = "操作成功"):
return Response(code=200, msg=msg, data=data)
@staticmethod
def error(msg: str = "操作失败", code: int = 500):
return Response(code=code, msg=msg, data=None)
你只需要记住:
R.success(data={...})= 返回成功消息R.error(msg="失败原因")= 返回错误消息
关于语法细节(可以跳过):
Optional[Any]:表示这个字段可以是任意类型,也可以为空(让 AI 帮你写)@staticmethod:表示这是一个工具函数,可以直接用R.success()调用(让 AI 帮你写)- 如果你看到这些语法觉得头晕,完全可以跳过! 先把功能跑通,以后再慢慢理解。
类比理解:class R 就像一个万能回复模板生成器。你只需要告诉它“成功了“或“失败了“,它就自动生成标准格式的回复。
第三步:实现注册接口
from fastapi import FastAPI, HTTPException
import hashlib
app = FastAPI(title="我的后端 API")
# 模拟数据库(真实项目会用 Supabase)
users_db = []
**重要提示:关于"模拟数据库"**
这里用列表 `[]` 来模拟数据库,**数据只存在内存里**。这意味着:
- ✅ 程序运行时,注册的用户会保存在 `users_db` 里
- ❌ 关闭程序后再重启,所有用户数据会消失
**为什么不直接用真数据库?**
因为我们要先学会"怎么写接口逻辑",数据库是下一章的内容。就像学开车要先学方向盘,再学倒车入库。
**类比理解**:`users_db = []` 就像在草稿纸上记笔记,擦掉就没了。真正的数据库(Supabase)才是记在本子上,永久保存。
---
@app.post("/api/users/register", response_model=Response)
def register(user: UserRegisterRequest):
"""
用户注册接口
- **username**: 用户名(3-50 字符)
- **password**: 密码(最少 6 字符)
- **email**: 邮箱(可选)
"""
# 1. 检查用户名是否已存在
for existing_user in users_db:
if existing_user["username"] == user.username:
return R.error(msg="用户名已存在", code=400)
# 2. 密码加密(实际项目用 bcrypt,这里简化演示)
password_hash = hashlib.sha256(user.password.encode()).hexdigest()
# 👆 这行代码看起来很吓人?别慌!你只需要知道它做了什么:
# - 把密码(如 "123456")变成一串乱码(如 "8d969eef6...")
# - 这样即使数据库被黑客偷走,黑客也看不懂原始密码
# - 具体怎么写?直接问 AI:"帮我写密码加密代码"
# 3. 存入"数据库"
new_user = {
"user_id": len(users_db) + 1,
"username": user.username,
"password_hash": password_hash,
"email": user.email
}
users_db.append(new_user)
# 4. 返回成功响应
return R.success(
msg="注册成功",
data={"user_id": new_user["user_id"]}
)
4.3 测试接口
方式1: 使用 /docs
- 访问 http://localhost:8000/docs
- 找到
POST /api/users/register - 点击 “Try it out”
- 输入数据:
{ "username": "zhangsan", "password": "123456", "email": "zhang@example.com" } - 点击 “Execute”
- 看到返回结果:
{ "code": 200, "msg": "注册成功", "data": { "user_id": 1 } }
方式2: 使用 Postman 或 Thunder Client
请求:
POST http://localhost:8000/api/users/register
Content-Type: application/json
{
"username": "lisi",
"password": "abc123",
"email": "li@example.com"
}
返回:
{
"code": 200,
"msg": "注册成功",
"data": {
"user_id": 2
}
}
4.4 测试边界情况
测试1: 用户名太短
{
"username": "ab",
"password": "123456"
}
返回:
{
"detail": [
{
"loc": ["body", "username"],
"msg": "ensure this value has at least 3 characters",
"type": "value_error.any_str.min_length"
}
]
}
测试2: 重复用户名
再次提交 username: "zhangsan"
返回:
{
"code": 400,
"msg": "用户名已存在",
"data": null
}
测试3: 邮箱格式错误
{
"username": "wangwu",
"password": "123456",
"email": "not-an-email"
}
返回:
{
"detail": [
{
"loc": ["body", "email"],
"msg": "value is not a valid email address",
"type": "value_error.email"
}
]
}
5. 完整代码(可直接运行)
from fastapi import FastAPI
from pydantic import BaseModel, Field, EmailStr
from typing import Optional, Any
import hashlib
# ===== 数据模型 =====
class UserRegisterRequest(BaseModel):
"""用户注册请求模型"""
username: str = Field(..., min_length=3, max_length=50)
password: str = Field(..., min_length=6)
email: Optional[EmailStr] = None
class Config:
schema_extra = {
"example": {
"username": "zhangsan",
"password": "123456",
"email": "zhang@example.com"
}
}
class Response(BaseModel):
"""统一响应格式"""
code: int
msg: str
data: Optional[Any] = None
# ===== 响应工具类 =====
class R:
@staticmethod
def success(data: Any = None, msg: str = "操作成功"):
return Response(code=200, msg=msg, data=data)
@staticmethod
def error(msg: str = "操作失败", code: int = 500):
return Response(code=code, msg=msg, data=None)
# ===== FastAPI 应用 =====
app = FastAPI(title="我的后端 API", version="1.0.0")
# 模拟数据库
users_db = []
@app.get("/")
def root():
"""根路径"""
return {"message": "Hello World"}
@app.post("/api/users/register", response_model=Response)
def register(user: UserRegisterRequest):
"""用户注册接口"""
# 检查用户名是否存在
for existing_user in users_db:
if existing_user["username"] == user.username:
return R.error(msg="用户名已存在", code=400)
# 密码加密
password_hash = hashlib.sha256(user.password.encode()).hexdigest()
# 存入数据库
new_user = {
"user_id": len(users_db) + 1,
"username": user.username,
"password_hash": password_hash,
"email": user.email
}
users_db.append(new_user)
return R.success(
msg="注册成功",
data={"user_id": new_user["user_id"]}
)
@app.get("/api/users")
def list_users():
"""查看所有用户(测试用)"""
return R.success(data=users_db)
# ===== 启动应用 =====
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
保存为 main.py,运行:
python main.py
访问: http://localhost:8000/docs
恭喜!你已经写出了第一个真正可用的 API! 🎉
6. 理解 GET vs POST
| 特性 | GET | POST |
|---|---|---|
| 用途 | 查询数据 | 创建/提交数据 |
| 参数位置 | URL 查询参数 | 请求体(Body) |
| 是否安全 | ❌ 参数可见 | ✅ 参数隐藏 |
| 能否刷新 | ✅ 可以反复请求 | ❌ 可能重复提交 |
| 示例 | /search?q=Python | /api/users/register |
什么时候用 GET?
- 获取列表(文章列表、商品列表)
- 查询详情(用户信息、订单详情)
- 搜索功能
什么时候用 POST?
- 创建数据(注册、发布文章)
- 提交表单(登录、评论)
- 上传文件
7. 常见问题
Q1: 为什么要用 Pydantic?
A: 自动验证数据,减少 90% 的验证代码。
不用 Pydantic:
@app.post("/users/register")
def register(username, password, email):
if not username:
return {"error": "用户名不能为空"}
if len(username) < 3:
return {"error": "用户名太短"}
if len(password) < 6:
return {"error": "密码太短"}
if email and "@" not in email:
return {"error": "邮箱格式错误"}
# ... 50 行验证代码
用 Pydantic:
class UserRegisterRequest(BaseModel):
username: str = Field(..., min_length=3)
password: str = Field(..., min_length=6)
email: EmailStr = None
@app.post("/users/register")
def register(user: UserRegisterRequest):
# 到这里数据一定合法
...
Q2: 为什么要统一响应格式?
A: 前端可以统一处理响应。
// 前端代码
const response = await fetch('/api/users/register', {...});
const result = await response.json();
if (result.code === 200) {
alert(result.msg); // "注册成功"
} else {
alert(result.msg); // "用户名已存在"
}
Q3: 密码为什么要加密?
A: 数据库被黑客入侵时,用户的明文密码不会泄露。
# ❌ 明文存储
{"username": "zhangsan", "password": "123456"} # 黑客直接看到密码
# ✅ 加密存储
{"username": "zhangsan", "password_hash": "8d969eef6..."} # 黑客无法反推
Q4: 为什么 /docs 文档这么智能?
A: FastAPI 根据你的代码自动生成:
- 从
@app.post("/api/users/register")知道路径和方法 - 从
UserRegisterRequest知道参数格式 - 从
class Config: schema_extra知道示例数据 - 从
response_model=Response知道返回格式
💡 Vibe Coding 提示
到这里,你应该已经理解:
- FastAPI 怎么定义路由(
@app.get,@app.post) - 怎么接收参数(路径参数、查询参数、请求体)
- Pydantic 自动验证数据
- 怎么返回统一格式的响应
还不太懂?没关系!这很正常!
实战建议(按顺序做):
- 先跑通:把完整代码(第 5 节)复制下来,运行看效果
- 再改动:改改参数名、返回内容,看有什么变化
- 多测试:在
/docs里测试各种边界情况 - 遇到报错:
- ❌ 不要慌,不要放弃
- ✅ 复制完整错误信息
- ✅ 问 AI:“这个错误是什么意思?怎么解决?”
- ✅ 记住:报错是正常的,所有程序员每天都在报错和解决报错
关于复杂语法(@staticmethod、Optional[Any] 等):
- 你现在不需要完全理解它们
- 先记住它们的作用(比如
R.success()返回成功消息) - 具体怎么写?让 AI 帮你写
- 等写了 5-10 个接口后,你自然就懂了
Vibe Coding 核心原则:
- 能跑通 > 能背下来
- 知道工具能做什么 > 知道语法怎么写
- 会问 AI > 死记硬背
记住: 你不是在学“代码“,你是在学“用 AI 解决问题“!
AI 协作示例(遇到问题就这样问):
场景 1:想加新字段
提问:"我想在用户注册时增加一个手机号字段,要求必填,11 位数字,帮我写 Pydantic 模型代码"
场景 2:遇到报错
提问:"我运行代码时遇到这个错误:[粘贴完整错误信息],怎么解决?"
场景 3:想改功能
提问:"我想把注册接口改成登录接口,需要改哪些地方?给我完整代码"
场景 4:不懂语法
提问:"f-string 是什么意思?用生活化的例子解释一下"
📚 下一步
👉 数据库操作
学习如何用 Supabase 存储和查询真实数据,告别模拟数据库。
返回 后端开发基础 查看完整目录。
数据库操作
方法论: 数据库就是 Excel 表格,学会增删改查就够了。
📖 本节目标
学完本节,你将能够:
- ✅ 在 Supabase 创建用户表(像创建 Excel 表格一样简单)
- ✅ 理解数据库的“增删改查“(这是最核心的)
- ✅ 用 Python 代码插入/查询数据(复制粘贴就能用)
- ✅ 实现注册接口连接真实数据库(真正能用的功能)
预计用时: 40 分钟
安心提示: 这节课会出现很多代码,但你不需要记住它们!重点是理解“数据怎么存、怎么取“的逻辑,具体代码可以让 AI 帮你写。
1. 在 Supabase 创建表
1.1 回顾:数据库 = Excel
还记得第一节讲的吗?
数据库 = 一堆 Excel 表格的集合
用户表 (users)
┌────┬──────────┬─────────────────────┬──────────────┬─────────────────────┐
│ id │ username │ email │ password_hash│ created_at │
├────┼──────────┼─────────────────────┼──────────────┼─────────────────────┤
│ 1 │ zhangsan │ zhang@example.com │ abc123... │ 2025-01-15 10:30:00 │
│ 2 │ lisi │ li@example.com │ def456... │ 2025-01-15 11:00:00 │
└────┴──────────┴─────────────────────┴──────────────┴─────────────────────┘
1.2 创建用户表(users)
步骤1: 进入 Table Editor
- 登录 supabase.com
- 选择你的项目
- 左侧菜单点击 “Table Editor”
步骤2: 创建新表
- 点击 “Create a new table”
- 填写信息:
表基本信息:
- Name:
users - Description: 用户表
表字段(Columns):
| 列名 | 类型 | 默认值 | 其他设置 |
|---|---|---|---|
id | int8 | 自动生成 | ✅ Primary Key |
username | text | - | ✅ Unique, ✅ Not Null |
email | text | - | 可选 |
password_hash | text | - | ✅ Not Null |
created_at | timestamptz | now() | - |
- 点击 “Save” 创建表
成功!你的第一张表创建好了! 🎉
1.3 理解字段含义(生活化解释)
| 字段 | 类型 | 说明 | 生活化类比 |
|---|---|---|---|
| id | int8 (整数) | 主键,唯一标识每个用户 | = 身份证号 每个人独一无二 |
| username | text (文本) | 用户名,唯一不能重复 | = 你的昵称 不能和别人重复 |
text (文本) | 邮箱 | = 你的邮箱地址 可以不填 | |
| password_hash | text (文本) | 加密后的密码 | = 密码的加密形式 黑客看了也没用 |
| created_at | timestamptz (时间) | 创建时间,自动填充 | = 注册时间 自动记录,不用你管 |
看晕了没关系! 这些专业术语(int8、timestamptz)都是给数据库看的,你只需要知道:
int8= 数字(像身份证号)text= 文字(像名字)timestamptz= 时间(自动记录,还能处理时区问题)
如何让 AI 帮忙? 当你要创建新表时,直接对 AI 说:“帮我设计一个XX表,需要存XXX信息”,它会告诉你用什么类型。
2. SQL 基础 CRUD
2.1 什么是 SQL?
SQL = 和数据库对话的语言
就像你用中文和人对话,用 SQL 和数据库对话。
重要说明:为什么要学 SQL?
- SQL 是数据库的“通用语言“,会了它你就懂数据库的工作原理
- 但是写网站时,你主要会用 Python SDK(第 3 节),不需要手写 SQL
- 这里的 SQL 主要是:
- 理解概念(知道增删改查是什么)
- 调试工具(在 Supabase SQL Editor 里快速测试)
- 让 AI 帮你写(给 AI 描述需求,它会生成 SQL)
AI 协作提示:你可以对 AI 说:“帮我写一个 SQL 查询,找出所有邮箱不为空的用户”,它会直接生成代码。
2.2 插入数据(INSERT)
语法:
INSERT INTO 表名 (列1, 列2, 列3)
VALUES (值1, 值2, 值3);
实际例子(在 Supabase SQL Editor 运行):
- 左侧菜单点击 “SQL Editor”
- 点击 “New query”
- 输入:
INSERT INTO users (username, email, password_hash)
VALUES ('zhangsan', 'zhang@example.com', 'abc123hashed');
- 点击 “Run” 或按
Ctrl+Enter
成功! 刷新 Table Editor,应该能看到新增的数据。
2.3 查询数据(SELECT)
查询所有用户:
SELECT * FROM users;
条件查询(查找用户名为 zhangsan 的用户):
SELECT * FROM users WHERE username = 'zhangsan';
只查询特定字段:
SELECT id, username, email FROM users;
排序(按创建时间倒序):
SELECT * FROM users ORDER BY created_at DESC;
限制返回数量(只返回前 10 条):
SELECT * FROM users LIMIT 10;
组合使用:
SELECT id, username, email
FROM users
WHERE email IS NOT NULL
ORDER BY created_at DESC
LIMIT 10;
2.4 更新数据(UPDATE)
语法:
UPDATE 表名
SET 列1 = 新值1, 列2 = 新值2
WHERE 条件;
实际例子:
UPDATE users
SET email = 'new_email@example.com'
WHERE username = 'zhangsan';
⚠️ 重要: WHERE 条件一定要写!否则会更新所有行!
2.5 删除数据(DELETE)
语法:
DELETE FROM 表名 WHERE 条件;
实际例子:
DELETE FROM users WHERE id = 1;
⚠️ 危险: 实际项目建议用“软删除“(添加 is_deleted 字段),而不是真删除。
3. 用 Python 连接 Supabase
这才是重点! 从这里开始,你会学到在真实项目中如何用 Python 操作数据库。前面的 SQL 你看懂概念就行,具体写代码主要用这节的方法。
3.0 文件结构说明(先看这里!)
在开始写代码前,我们要建立这样的文件夹结构:
我的项目/
├── db_config.py # 数据库连接配置(专门存 Supabase URL 和 Key)
├── main.py # 主程序(你的 FastAPI 应用)
└── test_db.py # 测试文件(测试数据库连接,测完可以删)
为什么要分文件?
db_config.py:把密码(Key)单独放一个文件,安全+方便管理main.py:主程序,这里写你的接口代码test_db.py:先用这个文件测试能不能连上数据库,测通了再写主程序
3.1 安装 Supabase 库
pip install supabase
如果报错怎么办?(常见问题)
报错 1: pip: command not found
- 原因: Python 没装好或者环境变量没配置
- AI 提示: 复制这个报错,问 AI:“我运行 pip install supabase 报错了:[粘贴报错内容],怎么办?”
报错 2: ERROR: Could not find a version...
- 原因: 网络问题或者拼写错误
- 解决: 检查网络,确认命令拼写正确,或者换个镜像源(问 AI:“pip 安装报错怎么换镜像源?”)
3.2 获取连接信息
在 Supabase 项目中:
- 点击左侧 “Settings”(齿轮图标)
- 点击 “API”
- 找到这两个信息:
- Project URL:
https://xxx.supabase.co - anon public key: 一串很长的字符串
- Project URL:
3.3 创建连接
创建 db_config.py(在项目文件夹里新建这个文件):
from supabase import create_client, Client
# Supabase 连接配置
SUPABASE_URL = "https://xxx.supabase.co" # 替换成你的 URL
SUPABASE_KEY = "eyJhbGciOiJIUzI1NiIsInR5cCI..." # 替换成你的 Key
# 创建客户端
supabase: Client = create_client(SUPABASE_URL, SUPABASE_KEY)
代码解释(你需要懂的逻辑):
SUPABASE_URL和SUPABASE_KEY:这是你家门牌号+钥匙,告诉 Python “去哪里找数据库”create_client:这行代码建立连接,就像拿着钥匙开门supabase:这是连接对象,后面所有操作都通过它
你不需要懂的语法细节(让 AI 写就行):
: Client是什么?(类型注解,机器看的,你不用管)create_client的实现原理?(底层封装,你不用管)
AI 协作提示:如果 Key 填错了连不上,复制报错信息问 AI:“我的 Supabase 连接报错了:[报错内容],怎么检查?”
安全提示(重要!):
- 这个
SUPABASE_KEY是你的数据库钥匙,不要分享给别人! - 如果要把代码上传到 GitHub 或发给朋友,记得:
- 先创建一个
.gitignore文件,里面写上db_config.py(这样 Git 就不会上传它) - 或者分享代码时把 Key 删掉,只留个示例:“替换成你的 Key”
- 先创建一个
- 如果不小心泄露了 Key,去 Supabase 项目设置里重新生成一个新的(别担心,很简单)
3.4 插入数据
创建 test_db.py:
from db_config import supabase
# 插入一条用户数据
data = {
"username": "test_user",
"email": "test@example.com",
"password_hash": "hashed_password_123"
}
response = supabase.table('users').insert(data).execute()
print("插入成功!")
print("新用户 ID:", response.data[0]['id'])
运行:
python test_db.py
3.5 查询数据
from db_config import supabase
# 查询所有用户
response = supabase.table('users').select("*").execute()
print("所有用户:")
for user in response.data:
print(f"ID: {user['id']}, 用户名: {user['username']}")
# 条件查询
response = supabase.table('users').select("*").eq('username', 'zhangsan').execute()
if response.data:
print("找到用户:", response.data[0])
else:
print("用户不存在")
3.6 更新数据
from db_config import supabase
# 更新用户邮箱
supabase.table('users').update({
"email": "new_email@example.com"
}).eq('username', 'zhangsan').execute()
print("更新成功!")
3.7 删除数据
from db_config import supabase
# 删除用户
supabase.table('users').delete().eq('id', 1).execute()
print("删除成功!")
4. 实战:用户注册连接数据库
4.1 完整代码
db_config.py (数据库配置):
from supabase import create_client, Client
SUPABASE_URL = "https://xxx.supabase.co" # 替换
SUPABASE_KEY = "eyJhbGciOiJIUzI1NiIsInR5cCI..." # 替换
supabase: Client = create_client(SUPABASE_URL, SUPABASE_KEY)
main.py (主程序):
from fastapi import FastAPI
from pydantic import BaseModel, Field, EmailStr
from typing import Optional, Any
import hashlib
from db_config import supabase
# ===== 数据模型 =====
class UserRegisterRequest(BaseModel):
username: str = Field(..., min_length=3, max_length=50)
password: str = Field(..., min_length=6)
email: Optional[EmailStr] = None
class Response(BaseModel):
code: int
msg: str
data: Optional[Any] = None
class R:
@staticmethod
def success(data: Any = None, msg: str = "操作成功"):
return Response(code=200, msg=msg, data=data)
@staticmethod
def error(msg: str = "操作失败", code: int = 500):
return Response(code=code, msg=msg, data=None)
# ===== FastAPI 应用 =====
app = FastAPI(title="我的后端 API", version="1.0.0")
@app.post("/api/users/register", response_model=Response)
def register(user: UserRegisterRequest):
"""用户注册接口(连接真实数据库)"""
# 1. 检查用户名是否已存在
existing_user = supabase.table('users').select("*").eq('username', user.username).execute()
if existing_user.data:
return R.error(msg="用户名已存在", code=400)
# 2. 密码加密
password_hash = hashlib.sha256(user.password.encode()).hexdigest()
# 3. 插入数据库
try:
new_user = supabase.table('users').insert({
"username": user.username,
"email": user.email,
"password_hash": password_hash
}).execute()
return R.success(
msg="注册成功",
data={"user_id": new_user.data[0]['id']}
)
except Exception as e:
return R.error(msg=f"注册失败: {str(e)}", code=500)
@app.get("/api/users", response_model=Response)
def list_users():
"""查看所有用户"""
response = supabase.table('users').select("id, username, email, created_at").execute()
return R.success(data=response.data)
@app.get("/api/users/{user_id}", response_model=Response)
def get_user(user_id: int):
"""获取单个用户信息"""
response = supabase.table('users').select("*").eq('id', user_id).execute()
if not response.data:
return R.error(msg="用户不存在", code=404)
return R.success(data=response.data[0])
# ===== 启动应用 =====
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
4.2 测试
启动应用:
python main.py
测试注册(访问 http://localhost:8000/docs):
POST /api/users/register
{
"username": "xiaoming",
"password": "123456",
"email": "xiaoming@example.com"
}
成功响应:
{
"code": 200,
"msg": "注册成功",
"data": {
"user_id": 3
}
}
在 Supabase Table Editor 查看,应该能看到新增的用户!
5. SQLAlchemy ORM 入门(进阶,初学者可跳过)
重要提示:新手可以直接跳过这一节! 前面学的 Supabase SDK 已经完全够用了。这一节是给以后想深入了解的人准备的。
5.1 什么是 ORM?
ORM = Object-Relational Mapping(对象关系映射)
通俗解释(翻译官类比):
想象你要和一个只会德语的人交流,但你不会德语:
- 不用 ORM:你得先学德语,然后写德语句子(= 手写 SQL 语句)
- 用 ORM:你找了个翻译官,你说中文(= 写 Python 对象),翻译官自动帮你翻译成德语(= ORM 自动生成 SQL)
你的代码:user = User(username='zhangsan')
↓ (ORM 自动翻译)
SQL语句:INSERT INTO users (username) VALUES ('zhangsan')
5.2 为什么这一节可以跳过?
| 场景 | Supabase SDK | SQLAlchemy ORM |
|---|---|---|
| 学习难度 | ✅ 简单(5 分钟上手) | ❌ 复杂(需要学模型定义) |
| 适用数据库 | 只能用 Supabase | 任何 SQL 数据库 |
| 是否够用 | ✅ 小项目完全够 | 大公司/复杂项目才需要 |
建议:现在用 Supabase SDK 就行,等你做大项目或者公司要求用本地数据库时,再回来学这一节。
想了解的同学点这里展开(可选)
5.3 安装 SQLAlchemy
pip install sqlalchemy psycopg2-binary
5.4 定义模型
创建 models/user.py:
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class User(Base):
"""用户表模型"""
__tablename__ = "users"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), unique=True, nullable=False)
email = Column(String(100))
password_hash = Column(String(255), nullable=False)
created_at = Column(DateTime, default=datetime.utcnow)
def to_dict(self):
"""转换为字典"""
return {
"id": self.id,
"username": self.username,
"email": self.email,
"created_at": self.created_at.isoformat() if self.created_at else None
}
5.4 使用 ORM(示例)
注意: Supabase Python SDK 已经很方便了,ORM 主要用于更复杂的场景(本地 PostgreSQL、MySQL 等)。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models.user import User
# 连接数据库(需要 PostgreSQL 连接字符串)
DATABASE_URL = "postgresql://user:password@host:5432/database"
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(bind=engine)
# 使用
db = SessionLocal()
# 创建用户
new_user = User(
username="zhangsan",
email="zhang@example.com",
password_hash="hashed_password"
)
db.add(new_user)
db.commit()
# 查询用户
user = db.query(User).filter(User.username == "zhangsan").first()
print(user.to_dict())
# 关闭连接
db.close()
再次提醒:初学者真的不需要看这一节!用 Supabase SDK 就够了。
6. 常见问题
Q1: Supabase SDK 和 SQLAlchemy 有什么区别?
A:
| 特性 | Supabase SDK | SQLAlchemy ORM |
|---|---|---|
| 简单度 | ✅ 简单直接 | ⚠️ 需要定义模型 |
| 学习成本 | 低 | 中等 |
| 适用场景 | Supabase 云数据库 | 任何 SQL 数据库 |
| 推荐 | 新手/小项目 | 大项目/本地数据库 |
建议: 本项目用 Supabase SDK 就够了。
Q2: 为什么不把密码明文存储?
A: 数据库被黑客入侵时,用户密码不会泄露。
# ❌ 明文
password = "123456" # 黑客直接看到
# ✅ 加密
password_hash = "8d969eef6ecad3c29a3a629280e686cf0c3f5d5..." # 无法反推原密码
Q3: created_at 时间不对怎么办?
A: Supabase 默认用 UTC 时间,需要转换成本地时间。
from datetime import datetime, timezone
# UTC 转北京时间(+8 小时)
created_at_utc = user['created_at'] # "2025-01-15T02:30:00Z"
created_at_local = datetime.fromisoformat(created_at_utc.replace('Z', '+00:00'))
created_at_beijing = created_at_local.astimezone(timezone(timedelta(hours=8)))
Q4: 如何防止 SQL 注入?
A: 用 Supabase SDK 或 ORM,不要自己拼接 SQL。
# ❌ 危险(可能被 SQL 注入)
username = request.username
query = f"SELECT * FROM users WHERE username = '{username}'"
# ✅ 安全(使用参数化查询)
supabase.table('users').select("*").eq('username', username).execute()
💡 Vibe Coding 提示
到这里,你应该已经理解:
- 数据库就是 Excel 表格(这是核心理解)
- SQL 是增删改查的语言(懂概念就行,不用背)
- Supabase SDK 操作数据库很简单(复制代码改改就能用)
- 用户注册接口可以连接真实数据库了(你做出来真东西了!)
还不太懂?没关系!这样做:
-
先跑通代码:
- 把上面的代码复制下来
- 替换你自己的 Supabase URL 和 Key
- 运行一遍,看看能不能成功
-
遇到报错不要慌:
- 复制完整的报错信息
- 问 AI:“我运行XX代码报错了:[粘贴报错],怎么解决?”
- AI 会告诉你具体问题在哪里
-
用 AI 帮你写代码:
- 不需要记住语法!
- 当你想加新功能时,对 AI 说:“帮我写一个查询所有用户的 Python 代码,用 Supabase SDK”
- 把 AI 生成的代码复制进去,测试一下就行
-
验证 AI 写得对不对:
- 运行代码,看看结果对不对
- 去 Supabase Table Editor 看看数据有没有变化
- 如果不对,把结果告诉 AI,它会帮你调整
记住 Vibe Coding 的核心:
- 你需要理解“为什么这样做“(比如为什么要加密密码)
- 具体语法让 AI 帮你写(比如
supabase.table().insert()的写法) - 数据库只是存数据的地方,别被技术术语吓到
AI 协作清单(收藏这个!):
- “帮我设计一个XX表,需要存储XXX信息”(设计表结构)
- “帮我写一个查询XX的 Python 代码,用 Supabase SDK”(写查询代码)
- “我的代码报错了:[报错内容],怎么办?”(调试报错)
- “这段代码是什么意思:[粘贴代码]”(理解代码逻辑)
- “怎么验证这个功能是不是正常的?”(测试验证)
📚 下一步
👉 完整功能实现
学习三层架构、JWT 认证,实现生产级别的后端代码。
返回 后端开发基础 查看完整目录。
完整功能实现
核心理念: 我们不是在学“写代码“,而是在学“用 AI 搭建系统“!
这一节会教你如何像设计师一样思考项目结构,然后让 AI 帮你填充代码细节。
📖 本节目标
学完本节,你将能够:
- ✅ 理解为什么要用三层架构(而不是死记硬背)
- ✅ 知道 JWT Token 和密码加密是什么、解决什么问题(AI 会帮你写具体代码)
- ✅ 学会用 AI 生成 Router/Service/DAO 的代码
- ✅ 看懂报错日志,知道该问 AI 什么问题
- ✅ 实现完整的用户注册+登录+验证流程(能跑起来就是成功!)
预计用时: 50 分钟(其中 40 分钟是让 AI 写代码,10 分钟是你理解架构)
💡 Vibe Coding 提醒
重要!开始前请记住:
- 这一节的代码很多都不需要你手写,看到复杂语法不要慌
- 我们会明确标注哪些部分“让 AI 写“,哪些部分“你需要理解“
- 如果遇到报错,先别急着放弃,报错信息就是给 AI 的“线索卡片“
1. 为什么要分层?(🎯 第一性原理:设计思维)
1.1 先别急着否定“简单代码“
之前你可能见过这样的代码(所有东西挤在一起):
@app.post("/api/users/register")
def register(data: UserRegisterRequest):
# 看起来很直观对吧?一眼就能看完整个流程
existing_user = supabase.table('users').select("*").eq('username', data.username).execute()
if existing_user.data:
return {"code": 400, "msg": "用户名已存在"}
password_hash = hashlib.sha256(data.password.encode()).hexdigest()
supabase.table('users').insert({
"username": data.username,
"password_hash": password_hash
}).execute()
return {"code": 200, "msg": "注册成功"}
✅ 对于初学者,这样写完全OK! 如果你只需要做一个简单的小网站(比如只有 3-5 个功能),这样写没问题。
1.2 但如果你想做“正经项目“,就需要“整理柜子“
现实问题:
- 就像把牙刷、衣服、锅碗瓢盆都塞进一个抽屉,刚开始还行,东西多了就乱套了
- 当你的网站有 20+ 个功能时,所有代码挤在一起会变成“意大利面条代码“,自己都找不到哪里出问题
三层架构 = 给柜子分格子:
用户请求 → Router(服务员) → Service(厨师) → DAO(仓库管理员) → 数据库
↓ ↓ ↓
返回响应 ← Router ← Service(做好菜) ← DAO(取到食材)
餐厅类比 (参考资料):
| 层次 | 职责 | 餐厅类比 | 真实工作 |
|---|---|---|---|
| Router | 接收请求、返回响应 | 服务员(点菜、上菜) | 接收用户的注册请求,返回“注册成功“ |
| Service | 业务逻辑处理 | 厨师(决定怎么做菜) | 检查用户名是否重复、密码加密 |
| DAO | 数据库操作 | 仓库管理员(取食材) | 从数据库查数据、往数据库存数据 |
关键理解:服务员不用懂厨师怎么炒菜,厨师不用懂仓库管理员怎么进货。他们各干各的,互不干扰。
1.3 为什么选三层而不是两层或四层?
设计思维:
- 两层不够:如果只有 Router 和数据库,那 Router 既要管接待客人,又要管做菜,又要管进货,太累了
- 四层太多:增加复杂度,小项目没必要
- 三层刚刚好:职责清晰,又不会过度设计
记住:这个架构不是“死规矩“,而是前人总结的“最佳实践“。你理解了原理,以后可以根据项目大小灵活调整。
2. 项目结构(🎯 第一性原理:框架理解)
2.1 先建立“脚手架“
下面是完整的项目结构。不要被吓到! 这些文件夹就像是搭积木前先摆好的空盒子。
my-backend/
├── main.py # 应用入口(房子的大门)
├── db_config.py # 数据库配置(水电开关)
├── routers/ # 路由层(接待处)
│ └── user_router.py
├── services/ # 服务层(工作室)
│ └── user_service.py
├── dao/ # 数据访问层(仓库)
│ └── user_dao.py
├── models/ # 数据模型(图纸)
│ └── user_model.py
├── utils/ # 工具类(工具箱)
│ ├── response.py # 统一响应(对讲机)
│ └── auth.py # JWT 认证(门禁卡)
└── requirements.txt # 依赖包(材料清单)
数据流向(框架理解核心):
1. 用户发请求 → main.py 收到
2. main.py 找到 user_router.py(服务员)
3. user_router 调用 user_service.py(厨师)
4. user_service 调用 user_dao.py(仓库)
5. user_dao 从 Supabase 数据库取数据
6. 数据原路返回 → 最终用户收到响应
2.2 🤖 让 AI 帮你创建文件结构
Vibe Coding 核心技巧:不要手动一个个建文件,用 AI!
复制这段话给 ChatGPT/Claude:
我要创建一个 FastAPI 后端项目,使用三层架构(Router/Service/DAO)。
请帮我生成创建以下文件夹结构的 shell 命令(适用于 Windows/Mac/Linux):
my-backend/
├── main.py
├── db_config.py
├── routers/
│ └── user_router.py
├── services/
│ └── user_service.py
├── dao/
│ └── user_dao.py
├── models/
│ └── user_model.py
├── utils/
│ ├── response.py
│ └── auth.py
└── requirements.txt
同时,请为每个 Python 文件生成一个最基本的空模板(只包含必要的 import 和注释),让我知道每个文件是干什么的。
AI 会返回:
- 创建文件夹的命令(如
mkdir -p routers services dao models utils) - 每个文件的空模板代码
- 你只需要复制粘贴运行即可!
2.3 理解术语(工具认知)
看到这些文件夹名可能会蒙,我们来用人话解释:
| 术语 | 人话解释 | 通俗比喻 |
|---|---|---|
| Router | 路由器 = 网址分配器 | 就像邮局,看地址(URL)把信送到对应部门 |
| Service | 服务 = 干活的部门 | 公司里的各个部门(人事部、财务部) |
| DAO | Data Access Object = 数据库搬运工 | 仓库管理员,只负责拿东西和放东西 |
| Model | 模型 = 数据的格式说明书 | 快递单上的格式(姓名、电话、地址) |
| utils | 工具 = 通用小工具 | 瑞士军刀,到处都能用 |
DAO 这个词特别迷惑:它的全称是 “Data Access Object”(数据访问对象),但你可以直接理解为**“数据库操作员”** —— 只有它有数据库的钥匙。
3. 核心概念速通(🎯 第一性原理:工具认知)
在看代码之前,先理解这些工具是干嘛的。记住:你只需要理解概念,具体语法让 AI 写!
3.1 JWT Token = 游乐园手环
问题:用户登录后,怎么证明“他还是他“?
传统方案(Session):
- 像银行给你一张存折,每次来都要查你的账户(服务器要记住每个人)
- 缺点:服务器累,用户多了就卡
现代方案(JWT Token) (详细解释):
- 就像游乐园的手环 (参考)
- 你买完票,工作人员给你手腕上戴个手环(这就是 Token)
- 之后你玩每个项目,只需要出示手环,工作人员验证后就让你通过
- 关键:手环上印着“有效期到今天晚上8点“,过期就得重新买票
JWT 的三部分(看不懂这些字母没关系,让 AI 写):
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImV4cCI6MTcwMDAwMDAwMH0.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
───────────────────────────────── ────────────────────────────────────── ──────────────────────────────────────
Header(头部) Payload(内容) Signature(签名,防伪码)
说明加密算法 存用户ID、过期时间等 防止有人伪造手环
你需要理解的:
- ✅ JWT 是一串加密字符串,像身份凭证
- ✅ 登录成功后,服务器给用户发 Token
- ✅ 用户后续请求都要带上这个 Token(放在请求头 Header 里)
- ❌ 你不需要记住怎么写 JWT 的代码(让 AI 写!)
3.2 bcrypt 密码加密 = 把鸡蛋打碎做蛋饼
问题:用户密码怎么存?直接存 “123456” 会被黑客看光!
加密对比 (安全性解释):
| 方式 | 安全性 | 比喻 | 问题 |
|---|---|---|---|
| 明文 | ❌ 危险 | 密码写在纸上贴墙上 | 数据库泄露 = 所有密码泄露 |
| MD5/SHA256 | ⚠️ 一般 | 把密码打碎成粉末 | 相同密码打出来的粉末一样,可以用“彩虹表“破解 |
| bcrypt | ✅ 安全 | 每次打碎都加不同调料 | 同一密码每次加密结果都不同,黑客无法暴力破解 |
bcrypt 神奇的地方 (原理):
# 同一个密码 "123456",每次加密结果都不同!
hash1 = bcrypt.hash("123456")
# 结果:$2b$12$abc123...xyz789
hash2 = bcrypt.hash("123456")
# 结果:$2b$12$def456...uvw012 (完全不一样!)
# 但验证时都能认出来是 "123456"
bcrypt.verify("123456", hash1) # True
bcrypt.verify("123456", hash2) # True
就像做蛋饼:
- 你无法从蛋饼还原成生鸡蛋(单向不可逆)
- 每次做蛋饼加的调料不一样,看起来不同
- 但你尝一口就知道“这是用鸡蛋做的“(能验证)
你需要理解的:
- ✅ 密码必须加密存储,绝不能明文
- ✅ bcrypt 很安全,因为“每次结果都不同“
- ✅ bcrypt 故意设计得“慢一点“(0.1秒),让黑客破解时要花几百年
- ❌ 你不需要记 bcrypt 的 API(让 AI 写!)
3.3 🤖 AI 协作策略
接下来我们要写很多代码文件,但你不需要手写!
分工原则:
- 你负责:理解每个文件是干嘛的(Router/Service/DAO 的职责)
- AI 负责:写具体的代码语法
给 AI 的 Prompt 模板(复制修改使用):
我正在用 FastAPI + Supabase 开发后端,使用三层架构。
请帮我生成 [文件名] 的代码,需求如下:
1. [具体功能描述,比如"实现用户注册,检查用户名是否重复"]
2. 使用 bcrypt 加密密码
3. [其他特殊要求]
请包含完整的类型注解和中文注释。
示例:
我正在用 FastAPI + Supabase 开发后端,使用三层架构。
请帮我生成 services/user_service.py 的代码,需求如下:
1. 实现用户注册功能:检查用户名是否重复,使用 bcrypt 加密密码,调用 UserDAO 存储
2. 实现用户登录功能:验证密码,生成 JWT Token
3. 使用 python-jose 生成 JWT,密钥设为 "your-secret-key",有效期 7 天
请包含完整的类型注解和中文注释。
4. 完整代码实现(跟着 AI 一起搭建)
说明:下面的每个代码块会标注:
- 🤖 让 AI 写:复杂语法,直接复制或让 AI 生成
- 🧠 你需要理解:核心逻辑,必须看懂这部分在干嘛
- ⚙️ 改这里:你需要修改的配置(如数据库地址)
4.1 配置文件
db_config.py (数据库配置):
⚙️ 改这里 - 把 Supabase URL 和 Key 换成你的:
from supabase import create_client, Client
SUPABASE_URL = "https://xxx.supabase.co" # 替换
SUPABASE_KEY = "eyJhbGciOiJIUzI1NiIsInR5cCI..." # 替换
supabase: Client = create_client(SUPABASE_URL, SUPABASE_KEY)
4.2 统一响应格式
utils/response.py:
🧠 你需要理解:这个文件定义了“对讲机的统一格式“,所有接口返回的数据都用这个格式。
from typing import Optional, Any
from pydantic import BaseModel
class Response(BaseModel):
"""统一响应格式"""
code: int # 业务状态码
msg: str # 提示信息
data: Optional[Any] = None # 返回数据
class R:
"""响应工具类"""
@staticmethod
def success(data: Any = None, msg: str = "操作成功"):
return Response(code=200, msg=msg, data=data)
@staticmethod
def error(msg: str = "操作失败", code: int = 500):
return Response(code=code, msg=msg, data=None)
3.3 JWT 认证工具
安装依赖:
pip install python-jose[cryptography] passlib[bcrypt]
utils/auth.py:
from datetime import datetime, timedelta
from jose import JWTError, jwt
from passlib.context import CryptContext
from typing import Optional
# JWT 配置
SECRET_KEY = "your-secret-key-here" # 生产环境要用复杂的密钥
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_DAYS = 7
# 密码加密
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def hash_password(password: str) -> str:
"""密码加密"""
return pwd_context.hash(password)
def verify_password(plain_password: str, hashed_password: str) -> bool:
"""验证密码"""
return pwd_context.verify(plain_password, hashed_password)
def create_access_token(data: dict, expires_delta: Optional[timedelta] = None):
"""生成 JWT Token"""
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(days=ACCESS_TOKEN_EXPIRE_DAYS)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
def decode_access_token(token: str) -> Optional[dict]:
"""解析 JWT Token"""
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
return payload
except JWTError:
return None
3.4 数据模型
models/user_model.py:
from pydantic import BaseModel, Field, EmailStr
from typing import Optional
class UserRegisterRequest(BaseModel):
"""用户注册请求"""
username: str = Field(..., min_length=3, max_length=50)
password: str = Field(..., min_length=6)
email: Optional[EmailStr] = None
class UserLoginRequest(BaseModel):
"""用户登录请求"""
username: str = Field(..., min_length=3)
password: str = Field(..., min_length=6)
class UserResponse(BaseModel):
"""用户响应(不返回密码)"""
id: int
username: str
email: Optional[str]
created_at: str
3.5 DAO 层(数据访问层)
dao/user_dao.py:
from typing import Optional, Dict, Any
from db_config import supabase
class UserDAO:
"""
用户数据访问对象
职责:只负责数据库 CRUD 操作
"""
@staticmethod
def create(data: Dict[str, Any]) -> int:
"""创建用户"""
response = supabase.table('users').insert(data).execute()
return response.data[0]['id']
@staticmethod
def get_by_username(username: str) -> Optional[Dict[str, Any]]:
"""根据用户名查询用户"""
response = supabase.table('users').select("*").eq('username', username).execute()
return response.data[0] if response.data else None
@staticmethod
def get_by_id(user_id: int) -> Optional[Dict[str, Any]]:
"""根据 ID 查询用户"""
response = supabase.table('users').select("*").eq('id', user_id).execute()
return response.data[0] if response.data else None
@staticmethod
def list_all() -> list:
"""查询所有用户"""
response = supabase.table('users').select("id, username, email, created_at").execute()
return response.data
3.6 Service 层(服务层)
services/user_service.py:
from dao.user_dao import UserDAO
from utils.auth import hash_password, verify_password, create_access_token
class UserService:
"""
用户业务逻辑层
职责:业务逻辑处理、数据验证、密码加密等
"""
@staticmethod
def register(username: str, password: str, email: str = None) -> int:
"""
用户注册
Returns:
新创建的用户 ID
Raises:
Exception: 用户名已存在
"""
dao = UserDAO()
# 1. 检查用户名是否存在
if dao.get_by_username(username):
raise Exception("用户名已存在")
# 2. 密码加密
password_hash = hash_password(password)
# 3. 调用 DAO 创建用户
user_id = dao.create({
"username": username,
"password_hash": password_hash,
"email": email
})
return user_id
@staticmethod
def login(username: str, password: str) -> dict:
"""
用户登录
Returns:
包含 token 和用户信息的字典
Raises:
Exception: 用户名或密码错误
"""
dao = UserDAO()
# 1. 查询用户
user = dao.get_by_username(username)
if not user:
raise Exception("用户名或密码错误")
# 2. 验证密码
if not verify_password(password, user['password_hash']):
raise Exception("用户名或密码错误")
# 3. 生成 Token
token = create_access_token(data={"user_id": user['id'], "username": user['username']})
return {
"token": token,
"user": {
"id": user['id'],
"username": user['username'],
"email": user['email']
}
}
@staticmethod
def get_user_info(user_id: int) -> dict:
"""
获取用户信息
Raises:
Exception: 用户不存在
"""
dao = UserDAO()
user = dao.get_by_id(user_id)
if not user:
raise Exception("用户不存在")
return {
"id": user['id'],
"username": user['username'],
"email": user['email'],
"created_at": user['created_at']
}
3.7 Router 层(路由层)
routers/user_router.py:
from fastapi import APIRouter, Depends, HTTPException, Header
from models.user_model import UserRegisterRequest, UserLoginRequest
from services.user_service import UserService
from utils.response import R, Response
from utils.auth import decode_access_token
from typing import Optional
router = APIRouter(prefix="/api/users", tags=["用户管理"])
@router.post("/register", response_model=Response)
def register(data: UserRegisterRequest):
"""
用户注册接口
职责:
1. 接收请求参数
2. 调用服务层
3. 返回统一响应
"""
try:
user_id = UserService.register(
username=data.username,
password=data.password,
email=data.email
)
return R.success(msg="注册成功", data={"user_id": user_id})
except Exception as e:
return R.error(msg=str(e), code=400)
@router.post("/login", response_model=Response)
def login(data: UserLoginRequest):
"""用户登录接口"""
try:
result = UserService.login(
username=data.username,
password=data.password
)
return R.success(msg="登录成功", data=result)
except Exception as e:
return R.error(msg=str(e), code=400)
def get_current_user(authorization: Optional[str] = Header(None)):
"""
获取当前登录用户(依赖项)
用法:
@router.get("/profile")
def get_profile(user: dict = Depends(get_current_user)):
return R.success(data=user)
"""
if not authorization:
raise HTTPException(status_code=401, detail="未登录")
# 提取 Token(格式:Bearer xxx)
token = authorization.replace("Bearer ", "")
# 验证 Token
payload = decode_access_token(token)
if not payload:
raise HTTPException(status_code=401, detail="Token 无效或已过期")
return payload # 返回 {"user_id": 123, "username": "zhangsan"}
@router.get("/profile", response_model=Response)
def get_profile(current_user: dict = Depends(get_current_user)):
"""获取当前用户信息(需要登录)"""
try:
user_info = UserService.get_user_info(current_user['user_id'])
return R.success(data=user_info)
except Exception as e:
return R.error(msg=str(e), code=404)
@router.get("/list", response_model=Response)
def list_users():
"""查看所有用户(公开接口)"""
from dao.user_dao import UserDAO
users = UserDAO.list_all()
return R.success(data=users)
3.8 主程序入口
main.py:
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from routers import user_router
app = FastAPI(
title="我的后端 API",
description="使用三层架构的 FastAPI 项目",
version="1.0.0"
)
# CORS 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境要改成具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(user_router.router)
@app.get("/")
def root():
return {"message": "Hello World", "docs": "/docs"}
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
3.9 依赖文件
requirements.txt:
fastapi
uvicorn[standard]
supabase
pydantic[email]
python-jose[cryptography]
passlib[bcrypt]
5. 报错不要慌!(🎯 第一性原理:问题定位)
重要心态调整:报错不是“失败“,而是系统在告诉你“哪里需要修复“。把报错信息当成AI 的线索卡片。
5.1 常见报错速查表
| 报错信息 | 人话翻译 | 责任归属 | 怎么办 |
|---|---|---|---|
ModuleNotFoundError: No module named 'xxx' | 缺少某个库 | 你的环境 | 运行 pip install xxx |
ImportError: cannot import name 'xxx' | 文件导入路径错了 | 你的代码 | 检查文件名和 import 语句 |
401 Unauthorized | Token 无效或过期 | 前端或用户 | 重新登录获取新 Token |
500 Internal Server Error | 服务器内部错误 | 后端代码 | 看终端日志,找具体错误行 |
connection refused | 数据库连不上 | 配置问题 | 检查 db_config.py 的 URL 和 Key |
5.2 怎么看报错日志?
示例报错:
Traceback (most recent call last):
File "/app/services/user_service.py", line 25, in register
user_id = dao.create({...})
File "/app/dao/user_dao.py", line 15, in create
response = supabase.table('users').insert(data).execute()
KeyError: 'id'
解读方法(从下往上看):
- 最后一行(
KeyError: 'id'):关键错误信息 = “找不到 ‘id’ 这个键” - 倒数第二行(
dao.py line 15):出错的具体位置 - 推理:Supabase 返回的数据里没有 ‘id’ 字段,可能是数据库表结构不对
🤖 把报错丢给 AI 的 Prompt:
我在运行 FastAPI + Supabase 项目时遇到以下报错:
[把完整报错信息粘贴在这里]
我的代码是这样的:
[粘贴出错的那几行代码]
请帮我分析原因并提供解决方案。
5.3 三层架构的报错定位
根据报错文件名判断是哪一层的问题:
报错文件 → 可能原因
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
user_router.py → 请求参数格式不对,或者调用 Service 的方式错了
user_service.py → 业务逻辑有问题(比如验证密码的逻辑错了)
user_dao.py → 数据库操作有问题(表名、字段名不对)
db_config.py → 数据库连接配置错误
auth.py → JWT 或密码加密的配置有问题
调试技巧:在怀疑的地方加 print() 或 logger.debug(),看看变量的值对不对。
5.4 验证 AI 代码的方法
问题:AI 写的代码怎么知道对不对?
验证清单:
- ✅ 能运行:
python main.py不报错,能访问/docs - ✅ 逻辑对:测试注册/登录流程,符合预期
- ✅ 错误处理:故意输入错误数据(如重复用户名),看能否正确返回错误信息
- ✅ 安全性:密码在数据库里是加密的(不是明文 “123456”)
如果 AI 代码有问题,这样问它:
你之前生成的 user_service.py 代码在测试时出现了 [具体问题描述]。
预期行为:[应该怎样]
实际行为:[实际怎样]
报错信息:[如果有]
请帮我修复这个问题。
6. 完整流程测试
6.1 启动应用
python main.py
访问 http://localhost:8000/docs
预期结果:看到 FastAPI 的自动文档界面,左侧列出了所有接口。
6.2 测试注册
POST /api/users/register
{
"username": "testuser",
"password": "123456",
"email": "test@example.com"
}
返回:
{
"code": 200,
"msg": "注册成功",
"data": {
"user_id": 1
}
}
6.3 测试登录
POST /api/users/login
{
"username": "testuser",
"password": "123456"
}
返回:
{
"code": 200,
"msg": "登录成功",
"data": {
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"user": {
"id": 1,
"username": "testuser",
"email": "test@example.com"
}
}
}
复制 token 备用!
6.4 测试获取用户信息(需要登录)
请求:
GET /api/users/profile
Headers:
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
⚠️ 注意:Bearer 后面有个空格,别漏了!
在 /docs 中测试:
- 点击
GET /api/users/profile - 点击右上角 “Authorize” 锁头图标
- 在弹出框输入:
Bearer 你刚才复制的token(注意 Bearer 和 token 之间有空格) - 点击 “Authorize” 按钮
- 点击 “Try it out” → “Execute”
返回:
{
"code": 200,
"msg": "操作成功",
"data": {
"id": 1,
"username": "testuser",
"email": "test@example.com",
"created_at": "2025-01-15T10:30:00Z"
}
}
7. 理解三层架构(回顾与总结)
7.1 完整调用链路
用户注册的完整流程:
1. 用户请求
POST /api/users/register
{username: "zhangsan", password: "123456"}
2. Router 层(user_router.py)
├─ 接收请求参数
├─ 调用 UserService.register()
└─ 返回统一响应 R.success()
3. Service 层(user_service.py)
├─ 检查用户名是否存在(调用 DAO)
├─ 密码加密(hash_password)
├─ 调用 UserDAO.create()
└─ 返回用户 ID
4. DAO 层(user_dao.py)
├─ 执行数据库插入
└─ 返回新用户 ID
5. 数据库(Supabase)
└─ 存储用户数据
7.2 分层的好处
1. 单一职责:
- Router 只负责接收请求和返回响应
- Service 只负责业务逻辑
- DAO 只负责数据库操作
2. 易于测试:
# 可以单独测试服务层
def test_register():
user_id = UserService.register("testuser", "password123")
assert user_id > 0
3. 易于维护:
- 修改业务逻辑:只改 Service
- 修改数据库操作:只改 DAO
- 添加新接口:只加 Router
4. 代码复用:
# 多个接口可以复用同一个服务方法
@router.post("/api/users/register")
def register(data: UserRegisterRequest):
return UserService.register(...)
@router.post("/api/admin/users/create")
def admin_create_user(data: UserCreateRequest):
return UserService.register(...) # 复用
8. 常见问题(FAQ)
Q1: 为什么不用 Session 而用 JWT?
A:
| 特性 | Session | JWT |
|---|---|---|
| 存储位置 | 服务器 | 客户端 |
| 服务器压力 | 大 | 小(无状态) |
| 扩展性 | 差 | 好(适合分布式) |
| 适用场景 | 传统 Web | API 后端 |
Q2: SECRET_KEY 怎么生成?
A:
import secrets
# 生成安全的随机密钥
secret = secrets.token_hex(32)
print(secret)
# "a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6..."
Q3: Token 过期了怎么办?
A: 前端重新调用登录接口获取新 Token。
Q4: 怎么防止 Token 泄露?
A:
- ✅ 使用 HTTPS
- ✅ Token 设置过期时间
- ✅ 前端不要把 Token 打印到控制台
- ✅ 后端添加 IP 白名单(进阶)
💡 Vibe Coding 总结与反思
✅ 你已经掌握了什么?
恭喜!你现在已经能用 AI 搭建生产级别的后端了! 让我们回顾一下 Vibe Coding 的五大第一性原理:
1️⃣ 工具认知 ✅
- Router/Service/DAO:你知道每层是干嘛的(服务员/厨师/仓库管理员)
- JWT Token:游乐园手环,证明用户身份
- bcrypt:像做蛋饼,密码加密后无法还原
- Supabase:云端数据库,不用自己搭服务器
2️⃣ 问题定位 ✅
- 看懂报错日志:从下往上看,找最后一行的关键信息
- 三层架构定位:根据报错文件名(router/service/dao)判断哪一层的问题
- 常见报错速查表:知道 500/401/404 分别代表什么
- AI 调试助手:会把报错信息丢给 AI 求助
3️⃣ 框架理解 ✅
- 数据流向:用户请求 → Router → Service → DAO → 数据库 → 原路返回
- JWT 流程:登录 → 生成 Token → 客户端存储 → 后续请求带 Token → 服务器验证
- 密码安全:明文 → 加密 → 存储 → 登录验证
4️⃣ 设计思维 ✅
- 为什么分层:职责清晰、易于测试、易于维护、代码复用
- 为什么用 JWT 不用 Session:无状态、适合分布式、服务器压力小
- 为什么用 bcrypt 不用 MD5:每次加密结果不同、可以防彩虹表攻击
5️⃣ AI 协作 ✅
- 文件结构创建:让 AI 生成 shell 命令,不手动建文件
- 代码生成:给 AI 清晰的 Prompt,让它写具体代码
- 代码验证:知道怎么测试 AI 代码是否正确
- 报错修复:会把报错信息和代码一起发给 AI 求助
🎯 接下来你可以做什么?
实战任务(选一个尝试):
-
扩展功能:添加“修改密码“、“忘记密码“功能
- Prompt: “我想添加修改密码功能,需要验证旧密码后才能设置新密码,请帮我生成相应的 Service 和 Router 代码”
-
添加文章模块:实现发布文章、查看文章列表
- 先创建
article_dao.py,article_service.py,article_router.py - 让 AI 帮你生成 CRUD(增删改查)代码
- 先创建
-
前后端联调:把这个后端和前端项目连起来
- 前端用
fetch()或axios调用接口 - 记得处理 Token 存储和请求头
- 前端用
学习建议:
- ✅ 代码能跑就是成功,细节慢慢理解
- ✅ 多用 AI,把精力放在理解架构而非记语法
- ✅ 遇到报错别慌,报错是学习的最佳时机
- ✅ 实战出真知,做一个真实项目胜过看十篇教程
🤔 反思问题(巩固理解)
做完这个教程,问问自己:
- 工具认知:如果让你给别人解释“三层架构“,你能用餐厅比喻说清楚吗?
- 问题定位:遇到 500 错误,你知道第一步应该看哪里吗?
- 框架理解:你能画出用户注册时,数据从前端到数据库的完整流程图吗?
- 设计思维:为什么要用 JWT 而不是 Session?(用自己的话说)
- AI 协作:下次要添加新功能,你会怎么问 AI?
如果这 5 个问题你都能回答,说明你真的懂了 Vibe Coding 的精髓!
📚 深入学习资源
想进一步了解这些概念,推荐阅读:
🎉 最后的话
你不是在“学编程“,你是在“用 AI 解决问题“。
传统教育告诉你要“先学会语法再动手“,但 Vibe Coding 的理念是:
- 先理解问题(为什么需要用户登录?)
- 再理解方案(用 JWT Token 解决)
- 最后让 AI 写代码(具体语法交给机器)
记住:代码只是工具,思维才是核心。 你现在已经具备了用 AI 搭建后端系统的思维框架,恭喜你迈出了 Vibe Coding 的第一步!
去做点酷炫的东西吧! 🚀
📚 下一步
👉 技术术语手册
查阅常见技术术语的通俗解释,快速理解“黑话“。
返回 后端开发基础 查看完整目录。
技术术语手册
目标: 把后端“黑话“翻译成人话,快速查阅。
📖 使用说明
这是一本随时查阅的词典,不需要从头到尾看。
使用场景:
- 看文档遇到陌生术语
- 面试前快速复习
- 写代码时忘记概念
- 向 AI 提问时需要用到的“关键词“
查找方法: 按 Ctrl+F(Mac: Cmd+F)搜索术语
💡 Vibe Coding 核心提示
重要:这份手册是给你“看懂“用的,不是让你背代码用的。
- 你的任务:理解概念(通过类比和图解)
- AI 的任务:写具体代码(通过你提供的术语和需求)
每个术语下面都会给出“如何让 AI 帮你写代码“的提示词示例。
📚 目录
1. 数据存储技术
1.1 MySQL / PostgreSQL(数据库)
一句话: 专门存储“结构化数据“的软件(像 Excel,但更强大)
类比理解:
数据库 = 图书馆的档案系统
- 每本书(数据)都有固定格式:书名、作者、ISBN、分类
- 有严格的分类规则(表结构)
- 可以快速查找(索引)
- 支持复杂查询("找所有2020年后出版的科幻小说")
MySQL vs PostgreSQL:
| 特性 | MySQL | PostgreSQL |
|---|---|---|
| 速度 | 🚀 快 | 🏃 中等 |
| 功能 | ⭐⭐ 基础 | ⭐⭐⭐ 强大 |
| 适用场景 | 简单业务 | 复杂业务 |
我们用什么? → Supabase(基于 PostgreSQL)
🤖 如何让 AI 帮你?
当你需要数据库操作时,可以这样向 AI 提问:
"帮我用 Supabase(PostgreSQL 数据库)创建一个用户表,
需要包含:用户名、邮箱、密码、注册时间。"
你不需要懂 SQL 语法,AI 会帮你生成创建表的代码。你只需要:
- 说清楚要存什么数据(用户名、邮箱…)
- 复制 AI 给的代码到 Supabase 控制台执行
1.2 Supabase(数据库云服务)
一句话: 不用自己搭建服务器,直接用现成的数据库服务
类比理解:
自己搭 MySQL = 自己盖房子
- 需要买地(服务器)
- 需要装修(安装配置)
- 需要维护(修 Bug、升级)
用 Supabase = 住酒店
- 拎包入住(注册即用)
- 有人维护(自动备份、升级)
- 免费额度充足(小项目够用)
Supabase 提供什么?:
┌─────────────────────────────────────┐
│ Supabase 全家桶 │
├─────────────────────────────────────┤
│ 🗄️ Database │ PostgreSQL数据库 │
│ 🔐 Auth │ 用户登录注册 │
│ 📦 Storage │ 文件上传存储 │
│ 🔄 Realtime │ 实时数据订阅 │
│ 🛠️ Dashboard │ 可视化管理界面 │
└─────────────────────────────────────┘
1.3 OSS / Storage(对象存储)
一句话: 专门存储“文件“的云服务(图片、视频、PDF 等)
类比理解:
OSS = 云端的移动硬盘
- 存大文件(视频、图片、文档)
- 给每个文件一个"下载链接"
- 不适合存结构化数据(用户信息、订单等)
数据库 vs OSS:
┌──────────────┬───────────────┬─────────────┐
│ 数据类型 │ 存在哪里 │ 例子 │
├──────────────┼───────────────┼─────────────┤
│ 结构化数据 │ 数据库 │ 用户名、价格│
│ 文件 │ OSS/Storage │ 头像、PDF │
└──────────────┴───────────────┴─────────────┘
常见服务:
| 服务 | 免费额度 | 适用场景 | |——|———|———|\n| Supabase Storage | 1GB | 小项目(推荐) | | 阿里云 OSS | 无 | 国内项目 | | AWS S3 | 5GB/12个月 | 大项目 |
2. 架构设计模式
2.1 DAO(Data Access Object,数据访问对象)
一句话: 专门负责“操作数据库“的代码层
类比理解:
DAO = 仓库管理员
- 只负责存取货物(数据)
- 不关心为什么要取货(业务逻辑)
- 提供标准接口(get/create/update/delete)
你(业务层):"给我拿编号123的商品"
DAO:"好的,马上去仓库找"
示例代码:
class UserDAO:
def get_by_id(self, user_id: int): # 根据ID查询
def get_by_username(self, username: str): # 根据用户名查询
def create(self, data: dict): # 创建
def update(self, user_id: int, data: dict): # 更新
def delete(self, user_id: int): # 删除
⚠️ 看到代码头晕?别管它! 这些
def、self、:都是 Python 语法细节,你不需要记。这段代码只是让你知道 DAO 层有哪些基本操作。
🤖 如何让 AI 帮你?
当你需要数据库操作层时,向 AI 这样说:
"帮我用 FastAPI + Supabase 写一个 UserDAO 类,
需要实现:根据 ID 查询用户、创建用户、更新用户、删除用户。
请用 SQLAlchemy ORM。"
AI 会生成完整的 DAO 代码,你只需要:
- 告诉 AI 需要哪些操作(查询、创建、更新…)
- 说明是操作哪个表(用户表、文章表…)
- 把生成的代码保存到
dao/user_dao.py文件(AI 会告诉你文件名)
2.2 Service(服务层/业务逻辑层)
一句话: 专门负责“业务逻辑“的代码层
类比理解:
Service = 餐厅经理
- 接收顾客需求(路由层传来的请求)
- 制定处理流程(业务逻辑)
- 指挥仓库管理员(调用 DAO)
例子:顾客要点"宫保鸡丁"
经理(Service):
1. 检查食材是否充足(业务验证)
2. 通知后厨准备(调用 DAO 查询库存)
3. 安排厨师烹饪(组合多个 DAO 操作)
4. 上菜给顾客(返回结果)
Service 层的职责:
- ✅ 业务验证(用户名是否存在、密码是否合规)
- ✅ 数据转换(密码加密、日期格式化)
- ✅ 业务流程(先创建用户→再发邮件→再记录日志)
- ✅ 调用多个 DAO(一个业务可能涉及多个表)
- ❌ 不直接操作数据库(交给 DAO)
- ❌ 不处理 HTTP 请求(交给 Router)
🤖 如何让 AI 帮你?
当你需要业务逻辑层时,向 AI 这样说:
"帮我用 FastAPI 写一个用户注册的 Service 层函数,
需要:
1. 检查用户名是否已存在
2. 对密码进行加密(用 bcrypt)
3. 调用 UserDAO 创建用户
4. 返回成功或失败的信息"
AI 会生成完整的 Service 代码,你只需要:
- 描述清楚业务流程(先做什么,后做什么)
- 说明需要什么验证(用户名重复?密码长度?)
- 把代码保存到
services/user_service.py文件
2.3 Router / Controller(路由层/控制器层)
一句话: 专门负责“接收请求、返回响应“的代码层
类比理解:
Router = 餐厅服务员
- 接待客户(接收 HTTP 请求)
- 记录点单(解析请求参数)
- 转交后厨(调用 Service)
- 上菜(返回响应)
服务员不做菜(不写业务逻辑),只负责传话
三层架构流程:
用户请求 → Router(接待) → Service(处理) → DAO(存取) → 数据库
↓
返回响应 ← Router(送菜) ← Service(做菜) ← DAO(取食材)
3. 接口与通信
3.1 API(Application Programming Interface,应用程序接口)
一句话: 软件之间“对话“的标准规则
类比理解:
API = 餐厅的菜单
- 菜单上写了"宫保鸡丁 ¥38"(接口文档)
- 你不需要知道怎么做菜(后端实现细节)
- 只需要说"来一份宫保鸡丁"(发请求)
- 厨师按标准做好端给你(返回响应)
API 的组成:
POST https://api.example.com/users/register
────────────────────── ──────────────
基础URL 路径
Headers:(请求头)
Content-Type: application/json
Authorization: Bearer token123
Body:(请求体)
{
"username": "zhangsan",
"password": "123456"
}
Response:(响应)
{
"code": 200,
"msg": "注册成功",
"data": {"user_id": 123}
}
3.2 RESTful API(REST 风格的 API)
一句话: 用“URL 表示资源、HTTP 方法表示操作“的 API 设计规范
类比理解:
RESTful = 图书馆的统一管理规则
不遵守规则的图书馆:
- "我要借《三体》" → 去3号窗口
- "我要还《三体》" → 去8号窗口
- "我要续借《三体》" → 去15号窗口
混乱!
遵守 REST 规则的图书馆:
- 都去"图书管理窗口"
- 用不同的操作卡:借书卡、还书卡、续借卡
统一!
对应到 API:
GET /books/123 → 借书(获取)
POST /books → 买新书(创建)
PUT /books/123 → 换书(更新)
DELETE /books/123 → 扔掉书(删除)
RESTful 的核心原则:
| 操作 | HTTP方法 | 示例 |
|---|---|---|
| 查询 | GET | GET /api/users/123 |
| 创建 | POST | POST /api/users |
| 完整更新 | PUT | PUT /api/users/123 |
| 部分更新 | PATCH | PATCH /api/users/123 |
| 删除 | DELETE | DELETE /api/users/123 |
3.3 HTTP(超文本传输协议)
一句话: 浏览器和服务器之间“说话“的语言
常用状态码:
| 状态码 | 含义 | 使用场景 | 报错了怎么办? |
|---|---|---|---|
| 200 OK | 成功 | 请求成功 | - |
| 201 Created | 已创建 | 创建资源成功 | - |
| 400 Bad Request | 请求错误 | 参数格式错误 | 检查你发送的数据格式(邮箱格式对吗?必填项都填了吗?)→ 让 AI 帮你检查 Pydantic 验证规则 |
| 401 Unauthorized | 未授权 | 未登录或 token 无效 | 检查登录状态(Token 过期了?忘记带 Token?)→ 重新登录获取新 Token |
| 403 Forbidden | 禁止访问 | 没有权限 | 检查权限配置(这个用户有访问权限吗?)→ 去后台修改用户角色或 CORS 配置 |
| 404 Not Found | 未找到 | 资源不存在 | 检查 URL 路径(是不是打错了?资源被删了?)→ 确认接口地址和资源 ID |
| 500 Server Error | 服务器错误 | 服务器内部错误 | 不是你的问题! 这是后端代码出 Bug 了 → 查看后端日志(或让 AI 分析报错信息) |
🔍 报错时的 Vibe Coding 流程:
- 看状态码 → 知道大概哪里出问题(是前端问题还是后端问题)
- 复制完整报错信息 → 包括状态码、错误消息、堆栈信息(如果有)
- 问 AI → “我的 FastAPI 接口返回 403 错误,完整报错是:[粘贴报错],可能是什么原因?怎么修复?”
- 按 AI 建议操作 → AI 会告诉你去哪个文件改什么配置
4. 身份认证
4.1 Token(令牌)
一句话: 登录后获得的“临时通行证“
类比理解:
Token = 游乐园的手环
- 第一次入园:验证门票(账号密码) → 工作人员给你戴手环(Token)
- 后续玩项目:出示手环(带 Token 请求) → 直接放行
- 手环有效期:当天(Token 过期时间)
- 离开后失效:第二天来需要重新买票(Token 过期需重新登录)
为什么用 Token 而不是每次输密码?:
- ❌ 密码在网络传输不安全
- ❌ 每次输密码用户体验差
- ✅ Token 可以设置过期时间
- ✅ Token 可以随时撤销(比如登出)
4.2 JWT(JSON Web Token)
一句话: 一种“自包含信息“的 Token 格式
类比理解:
普通 Token = 图书馆借书卡号(123456)
- 看到卡号 123456
- 需要去系统查:这是谁的卡?有效吗?
- 需要数据库查询 ⏱️
JWT = 带照片的身份证
- 身份证上直接写了:姓名、年龄、地址
- 不需要查询,直接看身份证就知道是谁
- 不需要数据库查询 ⚡
JWT 的结构:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImV4cCI6MTcwMDAwMDAwMH0.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
────────────────────────────────── ─────────────────────────────────────────────────────────── ──────────────────────────────────────────────
Header(头部) Payload(负载) Signature(签名)
算法类型:HS256 用户信息:user_id=123, exp=过期时间 用密钥生成,防篡改
⚠️ 看到这一大串乱码害怕了?别担心!
- 这串乱码不是你打出来的,是系统自动生成的。
- 你只需要知道 JWT = “加密的用户信息卡片”,具体怎么加密让 AI 写。
- 你不需要懂加密算法,就像你不需要知道银行卡芯片怎么工作,只要会刷卡就行。
🤖 如何让 AI 帮你?
当你需要实现 JWT 登录验证时,向 AI 这样说:
"帮我用 FastAPI 实现 JWT 登录功能:
1. 用户登录成功后生成 JWT Token
2. Token 里包含用户 ID 和过期时间(24小时)
3. 提供一个验证 Token 的函数,用于保护需要登录的接口
请使用 python-jose 库。"
AI 会生成完整的 JWT 代码,你只需要:
- 说明 Token 里要包含哪些信息(用户 ID、角色…)
- 设置过期时间(1天、7天…)
- 把代码保存到
auth/jwt_handler.py文件
5. 开发框架与工具
5.1 FastAPI(Python Web 框架)
一句话: 快速开发 API 后端的 Python 框架
为什么选 FastAPI?:
| 特性 | FastAPI | Django | Flask |
|---|---|---|---|
| 学习曲线 | ⭐⭐ 中等 | ⭐⭐⭐ 较陡 | ⭐ 简单 |
| 开发速度 | 🚀 极快 | 🐢 慢 | 🏃 快 |
| 性能 | ⚡ 最快 | 🐌 一般 | 🏃 中等 |
| 自动文档 | ✅ 自动生成 | ❌ 需手写 | ❌ 需手写 |
| 适用场景 | API 后端 | 大型全栈 | 简单后端 |
核心特性:
- 📝 访问
/docs自动生成 Swagger UI 文档 - ✅ Pydantic 自动验证请求数据
- 🚀 异步支持,性能接近 Node.js
5.2 SQLAlchemy(ORM 框架)
一句话: 用 Python 代码操作数据库,不写 SQL
类比理解:
原始 SQL = 手写信
- SELECT * FROM users WHERE username = 'zhangsan'
- 容易写错、难以复用
SQLAlchemy = 用表单填空
- db.query(User).filter(User.username == 'zhangsan').first()
- 类型安全、IDE 自动补全
ORM 是什么?:
ORM = Object-Relational Mapping(对象关系映射)
数据库的表 ←→ Python 的类
表的行 ←→ 类的实例
表的列 ←→ 类的属性
users表 User类
┌────┬──────────┬───────┐ class User:
│ id │ username │ email │ id = Column(Integer)
├────┼──────────┼───────┤ username = Column(String)
│ 1 │ zhangsan │ ... │ email = Column(String)
└────┴──────────┴───────┘
5.3 Pydantic(数据验证库)
一句话: 自动验证数据格式是否正确
类比理解:
Pydantic = 机场安检
- 定义规则:液体不超过100ml、不能带刀具
- 自动检查:X 光机扫描
- 不合格:拦下并告知原因
示例:
from pydantic import BaseModel, Field, EmailStr
class UserRegisterRequest(BaseModel):
username: str = Field(..., min_length=3, max_length=50)
password: str = Field(..., min_length=6)
email: EmailStr # 自动验证邮箱格式
# FastAPI 中使用
@app.post("/api/users/register")
def register(user: UserRegisterRequest):
# FastAPI 自动验证所有规则
# 验证失败自动返回详细错误信息
return {"msg": "注册成功"}
⚠️ 看到
BaseModel、Field头晕?别管语法细节!
- 这些
Field(..., min_length=3)是 Pydantic 的规则写法,AI 会帮你写。- 你只需要知道:Pydantic = 自动检查数据的“质检员“,用中文告诉 AI 你要检查什么就行。
🤖 如何让 AI 帮你?
当你需要数据验证时,向 AI 这样说:
"帮我用 Pydantic 写一个用户注册的数据验证模型,要求:
- 用户名:3-50个字符
- 密码:至少6个字符
- 邮箱:必须是有效邮箱格式
- 手机号(可选):必须是11位数字"
AI 会生成完整的 Pydantic 模型代码,你只需要:
- 用中文描述每个字段的验证规则(长度、格式、必填/可选)
- 把代码保存到
models/schemas.py文件(或者问 AI:“这个代码应该放在哪个文件?”) - 在 Router 里引用这个模型(AI 会告诉你怎么引用)
实操示例(在哪里写代码):
- 打开 VS Code → 找到项目文件夹
- 创建文件 → 在
models文件夹下新建schemas.py(如果没有这个文件夹,让 AI 告诉你项目结构) - 粘贴代码 → 把 AI 生成的 Pydantic 代码粘贴进去
- 保存 →
Ctrl+S/Cmd+S
6. 部署与运维
6.1 Vercel(无服务器部署平台)
一句话: 把代码推到 GitHub,Vercel 自动部署上线(不用自己管服务器)
类比理解:
传统部署 = 自己开餐厅
- 租店铺(买服务器)¥500/月
- 装修(安装 Linux、配置环境)
- 招服务员(运维人员)
- 付水电费(服务器电费、带宽)
Vercel 部署 = 在美团开店
- 入驻即用(注册账号)
- 平台管理(自动扩容、备份)
- 按单收费(免费额度很大)
工作流程:
1. 本地开发 → 写代码、测试
2. 推送到 GitHub → git push origin main(在终端/命令行输入)
3. Vercel 自动检测 → 自动构建、自动部署
4. 生成访问链接 → https://your-app.vercel.app
❓ “git push” 是在哪里输入的?
- 方法1(推荐新手):使用 VS Code 的图形界面
- 点击左侧“源代码管理“图标(三个小圆点连线的那个)
- 填写提交信息(比如“添加用户注册功能“)
- 点击“提交“按钮(✓)
- 点击“同步更改“(↻)→ 自动推送到 GitHub
- 方法2(命令行):在 VS Code 终端输入
git push origin main
- 打开方式:菜单栏 → 终端 → 新建终端
6.2 环境变量(Environment Variables)
一句话: 不同环境(开发/测试/生产)使用不同的配置
类比理解:
环境变量 = 餐厅的不同模式
开发环境(本地):
- 用测试数据库(随便改)
- 开启调试模式(显示详细错误)
- API 地址:http://localhost:8000
生产环境(线上):
- 用正式数据库(真实用户数据)
- 关闭调试模式(不暴露错误细节)
- API 地址:https://api.example.com
为什么需要环境变量?:
# ❌ 硬编码(不好)
DATABASE_URL = "postgresql://user:password@localhost/mydb"
# 问题:密码暴露在代码里、推送到 GitHub 泄露
# ✅ 使用环境变量(推荐)
import os
DATABASE_URL = os.getenv("DATABASE_URL")
# 不同环境配置不同的值
⚠️ 看到 Python 代码不要慌! 这里只是展示原理,实际操作很简单(往下看实操步骤)。
🤖 如何让 AI 帮你? + 📝 实操指南
场景:你需要在项目里配置 Supabase 数据库连接。
第1步:问 AI 需要哪些环境变量
"我要用 FastAPI 连接 Supabase 数据库,需要配置哪些环境变量?"
AI 会告诉你需要:SUPABASE_URL、SUPABASE_KEY 等。
第2步:在本地创建 .env 文件(开发环境)
- 在项目根目录(和
main.py同级)新建文件,命名为.env - 在文件里写(AI 会给你格式):
SUPABASE_URL=https://your-project.supabase.co SUPABASE_KEY=your_secret_key_here - 重要:在
.gitignore文件里加一行.env(防止密码上传到 GitHub)
第3步:在 Vercel 配置环境变量(生产环境)
- 打开 Vercel 项目设置 → Settings → Environment Variables
- 添加同样的变量名和值(这里填真实生产环境的密钥)
- 点击“Save“ → 重新部署项目
让 AI 帮你写读取环境变量的代码:
"帮我用 Python 的 python-dotenv 库读取 .env 文件里的 SUPABASE_URL 和 SUPABASE_KEY"
AI 会生成类似这样的代码(你直接复制到 config.py 文件)。
6.3 CORS(跨域资源共享)
一句话: 允许前端(不同域名)访问后端 API
类比理解:
CORS = 海关
- 浏览器安全策略:不同"国家"(域名)之间不能随意往来
- 前端(http://localhost:3000)想访问后端(http://localhost:8000)→ 被拦截
- 配置 CORS = 办签证:后端告诉浏览器"允许这个域名访问"
FastAPI 配置:
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=[
"http://localhost:3000", # 开发环境前端
"https://your-app.vercel.app" # 生产环境前端
],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
📊 快速检索
我想…
| 需求 | 查看术语 | |——|———|\n| 存储用户信息 | MySQL/PostgreSQL | | 不想自己搭数据库 | Supabase | | 存储图片/文件 | OSS/Storage | | 代码不混乱 | DAO/Service/Router | | 前后端通信 | API | | URL 规范设计 | RESTful | | 用户登录验证 | JWT | | 快速开发后端 | FastAPI | | 用代码操作数据库 | SQLAlchemy | | 自动验证数据 | Pydantic | | 部署上线 | Vercel | | 前端访问报错 | CORS |
💡 使用建议
遇到不懂的术语:
- 在本文档按
Ctrl+F搜索 - 看“一句话“和“类比理解“
- 还不懂就问 AI:
“我不理解 [术语名] 是什么,能用日常生活的例子给我解释吗?”
记住: 术语只是名字,背后的概念才重要。看懂类比,就理解了 80%。
📚 返回目录
👉 后端开发基础
查看完整学习路径。
新手常见问题速查(2025版)
核心理念: 遇到问题不要慌,看懂报错 → 问 AI → 验证方案 → 解决问题。
📖 本节目标
学完本节,你将能够:
- ✅ 看懂常见报错信息(不再害怕红色文字)
- ✅ 知道如何高效地问 AI
- ✅ 快速定位是哪个环节出了问题
- ✅ 掌握自我调试的基本方法
预计用时: 30 分钟(随时查阅)
🎯 使用方法
这是一个速查手册,不需要从头到尾看。
使用场景:
- 遇到报错 → 复制关键错误信息 → 按
Ctrl+F搜索本文档 - 找到类似问题 → 理解报错原因 → 参考解决方案
- 还没解决 → 用本文档的“如何问 AI“模板提问
🖥️ 预备知识:在哪里输入命令?
如果你是零基础,先看这里!
什么是“终端/命令行“?
终端 = 和电脑对话的地方(就像微信聊天框,但更强大)
打开方式:
Windows 用户(三选一):
- 按
Win + R→ 输入cmd→ 回车(打开命令提示符) - 按
Win + R→ 输入powershell→ 回车(推荐,更强大) - 在 VS Code 底部点击“终端“标签(最方便)
Mac 用户:
- 按
Cmd + 空格→ 输入terminal→ 回车 - 在 VS Code 底部点击“终端“标签(推荐)
标准格式说明:
$ python --version
$符号:不需要输入,这只是代表“这是一行命令“python --version:这才是你要输入的内容
你会看到的结果:
Python 3.11.5
放轻松! 输入命令不会弄坏电脑(最多就是看到报错,关掉重来就好)
1. 环境配置问题(最常见!)
❌ 错误 1: command not found: python 或 'python' 不是内部或外部命令
报错场景:
$ python --version
command not found: python
原因:
- Python 没安装
- Python 已安装但环境变量未配置
快速诊断:
# Windows
where python
# Mac/Linux
which python
which python3
解决方案:
方案1: Python 没装 → 重新安装 Python,勾选 “Add Python to PATH”
方案2: 已安装但找不到:
Windows(推荐:重装更简单):
简单方式(推荐给新手):
- 卸载 Python(控制面板 → 程序和功能 → 卸载 Python)
- 重新下载安装包
- 安装时务必勾选 “Add Python to PATH”(在第一个安装界面的底部)
- 完成后,重启终端验证:
python --version
手动配置方式(如果不想重装):
⚠️ 这个操作有点复杂!如果你是第一次接触,建议用上面的重装方式。
-
找到 Python 安装路径(通常在这里):
C:\Users\你的用户名\AppData\Local\Programs\Python\Python311\不确定?右键桌面 Python 图标 → 打开文件所在位置
-
设置环境变量(跟着图文教程走更保险):
- 右键“此电脑“ → 属性 → 高级系统设置 → 环境变量
- 找到“系统变量“区域的
Path,双击打开 - 点击“新建“,添加两个路径(记得改成你自己的用户名):
C:\Users\你的用户名\AppData\Local\Programs\Python\Python311\C:\Users\你的用户名\AppData\Local\Programs\Python\Python311\Scripts\
- 一路“确定“保存
-
重启终端(必须!否则不生效)
看不懂? 参考图文教程:
Mac:
# 使用 python3
python3 --version
# 或者创建别名(添加到 ~/.zshrc 或 ~/.bash_profile)
alias python=python3
如何问 AI:
我安装了 Python 3.11,但在终端输入 python --version 显示 "command not found"。
我的系统是 [Windows 11 / macOS 14]。
我已经尝试了:[列出你尝试的方法]
请帮我排查问题。
❌ 错误 2: ModuleNotFoundError: No module named 'fastapi'
报错场景:
$ python main.py
ModuleNotFoundError: No module named 'fastapi'
原因排查(按优先级):
原因1: 虚拟环境没激活(90% 的情况!)
什么是虚拟环境?(用比喻理解)
虚拟环境 = 手机的应用分身(App Clone)
- 就像你可以在手机上装两个微信(工作号+个人号),它们的数据互不影响
- 虚拟环境让你的每个项目有独立的“工具箱“,避免不同项目的工具版本打架
- 好处: 项目 A 用的工具不会影响项目 B,删掉一个项目不会搞乱其他项目
你只需要记住两件事:
- 每次开始写代码前,要“激活虚拟环境“(就像打开应用分身)
- 激活成功后,终端前面会出现
(venv)标记(就像手机通知栏的图标)
参考资料: Python 虚拟环境详解(菜鸟教程) | 为什么需要虚拟环境(知乎)
# 检查虚拟环境是否激活
# 终端前面应该有 (venv) 标记
# 如果没有,激活虚拟环境
# Windows
venv\Scripts\activate
# Mac/Linux
source venv/bin/activate
原因2: Python 解释器选错了
在 VS Code 中:
- 按
Ctrl+Shift+P(Mac:Cmd+Shift+P) - 输入 “Python: Select Interpreter”
- 选择
./venv/Scripts/python.exe或./venv/bin/python
原因3: 真的没装
# 确认虚拟环境已激活后
pip install fastapi uvicorn[standard]
# 验证安装
# Mac/Linux 用这个(grep 是筛选命令,| 是管道符号,在键盘 Enter 键上方)
pip list | grep fastapi
# Windows 用这个(findstr 是 Windows 的筛选命令)
pip list | findstr fastapi
# 如果 Windows 报错,直接看完整列表也行
pip list
小白贴士: 看到
|这个竖线不用紧张,它叫“管道符号“,作用是“把前面命令的结果传给后面的命令“。你只需要照着输入就行,不需要理解原理。
原因4: 有多个 Python 环境混乱
# 查看当前使用的 Python
which python # Mac/Linux
where python # Windows
# 查看当前使用的 pip
which pip # Mac/Linux
where pip # Windows
# 如果不匹配,用完整路径安装
python -m pip install fastapi
如何问 AI:
我遇到 ModuleNotFoundError: No module named 'fastapi'。
我的环境信息:
- Python 版本:[运行 python --version 的结果]
- pip 版本:[运行 pip --version 的结果]
- 虚拟环境是否激活:[是/否,终端是否有 (venv) 标记]
- VS Code 选择的解释器:[./venv/... 还是系统 Python]
我已经尝试:
- [x] pip install fastapi(结果:[成功/失败/报错信息])
- [ ] 激活虚拟环境
- [ ] 重新选择 Python 解释器
请帮我排查问题。
❌ 错误 3: 虚拟环境激活后没有 (venv) 标记
报错场景:
$ source venv/bin/activate
# 终端前面没有出现 (venv) 标记
原因:
- Shell 配置问题(某些终端主题会隐藏)
- 虚拟环境创建失败
验证是否真的激活:
# 运行这个命令
which python # Mac/Linux
where python # Windows
# 如果返回虚拟环境路径(包含 venv),说明已激活
# 例如:/Users/你的名字/my-backend/venv/bin/python
解决方案:
如果 which python 指向虚拟环境,说明已经激活成功,只是没显示而已。继续工作即可。
如果不是,重新创建虚拟环境:
# 删除旧的虚拟环境
rm -rf venv # Mac/Linux
rmdir /s venv # Windows
# 重新创建
python -m venv venv
# 激活
source venv/bin/activate # Mac/Linux
venv\Scripts\activate # Windows
❌ 错误 4: pip install 下载很慢或超时
报错场景:
$ pip install fastapi
ReadTimeoutError: HTTPSConnectionPool...
原因: 网络问题或国外源太慢
解决方案: 使用国内镜像源
# 方法1: 临时使用(单次安装)
pip install -i https://mirrors.aliyun.com/pypi/simple/ fastapi
# 方法2: 永久配置(推荐)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 验证配置
pip config list
# 之后安装就快了
pip install fastapi uvicorn[standard]
其他国内镜像:
- 阿里云:
https://mirrors.aliyun.com/pypi/simple/ - 清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple/ - 中科大:
https://pypi.mirrors.ustc.edu.cn/simple/
2. FastAPI 运行问题
❌ 错误 5: ERROR: Could not find a version that satisfies uvicorn[standard]
报错场景:
$ pip install uvicorn[standard]
ERROR: Could not find a version...
原因: Windows CMD 不支持方括号
解决方案:
# Windows CMD 用引号
pip install "uvicorn[standard]"
# 或者分开安装
pip install uvicorn
❌ 错误 6: Address already in use (端口被占用)
报错场景:
$ python main.py
ERROR: [Errno 48] Address already in use
原因: 8000 端口被其他程序占用(或之前的进程没关闭)
解决方案:
方法1: 换个端口
# main.py
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8001, reload=True) # 改成 8001
方法2: 杀掉占用端口的进程
# Mac/Linux
lsof -i :8000 # 查看占用 8000 端口的进程
kill -9 <PID> # 杀掉进程(PID 是上面查到的进程号)
# Windows
netstat -ano | findstr :8000 # 查看占用 8000 端口的进程
taskkill /PID <PID> /F # 杀掉进程
❌ 错误 7: 访问 /docs 显示 404 Not Found
报错场景:
访问 http://localhost:8000/docs 显示 404
原因排查:
原因1: 拼写错误
- 正确:
/docs(有 s) - 错误:
/doc(没 s)
原因2: FastAPI 版本太旧
# 升级 FastAPI
pip install --upgrade fastapi
原因3: 禁用了文档
检查代码:
# ❌ 错误:禁用了文档
app = FastAPI(docs_url=None, redoc_url=None)
# ✅ 正确:启用文档
app = FastAPI()
❌ 错误 8: Pydantic 验证错误 value is not a valid email address
报错场景:
{
"detail": [
{
"loc": ["body", "email"],
"msg": "value is not a valid email address",
"type": "value_error.email"
}
]
}
原因: 邮箱格式不正确
理解报错:
loc: 错误位置(body表示请求体,email表示 email 字段)msg: 错误信息(邮箱格式不对)type: 错误类型
解决方案:
检查请求数据:
{
"username": "zhangsan",
"password": "123456",
"email": "not-an-email" // ❌ 缺少 @
}
// 改成
{
"username": "zhangsan",
"password": "123456",
"email": "zhang@example.com" // ✅ 正确格式
}
如何问 AI:
我的 FastAPI 接口返回 Pydantic 验证错误。
报错信息:
[粘贴完整的 JSON 报错]
我的数据模型:
[粘贴 Pydantic BaseModel 代码]
我发送的请求数据:
[粘贴请求 JSON]
请帮我找出哪里格式不对。
3. CORS 跨域问题
❌ 错误 9: CORS policy: No 'Access-Control-Allow-Origin' header
报错场景: 前端调用后端 API 时,浏览器控制台显示:
Access to fetch at 'http://localhost:8000/api/...' from origin 'http://localhost:3000'
has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present...
原因: 前端(http://localhost:3000)和后端(http://localhost:8000)域名不同,浏览器默认禁止跨域请求
理解 CORS(用比喻):
CORS = 小区保安的通行证制度
- 你住在 A 栋(前端网站 localhost:3000),想去 B 栋(后端服务器 localhost:8000)取快递
- 小区保安(浏览器)拦住你:“不同栋之间不能随便串门!”
- 你需要 B 栋业主(后端服务器)给你开一张通行证(CORS 配置),保安看到后才放行
为什么浏览器要拦截?
- 保护你的安全!防止恶意网站偷你在其他网站的数据
- 类比:防止陌生人冒充你去银行取钱
重要提示: 跨域限制只存在于浏览器环境,所以用 Postman 测试 API 时不会遇到这个问题
参考资料: CORS 跨域详解(阮一峰) | MDN CORS 文档
解决方案:
在 FastAPI 中配置 CORS:
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
# 添加 CORS 中间件(复制这段代码,让 AI 帮你调整细节)
app.add_middleware(
CORSMiddleware,
allow_origins=[
"http://localhost:3000", # 开发环境前端地址
"https://your-app.vercel.app" # 生产环境前端地址(改成你的)
],
allow_credentials=True,
allow_methods=["*"], # 允许所有 HTTP 方法(GET、POST、PUT、DELETE 等)
allow_headers=["*"], # 允许所有请求头
)
小白贴士:
allow_origins=["*"]中的*表示“允许所有来源“,但生产环境绝对禁用(不安全)- 开发时可以临时用
["*"]快速测试,但部署前必须改成具体的域名- 不理解代码细节没关系,直接复制使用,或者让 AI 帮你生成
测试环境快速修复(允许所有域名,仅限开发!):
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # ⚠️ 生产环境禁用!
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
4. Supabase 连接问题
❌ 错误 10: Connection refused 或 could not translate host name
报错场景:
supabase.table('users').select("*").execute()
# 报错: Connection refused
原因排查(2025 最新):
原因1: 暴力破解保护(最常见!)
- Supabase 会临时封禁频繁失败的连接(30分钟)
- 可能是密码错了多次
解决方案: 等待 30 分钟,或检查密码是否正确
原因2: IPv6 支持问题
- Supabase 默认连接需要 IPv6
- 如果网络不支持 IPv6,会连接失败
解决方案: 使用连接池模式(IPv4)
# 不用直接连接,改用连接池
SUPABASE_URL = "https://xxx.supabase.co" # 不变
# 连接池 URL(从 Supabase 项目设置 → Database → Connection pooling 获取)
原因3: 密码中有特殊字符
- 密码中的
@、#、&等字符会破坏 URL
解决方案: 用 Supabase SDK(不用 URL 连接字符串)
from supabase import create_client
# ✅ 推荐方式(自动处理特殊字符)
supabase = create_client(
supabase_url="https://xxx.supabase.co",
supabase_key="你的 anon key"
)
原因4: 网络问题
- 检查是否能访问
https://你的项目ID.supabase.co
❌ 错误 11: 401 Unauthorized (Supabase 权限错误)
报错场景:
supabase.table('users').select("*").execute()
# 返回: 401 Unauthorized
原因: Supabase 默认开启了 RLS(行级安全策略)
理解 RLS(用比喻):
RLS = 银行金库的门禁系统
- 金库默认对所有人上锁(包括你自己的后端代码)
- 你需要设置一条“通行规则“(Policy),告诉金库:“这个人可以进来”
- Supabase 的安全理念: “默认拒绝一切,明确允许才放行”
开发阶段怎么办?
- 可以临时关掉 RLS 快速测试(就像暂时不锁门)
- 但上线前必须重新打开并设置正确的规则(否则数据裸奔!)
解决方案:
方法1: 临时禁用 RLS(开发环境,快速测试)
- 打开 Supabase 项目
- 左侧菜单 → Authentication → Policies
- 找到
users表 → 点击 “Disable RLS”
⚠️ 警告: 生产环境一定要启用 RLS!
方法2: 设置 Policy(生产环境推荐)
- 左侧菜单 → Authentication → Policies
- 点击 “New Policy”
- 选择 “Enable read access for all users”
- 保存
5. JWT 认证问题(2025 最佳实践)
❌ 错误 12: Token 无效或已过期
报错场景:
{
"detail": "Token 无效或已过期"
}
原因: Token 过期或格式错误
如何调试:
- 检查 Token 是否过期
访问 jwt.io,粘贴你的 Token,查看 exp 字段(过期时间)
- 检查 Token 格式
# 正确格式(三段,用 . 分隔)
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjN9.abc123
# 错误格式(缺少 Bearer 或多了空格)
Bearer eyJhbGci... # ❌ Bearer 后面多了空格
eyJhbGci... # ❌ 缺少 Bearer
- 检查前端发送方式
// ✅ 正确
fetch('/api/users/profile', {
headers: {
'Authorization': `Bearer ${token}` // 注意空格
}
})
// ❌ 错误
fetch('/api/users/profile', {
headers: {
'Authorization': token // 缺少 Bearer
}
})
⚠️ 安全警告: 不要用 SHA256 加密密码!(2025 最新)
常见错误(不要复制这段代码!):
# ❌ 不安全!2025 年已淘汰
import hashlib
password_hash = hashlib.sha256(password.encode()).hexdigest()
为什么不安全:
- 相同密码哈希相同,黑客可以用“彩虹表“(预先计算的密码字典)破解
- SHA256 运算太快,暴力破解很容易
正确做法(直接复制下面的代码模板):
# ✅ 使用 argon2id 或 bcrypt(2025 年最佳实践)
from passlib.context import CryptContext
# 创建密码加密器(复制这段,不需要理解原理)
pwd_context = CryptContext(schemes=["argon2"], deprecated="auto")
# 加密密码(每次结果都不同!这是正常的)
password_hash = pwd_context.hash("123456")
# 验证密码(登录时用)
is_correct = pwd_context.verify("123456", password_hash) # 返回 True 或 False
小白专用说明:
- 你不需要理解“加盐“、“哈希算法“这些概念
- 直接复制上面的代码模板,或者让 AI 帮你生成
- 记住:存密码时用
.hash(),验证密码时用.verify()- 如果看到“每次加密结果不同“,不要慌,这是故意设计的安全特性
安装依赖:
pip install "passlib[argon2]"
参考资料: FastAPI Security Best Practices 2025
6. 如何高效地问 AI
✅ 好的提问模板
模板1: 报错问题
我在 [做什么事情] 时遇到报错。
【环境信息】
- 操作系统:Windows 11 / macOS 14 / Ubuntu 22.04
- Python 版本:3.11.5
- FastAPI 版本:0.109.0 (运行 pip show fastapi 查看)
- 虚拟环境:已激活 / 未激活
【完整报错信息】
[粘贴完整的报错堆栈,不要只截取一部分!]
【相关代码】
[粘贴出问题的代码片段]
【我已经尝试的方法】
- [x] 方法1(结果:失败,报错:xxx)
- [x] 方法2(结果:没有改善)
- [ ] 方法3(还没试)
请帮我排查问题。
模板2: 功能实现
我想实现 [具体功能描述]。
【技术栈】
- 后端:FastAPI + Supabase
- 前端:Next.js (可选)
【当前进度】
- [x] 已完成:数据库表创建
- [ ] 待实现:用户注册接口
- [ ] 待实现:JWT 认证
【我的想法】
[简述你的实现思路]
【遇到的困惑】
[哪里不确定怎么做]
请给我实现思路和参考代码。
模板3: 设计决策
我在设计 [某个功能] 时,有两个方案:
【方案A】
- 优点:xxx
- 缺点:xxx
【方案B】
- 优点:xxx
- 缺点:xxx
【我的疑问】
- 这两个方案哪个更好?
- 有没有其他更好的方案?
- 在 [具体场景] 下应该选哪个?
请帮我分析。
❌ 不好的提问(AI 无法回答)
反例1: 信息不全
❌ "我的代码报错了,怎么办?"
- 什么报错?
- 什么代码?
- 什么环境?
反例2: 只截取部分报错
❌ "报错:KeyError: 'user_id'"
- 完整的报错堆栈是什么?
- 哪个文件哪一行?
反例3: 太宽泛
❌ "怎么做后端?"
- 具体要实现什么功能?
- 用什么技术栈?
7. 调试技巧
🔍 如何看懂报错堆栈
示例报错:
Traceback (most recent call last):
File "/Users/你的名字/my-backend/main.py", line 15, in register
user_id = UserService.register(data.username, data.password)
File "/Users/你的名字/my-backend/services/user_service.py", line 28, in register
if dao.get_by_username(username):
File "/Users/你的名字/my-backend/dao/user_dao.py", line 18, in get_by_username
return response.data[0]['id']
IndexError: list index out of range
如何阅读(从下往上):
-
最底部 = 真正的错误
IndexError: list index out of range意思:列表越界(试图访问不存在的索引)
-
倒数第二行 = 出错的代码
File ".../dao/user_dao.py", line 18, in get_by_username return response.data[0]['id']意思:
user_dao.py第 18 行,response.data[0]出错 -
往上追踪调用链
main.py (line 15) 调用了 user_service.py (line 28) 调用了 user_dao.py (line 18) 出错了
问题定位:
response.data是空列表- 访问
[0]时越界 - 原因:数据库里没有这个用户
修复方案:
# ❌ 错误写法
def get_by_username(username: str):
response = supabase.table('users').select("*").eq('username', username).execute()
return response.data[0]['id'] # 如果没找到,data 是空列表
# ✅ 正确写法
def get_by_username(username: str):
response = supabase.table('users').select("*").eq('username', username).execute()
if response.data: # 先检查是否为空
return response.data[0]
return None
🔍 如何用 print() 调试
技巧1: 打印变量值
@app.post("/api/users/register")
def register(data: UserRegisterRequest):
print(f"收到注册请求:{data}") # 看看收到了什么数据
existing_user = UserDAO.get_by_username(data.username)
print(f"查询结果:{existing_user}") # 看看查询到了什么
if existing_user:
print("用户已存在")
return R.error("用户名已存在")
print("开始创建用户")
# ...
小白贴士:
print()是最简单的调试方法,专业开发者也常用- 加上表情符号(📝/🔍/✅/❌)可以让日志更容易看懂
- 看不懂代码逻辑没关系,AI 可以帮你加 print 语句
技巧2: 打印请求/响应
# 在 Supabase 操作前后打印
print("准备插入数据:", data)
response = supabase.table('users').insert(data).execute()
print("插入结果:", response)
8. 快速检查清单
遇到问题时,按这个顺序检查:
环境问题检查
- 虚拟环境已激活(终端有
(venv)标记) - VS Code 选择了正确的 Python 解释器(
./venv/...) - 依赖包已安装(
pip list能看到 fastapi) - Python 版本正确(
python --version>= 3.10)
代码问题检查
- 路由路径拼写正确(
/api/users/register) - HTTP 方法正确(GET/POST/PUT/DELETE)
- 请求数据格式正确(JSON 格式,字段名对应)
- 数据库连接信息正确(Supabase URL 和 Key)
网络问题检查
- 后端服务已启动(
uvicorn running on http://...) - 端口没被占用(8000)
- CORS 已配置(如果前端调用)
- Supabase 项目可访问(在浏览器打开项目 URL)
Token 认证检查
- Token 格式正确(
Bearer <token>) - Token 未过期(在 jwt.io 查看)
- Authorization Header 拼写正确
- Token 包含正确的用户信息
9. 常用调试命令
# 查看 Python 版本
python --version
# 查看 pip 版本
pip --version
# 查看当前使用的 Python 路径
which python # Mac/Linux
where python # Windows
# 查看已安装的包
pip list
# 查看某个包的详细信息
pip show fastapi
# 重新安装包(清除缓存)
pip install --force-reinstall fastapi
# 查看端口占用
lsof -i :8000 # Mac/Linux
netstat -ano | findstr :8000 # Windows
# 测试 API(命令行)
curl http://localhost:8000/
# 测试 API(带数据)
curl -X POST http://localhost:8000/api/users/register \
-H "Content-Type: application/json" \
-d '{"username":"test","password":"123456"}'
💡 Vibe Coding 调试心法
记住这三步:
- 看懂报错 - 不要慌,报错信息会告诉你问题在哪
- 问 AI - 用本文档的提问模板,提供完整信息
- 验证方案 - AI 给的方案不一定对,要测试验证
调试不是目的,解决问题才是目的。
- 能跑通就是成功
- 报错是正常的(专业开发者每天也会遇到几十个报错)
- 搜索和问 AI 是正常工作流程(不是作弊)
📚 参考资料(2025最新)
官方文档:
安全最佳实践:
常见错误:
📝 本节小结
你应该掌握的能力:
- ✅ 遇到报错不慌张,能看懂错误信息
- ✅ 知道如何系统地排查问题(环境→代码→网络→数据库)
- ✅ 会用标准模板问 AI,提供完整信息
- ✅ 能自己调试简单问题(print 大法)
记住:
- 报错是学习的机会
- 每解决一个报错,你就变强一点
- AI 是你的助手,但你要学会如何使用它
👉 下一步: 返回 后端开发基础 查看完整目录
如果遇到本文档没有列出的问题,用“如何问 AI“模板提问,90% 的问题都能解决!
运维基础
方法论: 从第一性原理出发,理解服务器部署的核心概念。
📚 本章导航
01. 终端和命令行
你将理解:
- ✅ 终端是什么,为什么要用它
- ✅ 常用 Linux 命令速查
- ✅ Vim 编辑器基础操作
- ✅ 文件和目录管理
预计用时: 25 分钟
02. 包管理器 npm 和 pip
你将理解:
- ✅ npm 和 pip 的作用
- ✅ package.json 和 requirements.txt
- ✅ 国内镜像源配置(解决下载慢)
- ✅ 虚拟环境的必要性
预计用时: 20 分钟
03. Linux 权限系统
你将理解:
- ✅ Linux 权限的三个层级
- ✅ sudo 命令的原理和使用
- ✅ chmod 和 chown 实战
- ✅ 常见权限问题解决
预计用时: 30 分钟
04. 服务器部署
你将理解:
- ✅ 云服务器和安全组配置
- ✅ Nginx 反向代理原理
- ✅ 前端打包详解(环境变量、打包优化)
- ✅ PM2 进程管理
- ✅ HTTPS 和域名配置
预计用时: 50 分钟
05. Docker 容器化 🔥 进阶
你将理解:
- ✅ Docker 概念(集装箱类比)
- ✅ Dockerfile 编写和镜像构建
- ✅ docker-compose 多容器编排
- ✅ 完整的容器化部署流程
预计用时: 35 分钟
🎯 学习路线建议
新手路线(按顺序学)
- 先学 01. 终端和命令行 → 掌握基本操作
- 再学 02. 包管理器 → 理解依赖管理
- 然后学 03. Linux 权限 → 避免部署错误
- 最后学 04. 服务器部署 → 完整部署流程
- 可选 05. Docker 容器化 → 现代化部署方式
快速查询路线(遇到问题再学)
- 部署时报错 “Permission denied” → 直接看 03
- npm install 很慢 → 直接看 02 的镜像配置
- 不知道怎么编辑服务器文件 → 直接看 01 的 Vim 部分
- 网站部署后无法访问 → 直接看 04 的 Nginx 和安全组
- 前端打包报错 → 直接看 04 的前端打包详解
- 想学容器化部署 → 直接看 05 的 Docker 教程
💡 Vibe Coding 心法
不要被术语吓到!
所有复杂的概念都有生活中的类比:
- 终端 = 和电脑文字对话的窗口
- 包管理器 = 代码界的应用商店
- 权限系统 = 房间的钥匙管理
- 反向代理 = 前台接待员
- Docker容器 = 标准化的集装箱运输
记住三个原则
-
理解原理,不背命令 知道为什么要这样做,比记住怎么做更重要
-
遇到问题,复制报错问 AI AI 是你的最佳助手,不要自己硬想
-
从实战出发,需要什么学什么 不需要一次性掌握所有知识,用到再深入
🚀 开始学习
点击上面的章节链接开始学习,或者按照新手路线从第一章开始。
记住:运维不是玄学,所有概念都可以用生活经验理解!
终端和命令行
方法论: 终端不是黑魔法,它只是用文字和电脑对话的窗口。
📖 本节目标
学完本节,你将理解:
- ✅ 终端是什么,为什么要用它
- ✅ 如何打开和使用终端
- ✅ 15个最常用的Linux命令
- ✅ Vim编辑器的生存技能
预计用时: 25分钟
1. 终端是什么?
1.1 生活类比
终端 = 和电脑文字对话的窗口
| 操作方式 | 类比 | 适用场景 |
|---|---|---|
| 图形界面(GUI) | 用遥控器换电视频道 | 日常使用,直观易懂 |
| 命令行(CLI) | 对着电视喊“换到CCTV5“ | 服务器管理,效率超高 |
1.2 为什么要用终端?
核心原因: 大多数服务器没有图形界面!
你的笔记本 云服务器
┌─────────────┐ ┌─────────────┐
│ 桌面、图标 │ │ 只有黑屏 │
│ 鼠标点击 │ │ 纯文字操作 │
│ 窗口、菜单 │ SSH连接 ──> │ 效率超高 │
└─────────────┘ └─────────────┘
三大优势:
- 远程操作: 只传输文字,不需要传输图形界面(快!)
- 批量处理: 一个命令操作100个文件,图形界面要点100次
- 自动化: 写成脚本,定时自动执行
1.3 终端与部署的关系 ⚠️ 重要!
现实场景: 你开发了一个网站,要让全世界的人都能访问
开发阶段(你的电脑):
✅ npm run dev ← 本地运行
✅ 浏览器打开localhost:3000
✅ 一切正常!
部署阶段(云服务器):
你需要在服务器上:
1. SSH登录服务器 ← 必须用终端
2. 安装Node.js ← 必须用终端
3. 上传代码 ← 必须用终端
4. 配置Nginx ← 必须用终端
5. 启动应用 ← 必须用终端
6. 查看日志排错 ← 必须用终端
没有终端,你无法部署应用!
部署时你会用到的终端操作:
| 操作 | 为什么需要 | 本章会学到 |
|---|---|---|
| 连接服务器 | SSH远程登录 | ✅ 第3章 |
| 编辑配置文件 | 修改Nginx配置 | ✅ 第4章 Vim |
| 查看日志 | 排查应用错误 | ✅ 第3.4章 |
| 后台运行 | 应用持续运行 | ✅ 第3.4章 |
| 进程管理 | 重启/停止应用 | ✅ 第3.4章 |
| 权限管理 | 解决部署权限错误 | ✅ 03章权限系统 |
学习路线图:
01. 终端基础(本章)
├── 基础命令(ls/cd/vim)
└── 实用命令(日志/后台运行)
│
▼
02-03. 包管理器和权限
│
▼
04. 服务器部署
├── 使用终端SSH登录
├── 使用终端配置Nginx
├── 使用终端启动应用
└── 使用终端查看日志排错
终端是部署的基础工具!
2. 如何打开终端?
Windows 用户
方法1: 快捷键
- 按
Win + R - 输入
cmd或powershell - 按回车
方法2: 搜索
- 点击开始菜单
- 搜索“命令提示符“或“PowerShell“
Mac 用户
方法1: 快捷键
- 按
Command + 空格 - 输入
terminal或终端 - 按回车
方法2: 访达
- 打开“应用程序“
- 进入“实用工具“
- 双击“终端“
打开后长这样
~ % _ ← 光标在这里闪烁,可以输入命令了
重要: 后面所有命令都要在终端窗口里输入,不是在浏览器或Word里!
3. 必须掌握的15个命令
3.1 文件导航 (5个)
pwd - 我在哪里?
作用: 显示当前目录的完整路径
pwd
# 输出: /home/username/projects
类比: 问GPS“我现在的位置是?“
ls - 这里有什么?
作用: 列出当前目录的文件和文件夹
# 基础用法
ls
# 显示详细信息(推荐)
ls -la
# 显示文件大小(人类可读)
ls -lh
输出示例:
-rw-r--r-- 1 user staff 1.5K Nov 26 08:00 README.md
drwxr-xr-x 5 user staff 160B Nov 25 10:30 src/
类比: 打开抽屉看里面有什么东西
cd - 进入目录
作用: 切换到指定目录
# 进入某个文件夹
cd projects
# 回到上一级
cd ..
# 回到家目录
cd ~
# 回到上一个目录
cd -
类比: 走进某个房间
Tab键 - 自动补全(超重要!)
使用方法: 输入命令或路径的前几个字母,按Tab键
# 输入
cd proj[按Tab]
# 自动补全为
cd projects/
为什么重要:
- ✅ 节省时间
- ✅ 防止拼写错误
- ✅ 显示可能的选项
3.2 文件操作 (5个)
mkdir - 创建文件夹
# 创建单个文件夹
mkdir my-project
# 递归创建多层文件夹
mkdir -p parent/child/grandchild
touch - 创建空文件
# 创建一个文件
touch index.html
# 创建多个文件
touch file1.txt file2.txt file3.txt
cp - 复制文件
# 复制文件
cp source.txt backup.txt
# 复制整个文件夹(递归)
cp -r folder/ backup-folder/
类比: 复印文件
mv - 移动/重命名文件
# 重命名文件
mv old-name.txt new-name.txt
# 移动文件到其他文件夹
mv file.txt /path/to/folder/
类比: 剪切粘贴
rm - 删除文件 ⚠️ 危险!
# 删除文件
rm file.txt
# 删除文件夹(递归)
rm -r folder/
# 强制删除(不提示确认)
rm -rf folder/ ← 非常危险!
⚠️ 警告: Linux没有回收站,删了就真的没了!
永远不要执行的命令:
# 这会删除整个系统!!! 绝对不要运行!!!
rm -rf /
rm -rf /*
3.3 查看文件内容 (3个)
cat - 显示整个文件
cat README.md
适合: 短文件
less - 分页查看
less large-file.log
快捷键:
- 空格键: 下一页
b: 上一页/搜索词: 搜索q: 退出
适合: 长文件
tail - 查看文件末尾
# 查看最后10行
tail file.log
# 查看最后50行
tail -n 50 file.log
# 实时监控日志(超实用!)
tail -f app.log
适合: 查看日志文件
3.4 其他实用命令 (2个)
grep - 搜索文本
# 在文件中搜索关键词
grep "error" app.log
# 忽略大小写
grep -i "error" app.log
# 递归搜索整个文件夹
grep -r "function" src/
类比: Ctrl+F 全局搜索
ps 和 kill - 进程管理
# 查看所有进程
ps aux
# 查找特定进程
ps aux | grep nginx
# 杀死进程(替换PID为实际进程号)
kill 12345
# 强制杀死
kill -9 12345
3.5 部署实用命令速查 🔥 重要!
查看日志 (排查错误必备)
# 查看日志文件最后100行
tail -n 100 /var/log/nginx/error.log
# 实时查看日志(最常用!)
tail -f /var/log/nginx/access.log
tail -f ~/app/logs/error.log
# 搜索日志中的错误
grep "ERROR" app.log
grep -i "error" app.log # 忽略大小写
# 查看日志的特定时间段
grep "2024-11-26" app.log | grep "ERROR"
# 统计错误数量
grep -c "ERROR" app.log
实战场景: 应用部署后报错,查看日志排错
# 1. 先看最后的错误
tail -n 50 logs/error.log
# 2. 实时监控新日志
tail -f logs/error.log
# 3. 搜索关键错误信息
grep "Error" logs/error.log
后台运行程序
问题: 关闭终端后,程序就停了!
# ❌ 错误: 直接运行(关闭终端就停止)
python app.py
node server.js
# ✅ 正确: 使用nohup后台运行
nohup python app.py > app.log 2>&1 &
nohup node server.js > server.log 2>&1 &
命令解释:
| 部分 | 含义 |
|---|---|
nohup | 不挂断运行(关闭终端也不停) |
> app.log | 将输出重定向到日志文件 |
2>&1 | 将错误输出也重定向到日志 |
& | 在后台运行 |
查看后台进程:
# 查看刚启动的进程号
echo $!
# 查看所有后台任务
jobs
# 查看特定进程
ps aux | grep python
ps aux | grep node
停止后台进程:
# 查找进程号
ps aux | grep "app.py"
# 杀死进程(替换12345为实际PID)
kill 12345
# 强制杀死
kill -9 12345
# 或使用pkill(按名称杀死)
pkill -f app.py
SSH远程连接
# 基本连接
ssh username@server-ip
# 指定端口
ssh -p 22 username@server-ip
# 使用密钥登录
ssh -i ~/.ssh/id_rsa username@server-ip
# 远程执行命令
ssh username@server-ip "ls -la"
# 上传文件到服务器
scp local-file.txt username@server-ip:/remote/path/
# 下载文件从服务器
scp username@server-ip:/remote/file.txt ./local-path/
# 上传整个目录
scp -r local-folder/ username@server-ip:/remote/path/
文件传输 (rsync更高效)
# rsync同步文件(增量传输,更快!)
rsync -avz local-folder/ username@server-ip:/remote/path/
# -a: 归档模式(保留权限)
# -v: 显示详细信息
# -z: 压缩传输
# 排除某些文件
rsync -avz --exclude 'node_modules' \
local-folder/ username@server-ip:/remote/path/
磁盘空间管理
# 查看磁盘使用情况
df -h
# 查看当前目录大小
du -sh .
# 查看各子目录大小(排序)
du -h --max-depth=1 | sort -h
# 查找大文件(大于100MB)
find / -type f -size +100M 2>/dev/null
# 清理日志文件
> app.log # 清空但不删除文件
truncate -s 0 app.log # 同上
系统状态监控
# 查看系统资源使用
top
htop # 更友好(需要安装)
# 查看内存使用
free -h
# 查看CPU信息
lscpu
# 查看系统运行时间
uptime
# 查看当前登录用户
who
w
# 查看端口占用
netstat -tuln | grep 3000
lsof -i :3000
# 查看网络连接
netstat -an | grep ESTABLISHED
快速重启服务
# 重启Nginx
sudo systemctl restart nginx
# 重启PM2应用
pm2 restart app-name
# 重启整个服务器(慎用!)
sudo reboot
环境变量管理
# 查看所有环境变量
env
printenv
# 查看特定环境变量
echo $PATH
echo $HOME
# 临时设置环境变量(当前会话有效)
export NODE_ENV=production
# 永久设置(添加到配置文件)
echo 'export NODE_ENV=production' >> ~/.bashrc
source ~/.bashrc # 重新加载配置
压缩和解压
# 压缩文件
tar -czvf backup.tar.gz folder/
zip -r backup.zip folder/
# 解压文件
tar -xzvf backup.tar.gz
unzip backup.zip
# 查看压缩包内容(不解压)
tar -tzvf backup.tar.gz
unzip -l backup.zip
文本处理技巧
# 快速查看文件前/后几行
head -n 20 file.txt
tail -n 20 file.txt
# 统计行数/字数
wc -l file.txt # 行数
wc -w file.txt # 字数
# 去重
sort file.txt | uniq
# 批量替换
sed -i 's/old/new/g' file.txt
# 查找包含关键词的文件
grep -r "keyword" .
快捷命令组合(超实用!)
# 查看应用是否在运行
ps aux | grep node | grep -v grep
# 一键杀死所有Node进程
pkill -f node
# 查看最占CPU的进程
ps aux --sort=-%cpu | head -10
# 查看最占内存的进程
ps aux --sort=-%mem | head -10
# 查找并删除所有.log文件
find . -name "*.log" -delete
# 批量重命名文件
for file in *.txt; do mv "$file" "${file%.txt}.md"; done
4. Vim编辑器生存指南
4.1 为什么要学Vim?
现实: 服务器上编辑配置文件,80%的情况只有Vim可用。
4.2 Vim的三种模式
| 模式 | 说明 | 如何进入 |
|---|---|---|
| 命令模式 | 光标移动、删除、复制 | 启动Vim时的默认模式 |
| 插入模式 | 实际输入文本 | 按 i 键 |
| 命令行模式 | 保存、退出 | 按 : 键 |
4.3 最小生存命令(必须会!)
打开文件
vim filename.txt
进入编辑
按 i 键 ← 进入插入模式,可以输入内容了
保存并退出
1. 按 Esc ← 退回命令模式
2. 输入 :wq ← 保存并退出
3. 按回车
不保存退出
1. 按 Esc
2. 输入 :q! ← 强制退出不保存
3. 按回车
4.4 常用操作速查
在命令模式下:
| 操作 | 按键 |
|---|---|
| 删除一行 | dd |
| 复制一行 | yy |
| 粘贴 | p |
| 撤销 | u |
| 跳到文件开头 | gg |
| 跳到文件结尾 | G |
保存和退出:
| 操作 | 命令 |
|---|---|
| 保存 | :w |
| 退出 | :q |
| 保存并退出 | :wq 或 ZZ |
| 强制退出不保存 | :q! |
5. 实战练习
练习1: 创建项目结构
在终端依次输入:
# 1. 创建项目文件夹
mkdir my-first-project
# 2. 进入文件夹
cd my-first-project
# 3. 创建多个文件
touch index.html style.css script.js
# 4. 查看创建结果
ls -la
# 5. 创建子文件夹
mkdir images docs
# 6. 再次查看
ls -la
练习2: Vim编辑文件
# 1. 用Vim打开文件
vim README.md
# 2. 按 i 进入插入模式
# 3. 输入一些文字
这是我的第一个项目!
# 4. 按 Esc 退回命令模式
# 5. 输入 :wq 保存并退出
# 6. 查看文件内容
cat README.md
6. 常见问题
Q1: 输入命令后没反应?
可能原因:
- 没按回车键
- 命令拼写错误
- 权限不足(需要加
sudo)
解决: 仔细检查拼写,按回车,看报错信息
Q2: Vim进去了出不来!
紧急退出:
1. 狂按 Esc 键3次
2. 输入 :q!
3. 按回车
记住: Esc回到命令模式, :q!强制退出
Q3: 误删文件怎么办?
现实: Linux没有回收站,删了就真的没了!
预防措施:
- 删除前用
ls确认路径正确 - 重要文件提前备份
- 使用
rm -i会在删除前确认
Q4: 程序运行后关闭终端就停了
问题:
# 直接运行
python app.py
# 关闭终端 → 程序停止运行!
解决方案:
# 方案1: 使用nohup后台运行
nohup python app.py > app.log 2>&1 &
# 方案2: 使用PM2管理(推荐,见04章)
pm2 start app.py --name my-app
Q5: 命令找不到(command not found)
报错示例:
-bash: npm: command not found
-bash: python: command not found
原因: 软件没安装或不在PATH环境变量中
解决:
# 检查是否安装
which npm
which python3
# 如果没安装,需要先安装
# Node.js/npm
sudo apt install nodejs npm # Ubuntu
brew install node # macOS
# Python
sudo apt install python3 # Ubuntu
brew install python3 # macOS
Q6: 权限被拒绝(Permission denied)
报错示例:
mkdir /opt/myapp
# mkdir: cannot create directory '/opt/myapp': Permission denied
原因: 你没有权限操作这个目录
解决:
# 方案1: 使用sudo(需要管理员权限)
sudo mkdir /opt/myapp
# 方案2: 在自己有权限的目录操作
mkdir ~/myapp # 你的家目录,肯定有权限
⚠️ 警告: 不要随便用sudo,先想想为什么需要!
Q7: 端口已被占用
报错示例:
Error: listen EADDRINUSE: address already in use :::3000
原因: 3000端口已经被其他程序占用
解决:
# 1. 查找占用端口的进程
lsof -i :3000
# 或
netstat -tuln | grep 3000
# 2. 杀死占用进程
kill -9 PID号
# 3. 或者换个端口运行你的应用
PORT=3001 npm start
Q8: 找不到刚创建的文件
问题: 创建了文件但ls看不到
可能原因:
# 原因1: 在错误的目录
pwd # 查看当前在哪里
# 原因2: 文件名是隐藏文件(以.开头)
ls -a # 显示隐藏文件
# 原因3: 没有读权限
ls -la # 查看权限
Q9: 复制粘贴命令报错
问题: 从网上复制的命令粘贴后报错
常见原因:
- 智能引号问题
# ❌ 错误(智能引号")
echo "Hello"
# ✅ 正确(普通引号")
echo "Hello"
- 多余的空格或换行
# 复制时带了额外的空格或换行符
# 手动重新输入命令
- 命令不完整
# 网页上的命令可能被截断了
# 确保复制完整的命令
建议: 理解命令含义后再执行,不要盲目复制粘贴!
Q10: SSH连接超时或被拒绝
报错示例:
ssh: connect to host xxx.xxx.xxx.xxx port 22: Connection refused
ssh: connect to host xxx.xxx.xxx.xxx port 22: Connection timed out
排查步骤:
# 1. 检查服务器IP是否正确
ping xxx.xxx.xxx.xxx
# 2. 检查SSH服务是否运行(在服务器上)
sudo systemctl status ssh
# 3. 检查云安全组是否开放22端口
# 登录云控制台检查
# 4. 检查防火墙
sudo ufw status
Q11: 日志文件太大打不开
问题: 几GB的日志文件,cat/vim都打不开
解决:
# ❌ 错误: 直接打开大文件
cat huge.log # 会卡死
# ✅ 正确: 只看需要的部分
tail -n 1000 huge.log # 看最后1000行
head -n 1000 huge.log # 看前1000行
# 搜索特定内容
grep "ERROR" huge.log | tail -n 100
# 清空日志(谨慎!)
> huge.log
# 或
truncate -s 0 huge.log
Q12: 忘记后台进程的PID
问题: 用nohup启动了程序,忘记记录PID号了
解决:
# 按名称查找进程
ps aux | grep python
ps aux | grep node
ps aux | grep "app.py"
# 更精确的查找
pgrep -f "app.py"
# 查看进程详细信息
ps -ef | grep app.py
Q13: 环境变量设置后不生效
问题: 设置了环境变量但还是找不到命令
原因: 配置文件没重新加载
解决:
# 1. 编辑配置文件
echo 'export PATH=$PATH:/new/path' >> ~/.bashrc
# 2. 重新加载配置(关键!)
source ~/.bashrc
# 3. 验证
echo $PATH
Q14: 空间不足(No space left on device)
报错: 磁盘空间已满
排查:
# 1. 查看磁盘使用
df -h
# 2. 查找占用空间大的目录
du -h --max-depth=1 / | sort -h | tail -10
# 3. 清理方案
# - 删除大的日志文件
find /var/log -name "*.log" -size +100M
# - 清理Docker(如果有)
docker system prune -a
# - 清理包管理器缓存
sudo apt clean
npm cache clean --force
Q15: 复制命令时忘记修改参数
常见错误:
# 从教程复制的命令
ssh username@server-ip
# ❌ 直接运行 → 肯定失败!
# ✅ 要改成你自己的用户名和IP
ssh myname@123.45.67.89
记住:
username→ 你的用户名server-ip→ 你的服务器IPyour-domain.com→ 你的域名your-password→ 你的密码
6.2 调试技巧
看懂错误信息
错误信息的结构:
command: error message
│ │
命令 错误描述
示例:
mkdir: cannot create directory '/opt/app': Permission denied
│ │ │ │
命令 操作说明 目标 具体错误
→ 翻译: mkdir命令无法创建/opt/app目录,因为权限被拒绝
→ 解决: 使用sudo或换个有权限的目录
万能调试流程
# 1. 看完整的错误信息
# 不要只看前几个字就慌了,完整读完
# 2. 复制错误信息Google
# 去掉特定的文件名/路径,只搜索通用部分
# 3. 检查拼写和路径
# 90%的错误是拼写错误
# 4. 查看命令帮助
man command # 查看手册
command --help # 查看帮助
# 5. 问AI
# "我执行xxx命令时报错: [完整错误信息],怎么解决?"
7. 总结
核心要点
-
终端是部署的基础工具
- 服务器没有图形界面,必须用终端
- SSH远程登录、查看日志、进程管理都要用终端
- 掌握终端是学习后续部署知识的前提
-
必须掌握的命令分类
- 基础导航: pwd, ls, cd (知道在哪里)
- 文件操作: mkdir, cp, mv, rm (管理文件)
- 文本查看: cat, less, tail, grep (查看和搜索)
- 部署实用: tail -f, nohup, ssh, ps, kill (必会!)
-
Vim最小生存技能
i进入编辑Esc退回命令模式:wq保存退出:q!不保存退出
-
重要提醒
- Tab键自动补全必须用
- rm命令很危险,删前三思
- 不要盲目复制粘贴命令
- 看懂错误信息再Google
实用命令速查表
| 场景 | 命令 | 说明 |
|---|---|---|
| 查看日志 | tail -f app.log | 实时监控日志 |
| 后台运行 | nohup python app.py > app.log 2>&1 & | 关闭终端不停 |
| SSH登录 | ssh user@ip | 远程登录服务器 |
| 上传文件 | scp file.txt user@ip:/path/ | 传文件到服务器 |
| 查找进程 | `ps aux | grep node` |
| 杀死进程 | kill -9 PID | 强制停止进程 |
| 查看端口 | lsof -i :3000 | 查看端口占用 |
| 磁盘空间 | df -h | 查看磁盘使用 |
学习路线图
✅ 你已完成:
01. 终端和命令行
├── 基础概念理解
├── 15个核心命令
├── 部署实用命令
├── Vim编辑器
└── 15个常见错误排查
▶ 继续学习:
02. 包管理器 npm 和 pip
├── npm install 如何工作
├── package.json 详解
├── 国内镜像配置
└── Python虚拟环境
03. Linux 权限系统
├── chmod/chown 实战
├── sudo 原理
└── 权限问题排查
04. 服务器部署
├── 用终端SSH登录 ← 用到01章知识
├── 用终端配置Nginx ← 用到Vim
├── 用终端查看日志 ← 用到tail -f
└── 用终端管理进程 ← 用到ps/kill
检查清单
学完本章,你应该能做到:
- ✅ 打开终端并知道自己在哪个目录
- ✅ 使用Tab键自动补全路径和命令
- ✅ 创建、删除、移动文件和目录
- ✅ 用Vim编辑文件并保存
- ✅ 使用tail -f查看实时日志
- ✅ 用nohup让程序后台运行
- ✅ SSH连接到远程服务器
- ✅ 查找和杀死进程
- ✅ 看懂基本的错误信息
下一步
掌握了这些基础命令后,你可以:
- ✅ SSH连接到服务器
- ✅ 在服务器上创建和编辑文件
- ✅ 查看日志排查问题
- ✅ 管理应用进程
继续学习: 02. 包管理器 npm 和 pip
包管理器 npm 和 pip
方法论: 包管理器是代码界的“应用商店“,理解它就能理解现代编程的依赖管理。
📖 本节目标
学完本节,你将理解:
- ✅ npm 和 pip 到底是什么
- ✅ package.json 和 requirements.txt 的作用
- ✅ 如何配置国内镜像源(解决下载慢)
- ✅ 虚拟环境为什么重要
预计用时: 20分钟
1. 包管理器是什么?
1.1 生活类比
包管理器 = 代码界的应用商店
| 场景 | 没有包管理器 | 有包管理器 |
|---|---|---|
| 安装软件 | 去各个网站下载,手动安装 | 一个命令搞定 |
| 更新软件 | 挨个网站检查新版本 | 一键更新所有 |
| 卸载软件 | 可能留下垃圾文件 | 干净卸载 |
| 依赖管理 | A需要B,B需要C…手动装 | 自动处理依赖链 |
1.2 为什么需要包管理器?
核心问题: 现代项目依赖几十上百个第三方库!
你的项目
├── express (后端框架)
│ ├── body-parser (依赖1)
│ ├── cookie-parser (依赖2)
│ │ └── cookie (依赖的依赖)
│ └── ...还有10个依赖
├── react (前端框架)
│ ├── react-dom (依赖1)
│ └── ...还有20个依赖
└── ...还有50个包
总共可能有300+个包需要管理!
包管理器的三大作用:
- 自动处理依赖: 你装A,它自动装上A需要的B、C、D
- 版本管理: 确保所有人用的版本一致
- 一键安装: 新人克隆项目,一个命令装齐所有依赖
2. npm - JavaScript的包管理器
2.1 npm基础概念
| 名称 | 说明 | 类比 |
|---|---|---|
| npm | Node Package Manager | App Store |
| package.json | 项目的配置文件 | 购物清单 |
| node_modules | 存放所有下载的包 | 本地仓库 |
| package-lock.json | 锁定精确版本 | 详细收据 |
2.2 安装npm
npm随Node.js一起安装,你不需要单独安装。
验证安装:
node -v
npm -v
2.3 package.json详解
创建package.json:
# 交互式创建
npm init
# 快速创建(全部默认)
npm init -y
示例文件:
{
"name": "my-project", // 项目名称
"version": "1.0.0", // 版本号
"description": "我的第一个项目", // 描述
"main": "index.js", // 入口文件
"scripts": { // 脚本命令
"start": "node server.js",
"dev": "nodemon server.js",
"build": "webpack"
},
"dependencies": { // 生产环境依赖
"express": "^4.18.2",
"mongoose": "^7.0.0"
},
"devDependencies": { // 开发环境依赖
"nodemon": "^2.0.20",
"jest": "^29.5.0"
}
}
版本号解释:
| 写法 | 含义 | 实际安装 |
|---|---|---|
"4.18.2" | 精确版本 | 只装4.18.2 |
"^4.18.2" | 兼容版本 | 4.x.x最新(不升5.x.x) |
"~4.18.2" | 补丁版本 | 4.18.x最新(不升4.19.x) |
2.4 npm常用命令
安装包
# 安装package.json中的所有依赖
npm install
# 简写
npm i
# 安装指定包(自动添加到dependencies)
npm install express
# 安装为开发依赖
npm install -D nodemon
npm install --save-dev nodemon
# 全局安装(整个电脑可用)
npm install -g pm2
卸载包
npm uninstall express
更新包
# 更新所有包
npm update
# 检查过时的包
npm outdated
运行脚本
# 运行package.json中的start脚本
npm start
# 运行自定义脚本
npm run dev
npm run build
2.5 为什么node_modules这么大?
新手困惑: 装一个小包,node_modules有几百MB!
原因:
你装的包
└── 依赖10个包
└── 这10个包又依赖50个包
└── 这50个包又依赖200个包...
最终可能有1000+个文件!
这是正常的! 包管理器帮你处理了复杂的依赖链。
优化建议:
- ✅ 把
node_modules加入.gitignore(不上传到git) - ✅ 只上传
package.json和package-lock.json - ✅ 其他人克隆后运行
npm install自动安装
3. npm镜像源配置(中国用户必看!)
3.1 为什么要配置镜像源?
问题: npm官方服务器在国外,中国访问很慢!
不配置镜像:
npm install ━━━━━━━━━━━━━━━ 5分钟... 🐌
配置镜像后:
npm install ━━━━ 10秒! ⚡
3.2 推荐镜像源
| 镜像源 | 地址 | 特点 |
|---|---|---|
| 淘宝镜像(推荐) | https://registry.npmmirror.com | 最稳定,CDN加速 |
| 腾讯云镜像 | https://mirrors.cloud.tencent.com/npm/ | 腾讯云用户快 |
| 华为云镜像 | https://repo.huaweicloud.com/repository/npm/ | 华为云用户快 |
3.3 永久配置(推荐)
# 配置淘宝镜像
npm config set registry https://registry.npmmirror.com
# 验证配置
npm config get registry
# 应该显示: https://registry.npmmirror.com
# 查看所有配置
npm config list
3.4 临时使用
# 单次安装使用镜像
npm install express --registry=https://registry.npmmirror.com
3.5 使用nrm管理镜像源(高级)
# 全局安装nrm
npm install -g nrm
# 列出可用镜像源
nrm ls
# 切换到淘宝镜像
nrm use taobao
# 测试各镜像源速度
nrm test
# 恢复到官方源
nrm use npm
4. pip - Python的包管理器
4.1 pip基础概念
| 名称 | 说明 | 类比 |
|---|---|---|
| pip | Package Installer for Python | Python的应用商店 |
| requirements.txt | 项目依赖列表 | 购物清单 |
| 虚拟环境 | 独立的Python环境 | 沙盒,隔离不同项目 |
4.2 安装pip
检查pip版本:
# Python 3
python3 -m pip --version
pip3 --version
# Windows
py -m pip --version
如果没有pip:
# Ubuntu/Debian
sudo apt update
sudo apt install python3-pip
# CentOS/RHEL
sudo yum install python3-pip
# macOS(用Homebrew)
brew install python3
4.3 requirements.txt详解
创建requirements.txt:
# 导出当前环境所有包
pip freeze > requirements.txt
示例文件:
# 生产环境依赖
Django==4.2.0
requests>=2.28.0
numpy==1.24.2
# 开发环境依赖
pytest>=7.3.0
black~=23.3.0
版本号规则:
| 写法 | 含义 |
|---|---|
==4.2.0 | 精确版本 |
>=2.28.0 | 大于等于 |
~=23.3.0 | 兼容版本(23.3.x) |
>=1.0,<2.0 | 版本范围 |
4.4 pip常用命令
安装包
# 安装单个包
pip install requests
# 指定版本
pip install Django==4.2.0
# 从requirements.txt安装
pip install -r requirements.txt
# 用户级安装(不需要sudo)
pip install --user pandas
卸载包
pip uninstall requests
查看包信息
# 列出已安装的包
pip list
# 显示包详细信息
pip show requests
# 检查可更新的包
pip list --outdated
更新包
# 更新pip自己
pip install --upgrade pip
# 更新指定包
pip install --upgrade requests
5. pip镜像源配置
5.1 推荐镜像源
| 镜像源 | 地址 | 特点 |
|---|---|---|
| 清华大学(推荐) | https://pypi.tuna.tsinghua.edu.cn/simple | 更新快,稳定 |
| 阿里云 | https://mirrors.aliyun.com/pypi/simple/ | 速度快 |
| 腾讯云 | https://mirrors.cloud.tencent.com/pypi/simple | CDN加速 |
| 豆瓣 | https://pypi.douban.com/simple/ | 老牌镜像 |
5.2 永久配置(推荐)
Linux/macOS:
# 创建配置目录
mkdir -p ~/.pip
# 编辑配置文件
vim ~/.pip/pip.conf
# 添加以下内容
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
或使用命令:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
Windows:
# 配置文件位置: C:\Users\你的用户名\pip\pip.ini
# 使用命令配置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
5.3 临时使用
# 单次安装使用镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
# 从requirements.txt安装时使用镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
5.4 验证配置
# 查看当前配置
pip config list
# 测试安装速度
pip install requests
6. Python虚拟环境(重要!)
6.1 为什么需要虚拟环境?
问题场景:
项目A 需要 Django 3.2
项目B 需要 Django 4.2
如果都装在全局:
- 只能保留一个版本
- 两个项目冲突! ❌
虚拟环境的解决方案:
全局Python环境
├── 项目A虚拟环境
│ └── Django 3.2
└── 项目B虚拟环境
└── Django 4.2
完全隔离,互不影响! ✅
6.2 创建和使用虚拟环境
创建虚拟环境:
# Unix/macOS
python3 -m venv myenv
# Windows
py -m venv myenv
激活虚拟环境:
# Unix/macOS
source myenv/bin/activate
# Windows
myenv\Scripts\activate
激活后的提示:
(myenv) ~ % ← 前面有(环境名)说明已激活
在虚拟环境中安装包:
# 确保已激活虚拟环境
(myenv) ~ % pip install django
# 查看虚拟环境中的包
(myenv) ~ % pip list
退出虚拟环境:
deactivate
6.3 虚拟环境最佳实践
-
每个项目创建独立虚拟环境
cd my-project python3 -m venv venv source venv/bin/activate -
添加到.gitignore
# .gitignore venv/ __pycache__/ *.pyc -
导出依赖
pip freeze > requirements.txt -
新成员安装环境
python3 -m venv venv source venv/bin/activate pip install -r requirements.txt
7. npm 实战场景 🔥
7.1 场景1: 初始化新项目
完整流程:
# 1. 创建项目目录
mkdir my-new-project
cd my-new-project
# 2. 初始化package.json
npm init -y
# 3. 安装常用依赖
npm install express
npm install -D nodemon
# 4. 创建启动文件
touch server.js
# 5. 配置启动脚本(手动编辑package.json)
# 在scripts中添加: "dev": "nodemon server.js"
# 6. 运行项目
npm run dev
7.2 场景2: 克隆别人的项目
操作步骤:
# 1. 克隆仓库
git clone https://github.com/username/project.git
cd project
# 2. 安装所有依赖
npm install
# 等价于 npm i
# 3. 查看可用的脚本命令
npm run
# 或查看package.json的scripts部分
# 4. 启动项目
npm start
# 或
npm run dev
7.3 场景3: 解决包版本冲突
问题: 安装某个包时报错版本冲突
# 症状
npm install package-name
# npm ERR! Could not resolve dependency...
# 解决方案1: 清除缓存重装
npm cache clean --force
rm -rf node_modules package-lock.json
npm install
# 解决方案2: 使用--legacy-peer-deps跳过冲突
npm install package-name --legacy-peer-deps
# 解决方案3: 使用--force强制安装(谨慎)
npm install package-name --force
7.4 场景4: 全局包管理
常用全局包:
# 安装常用全局工具
npm install -g pm2 # 进程管理器
npm install -g nodemon # 自动重启工具
npm install -g http-server # 快速HTTP服务器
npm install -g yarn # 另一个包管理器
# 查看全局安装的包
npm list -g --depth=0
# 查看全局包安装位置
npm root -g
# 更新全局包
npm update -g pm2
# 卸载全局包
npm uninstall -g nodemon
7.5 场景5: 查看包信息和文档
# 搜索包
npm search express
# 查看包的详细信息
npm view express
# 查看包的所有版本
npm view express versions
# 查看包的最新版本
npm view express version
# 打开包的主页
npm home express
# 打开包的GitHub仓库
npm repo express
# 打开包的issue页面
npm bugs express
7.6 场景6: 项目依赖升级
# 检查哪些包可以更新
npm outdated
# 更新所有包到package.json允许的最新版本
npm update
# 更新指定包
npm update express
# 安装包的最新版本(会修改package.json)
npm install express@latest
# 查看包的安全漏洞
npm audit
# 自动修复安全漏洞
npm audit fix
# 强制修复(可能破坏兼容性)
npm audit fix --force
7.7 npm 命令速查表
| 场景 | 命令 | 说明 |
|---|---|---|
| 项目初始化 | npm init -y | 快速创建package.json |
| 安装所有依赖 | npm install 或 npm i | 根据package.json安装 |
| 安装生产依赖 | npm i express | 自动添加到dependencies |
| 安装开发依赖 | npm i -D jest | 添加到devDependencies |
| 全局安装 | npm i -g pm2 | 整个系统可用 |
| 卸载包 | npm uninstall express | 删除包并更新package.json |
| 运行脚本 | npm start / npm run dev | 执行package.json中的scripts |
| 查看过时包 | npm outdated | 检查可更新的包 |
| 安全审计 | npm audit | 检查安全漏洞 |
| 清除缓存 | npm cache clean --force | 清理npm缓存 |
| 查看全局包 | npm list -g --depth=0 | 列出全局安装的包 |
| 查看包信息 | npm view express | 查看包的详细信息 |
8. pip 实战场景 🔥
8.1 场景1: 新项目初始化
完整流程:
# 1. 创建项目目录
mkdir my-python-project
cd my-python-project
# 2. 创建虚拟环境
python3 -m venv venv
# 3. 激活虚拟环境
source venv/bin/activate # macOS/Linux
# venv\Scripts\activate # Windows
# 4. 升级pip(推荐)
pip install --upgrade pip
# 5. 安装项目依赖
pip install django requests
# 6. 创建requirements.txt
pip freeze > requirements.txt
# 7. 创建主程序文件
touch main.py
8.2 场景2: 克隆Python项目
操作步骤:
# 1. 克隆项目
git clone https://github.com/username/project.git
cd project
# 2. 创建虚拟环境
python3 -m venv venv
# 3. 激活虚拟环境
source venv/bin/activate
# 4. 安装所有依赖
pip install -r requirements.txt
# 5. 运行项目
python main.py
# 或
python manage.py runserver # Django项目
8.3 场景3: 管理多个Python版本
使用不同Python版本创建虚拟环境:
# 查看系统中的Python版本
python3 --version
python3.11 --version
# 使用指定Python版本创建虚拟环境
python3.11 -m venv venv311
python3.10 -m venv venv310
# 激活对应环境
source venv311/bin/activate
# 验证Python版本
python --version
8.4 场景4: 依赖冲突解决
问题: 包安装失败或版本冲突
# 症状
pip install package-name
# ERROR: Could not find a version that satisfies...
# 解决方案1: 升级pip
pip install --upgrade pip
# 解决方案2: 清除缓存
pip cache purge
# 解决方案3: 指定兼容版本
pip install package-name==1.2.3
# 解决方案4: 使用pip-tools管理依赖
pip install pip-tools
pip-compile requirements.in
pip-sync
8.5 场景5: 批量管理包
# 导出当前环境所有包
pip freeze > requirements.txt
# 仅导出手动安装的包(不含依赖)
pip list --not-required
# 批量卸载所有包
pip freeze | xargs pip uninstall -y
# 从旧的requirements.txt升级所有包
pip install -r requirements.txt --upgrade
# 安装指定镜像源的包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
8.6 场景6: 开发环境和生产环境分离
创建多个requirements文件:
# requirements.txt - 生产环境基础依赖
Django==4.2.0
psycopg2-binary==2.9.6
gunicorn==20.1.0
# requirements-dev.txt - 开发环境额外依赖
-r requirements.txt # 引入基础依赖
pytest==7.3.1
black==23.3.0
flake8==6.0.0
ipython==8.12.0
# 生产环境安装
pip install -r requirements.txt
# 开发环境安装
pip install -r requirements-dev.txt
8.7 场景7: 查看和卸载包
# 列出所有已安装的包
pip list
# 查看包的详细信息
pip show django
# 查看包的依赖树
pip show django | grep Requires
# 查找包含某关键词的包
pip list | grep django
# 卸载包
pip uninstall django
# 卸载包并自动确认
pip uninstall -y django
# 卸载多个包
pip uninstall django requests numpy
8.8 pip 命令速查表
| 场景 | 命令 | 说明 |
|---|---|---|
| 安装单个包 | pip install requests | 安装最新版本 |
| 指定版本安装 | pip install Django==4.2.0 | 安装特定版本 |
| 从文件安装 | pip install -r requirements.txt | 批量安装依赖 |
| 升级包 | pip install --upgrade django | 更新到最新版 |
| 卸载包 | pip uninstall requests | 删除包 |
| 列出已装包 | pip list | 查看所有包 |
| 查看包信息 | pip show django | 查看包详情 |
| 导出依赖 | pip freeze > requirements.txt | 生成依赖列表 |
| 搜索包 | pip search keyword | 搜索PyPI包(已停用) |
| 检查可更新 | pip list --outdated | 查看过时的包 |
| 清除缓存 | pip cache purge | 清理下载缓存 |
| 使用镜像源 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package | 临时使用镜像 |
9. 虚拟环境实战技巧 🔥
9.1 快速切换虚拟环境
使用别名简化操作:
# 在 ~/.bashrc 或 ~/.zshrc 中添加
alias venv-create='python3 -m venv venv'
alias venv-on='source venv/bin/activate'
alias venv-off='deactivate'
# 使用
cd my-project
venv-on # 激活环境
venv-off # 退出环境
9.2 检查虚拟环境是否激活
# 方法1: 查看命令提示符
(venv) ~/project $ # 前面有(venv)说明已激活
# 方法2: 查看Python路径
which python
# 激活: /path/to/project/venv/bin/python
# 未激活: /usr/bin/python3
# 方法3: 查看环境变量
echo $VIRTUAL_ENV
# 激活: /path/to/project/venv
# 未激活: (空)
9.3 虚拟环境迁移
# 错误做法: 直接复制venv文件夹 ❌
# 虚拟环境包含绝对路径,不能直接复制
# 正确做法: 导出依赖重新创建 ✅
# 在旧环境
pip freeze > requirements.txt
# 在新机器/新位置
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
9.4 清理虚拟环境
# 删除虚拟环境(退出环境后)
deactivate
rm -rf venv
# 重新创建干净的环境
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
10. 常见问题
Q1: npm install很慢或失败
解决方案:
-
检查镜像源
npm config get registry如果不是镜像地址,重新配置
-
清除缓存
npm cache clean --force -
删除node_modules重装
rm -rf node_modules package-lock.json npm install
Q2: pip安装报错“Permission denied“
原因: 尝试全局安装但没有权限
解决方案(选一个):
-
使用虚拟环境(推荐)
python3 -m venv venv source venv/bin/activate pip install package -
用户级安装
pip install --user package -
使用sudo(不推荐)
sudo pip install package
Q3: 虚拟环境激活后没反应
检查:
- 路径是否正确
- Windows用户确保执行了
Scripts\activate - macOS/Linux确保执行了
source bin/activate
重新创建:
rm -rf venv
python3 -m venv venv
source venv/bin/activate
Q4: package.json和package-lock.json有什么区别?
| 文件 | 作用 | 是否提交到git |
|---|---|---|
| package.json | 记录依赖和版本范围 | ✅ 必须提交 |
| package-lock.json | 锁定精确版本号 | ✅ 必须提交 |
为什么两个都要提交?
package.json: 告诉npm需要什么包package-lock.json: 确保所有人安装的版本完全一致
8. 总结
核心要点
-
包管理器是现代编程的基础设施
- npm用于JavaScript项目
- pip用于Python项目
-
国内用户必须配置镜像源
- npm使用淘宝镜像
- pip使用清华镜像
- 速度提升10倍+
-
Python项目必须使用虚拟环境
- 避免版本冲突
- 保持项目隔离
- 便于依赖管理
-
两个配置文件不能丢
package.json/requirements.txt: 依赖列表package-lock.json: 精确版本锁定
检查清单
在开始新项目前:
- ✅ npm镜像源已配置
- ✅ pip镜像源已配置
- ✅ Python虚拟环境已创建并激活
- ✅ package.json或requirements.txt已创建
- ✅ node_modules或venv已加入.gitignore
继续学习: 03. Linux权限系统
Linux权限系统
方法论: 权限系统是Linux安全的基石,理解它就能避免90%的部署错误。
📖 本节目标
学完本节,你将理解:
- ✅ Linux权限的三个层级(所有者/组/其他人)
- ✅ sudo命令的原理和使用场景
- ✅ chmod和chown的实战应用
- ✅ 常见权限问题的解决方法
预计用时: 30分钟
1. 权限系统是什么?
1.1 生活类比
权限系统 = 房间的钥匙管理
想象你家是一栋大楼:
| 角色 | 类比 | 能做什么 |
|---|---|---|
| 房主(所有者) | 你自己 | 有这个房间的所有权限 |
| 家人(组) | 你的家人 | 可以进你的房间,但不能随便改动 |
| 访客(其他人) | 陌生人 | 只能看看,不能动 |
权限就是钥匙:
读权限(r) = 可以看房间里有什么
写权限(w) = 可以往房间里放东西/扔东西
执行权限(x) = 可以进入这个房间
1.2 为什么需要权限系统?
三大核心原因:
- 防止误操作: 你不会不小心删除系统文件
- 防止病毒破坏: 病毒程序无法修改系统核心文件
- 多用户隔离: 服务器上有多个用户,A不能看B的文件
2. 查看文件权限
2.1 使用ls -l命令
ls -l
输出示例:
-rw-r--r-- 1 user staff 1024 Nov 26 08:00 file.txt
drwxr-xr-x 5 user staff 160 Nov 25 10:30 folder/
2.2 权限字符串解读
以第一行为例: -rw-r--r--
- rw- r-- r--
│ │ │ │
│ │ │ └─ 其他人的权限: 只读
│ │ └────── 组的权限: 只读
│ └─────────── 所有者的权限: 读+写
└────────────── 文件类型(-=文件, d=目录)
文件类型:
| 符号 | 含义 |
|---|---|
- | 普通文件 |
d | 目录 |
l | 符号链接(快捷方式) |
权限符号:
| 符号 | 权限 | 数字 |
|---|---|---|
r | 读(Read) | 4 |
w | 写(Write) | 2 |
x | 执行(Execute) | 1 |
- | 无权限 | 0 |
3. 权限的数字表示法
3.1 数字与权限的对应
每个权限位的值相加:
| 数字 | 二进制 | 符号 | 说明 |
|---|---|---|---|
| 0 | 000 | --- | 无权限 |
| 1 | 001 | --x | 仅执行 |
| 2 | 010 | -w- | 仅写 |
| 3 | 011 | -wx | 写+执行 |
| 4 | 100 | r-- | 仅读 |
| 5 | 101 | r-x | 读+执行 |
| 6 | 110 | rw- | 读+写 |
| 7 | 111 | rwx | 全部权限 |
3.2 三位数字的含义
格式: 所有者 组 其他人
| 数字组合 | 符号形式 | 含义 | 典型用途 |
|---|---|---|---|
755 | rwxr-xr-x | 所有者全权,其他人只读执行 | 目录和脚本 |
644 | rw-r--r-- | 所有者读写,其他人只读 | 普通文件 |
600 | rw------- | 仅所有者可读写 | 私密文件(SSH密钥) |
700 | rwx------ | 仅所有者全权限 | 私人目录 |
777 | rwxrwxrwx | 所有人全权限 | ⚠️ 危险!不推荐 |
计算示例:
755 是怎么来的?
所有者: 7 = 4(读) + 2(写) + 1(执行) = rwx
组: 5 = 4(读) + 0 + 1(执行) = r-x
其他人: 5 = 4(读) + 0 + 1(执行) = r-x
合起来: rwxr-xr-x
4. chmod - 修改权限
4.1 数字模式(推荐)
语法: chmod 权限数字 文件名
# 设置文件为644(所有者读写,其他人只读)
chmod 644 file.txt
# 设置脚本为755(所有者全权,其他人读执行)
chmod 755 script.sh
# 设置密钥为600(仅所有者可读写)
chmod 600 ~/.ssh/id_rsa
# 递归修改整个目录
chmod -R 755 /var/www/html
4.2 符号模式
语法: chmod [用户][操作][权限] 文件名
用户符号:
u= 所有者(user)g= 组(group)o= 其他人(others)a= 所有人(all)
操作符号:
+= 添加权限-= 移除权限== 设置权限
示例:
# 给所有者添加执行权限
chmod u+x script.sh
# 给组添加写权限
chmod g+w file.txt
# 移除其他人的所有权限
chmod o-rwx private.txt
# 给所有人添加执行权限
chmod a+x program
# 精确设置权限
chmod u=rwx,g=rx,o=r file.txt
4.3 常用场景
场景1: 脚本无法执行
# 报错: Permission denied
./deploy.sh
# 解决: 添加执行权限
chmod +x deploy.sh
./deploy.sh # 现在可以运行了
场景2: Web目录权限
# 设置Web根目录
# 目录: 755 (可进入,可列出)
# 文件: 644 (可读取)
# 仅修改目录权限
find /var/www/html -type d -exec chmod 755 {} \;
# 仅修改文件权限
find /var/www/html -type f -exec chmod 644 {} \;
场景3: SSH密钥权限
# SSH密钥必须是600,否则会被拒绝
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_rsa
chmod 644 ~/.ssh/id_rsa.pub
chmod 600 ~/.ssh/authorized_keys
5. chown - 修改所有者
5.1 基本用法
语法: chown [所有者][:组] 文件名
# 修改文件所有者
sudo chown username file.txt
# 同时修改所有者和组
sudo chown username:groupname file.txt
# 仅修改组(注意冒号前面为空)
sudo chown :groupname file.txt
# 递归修改整个目录
sudo chown -R username:groupname /path/to/directory
5.2 常用场景
场景1: Web服务器文件权限
# Nginx/Apache通常以www-data用户运行
# 需要将Web文件所有权转给www-data
sudo chown -R www-data:www-data /var/www/html
sudo chmod -R 755 /var/www/html
场景2: 部署后修复权限
# 问题: 代码是root用户部署的,应用无法写入日志
# 查看当前所有者
ls -l /var/app/
# 修复: 改为应用用户
sudo chown -R appuser:appuser /var/app/
场景3: 用户主目录权限
# 给新用户设置正确的主目录权限
sudo chown -R newuser:newuser /home/newuser
sudo chmod 700 /home/newuser
6. sudo - 临时提权
6.1 sudo是什么?
sudo = Super User DO (以超级用户身份执行)
类比: 你是普通员工,需要进机房修电脑
- 你不能一直带着机房钥匙(不安全)
- 你找保安临时借钥匙
- 办完事立刻还回去
sudo就是这个过程:
- 你告诉系统“我需要临时管理员权限“
- 系统验证你的密码
- 给你临时权限执行这一条命令
- 执行完毕,权限收回
6.2 sudo基本用法
# 以root权限执行命令
sudo command
# 示例: 更新系统包
sudo apt update
# 以root权限编辑文件
sudo vim /etc/hosts
# 切换到root用户shell
sudo -i
sudo su
# 以其他用户身份执行命令
sudo -u username command
# 查看自己的sudo权限
sudo -l
6.3 什么时候需要sudo?
需要sudo的场景:
| 操作 | 为什么需要sudo | 示例 |
|---|---|---|
| 全局安装软件 | 写入系统目录 | sudo npm install -g pm2 |
| 修改系统配置 | 系统文件受保护 | sudo vim /etc/nginx/nginx.conf |
| 管理系统服务 | 服务由系统管理 | sudo systemctl restart nginx |
| 修改系统文件权限 | 安全限制 | sudo chmod 755 /var/www |
| 修改其他用户文件 | 所有权限制 | sudo chown www-data file.txt |
不需要sudo的场景:
| 操作 | 为什么不需要 | 示例 |
|---|---|---|
| 项目内安装包 | 在自己的目录 | npm install express |
| 修改自己的文件 | 你是所有者 | vim ~/project/config.js |
| 运行自己的程序 | 不涉及系统 | node server.js |
| Python虚拟环境 | 独立环境 | pip install django |
6.4 sudo的危险性 ⚠️
警告: sudo给你完全的系统控制权!
永远不要盲目执行带sudo的命令!
# 这些命令会毁掉整个系统!!! 绝对不要运行!!!
sudo rm -rf /
sudo dd if=/dev/zero of=/dev/sda
sudo chmod -R 777 /
安全原则:
- ✅ 只在确实理解命令含义时使用sudo
- ✅ 不要复制粘贴网上的sudo命令
- ✅ 如果不懂,先问AI这个命令做什么
- ✅ 开发项目时,尽量不用sudo
7. 实战案例
案例1: 部署Node.js应用
问题: 应用部署后无法写入日志
# 1. 查看当前权限
ls -l /var/app/
# 输出: drwxr-xr-x root root /var/app
# 问题: 所有者是root,但应用以appuser运行
# 2. 修复所有者
sudo chown -R appuser:appuser /var/app/
# 3. 设置正确权限
sudo chmod -R 755 /var/app/
# 4. 验证
ls -l /var/app/
# 输出: drwxr-xr-x appuser appuser /var/app
案例2: 修复SSH密钥权限
问题: SSH登录报错“Permissions too open“
# 报错信息
# Permissions 0644 for '~/.ssh/id_rsa' are too open.
# It is required that your private key files are NOT accessible by others.
# 解决方案
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_rsa
chmod 644 ~/.ssh/id_rsa.pub
# 验证
ls -la ~/.ssh/
# -rw------- id_rsa ← 600,正确!
# -rw-r--r-- id_rsa.pub ← 644,正确!
案例3: Web目录权限配置
场景: 设置Nginx Web根目录
# 1. 修改所有者为Nginx用户
sudo chown -R www-data:www-data /var/www/html
# 2. 目录权限755,文件权限644
sudo find /var/www/html -type d -exec chmod 755 {} \;
sudo find /var/www/html -type f -exec chmod 644 {} \;
# 3. 上传目录需要写权限
sudo chmod 775 /var/www/html/uploads
# 4. 验证
ls -la /var/www/html/
8. 常见问题
Q1: Permission denied
症状: 运行命令报“Permission denied“
原因分析:
# 查看文件权限
ls -l file.txt
# -rw-r--r-- user group file.txt
# 你想执行它
./file.txt
# bash: ./file.txt: Permission denied
解决方案:
# 如果是脚本,添加执行权限
chmod +x file.txt
# 如果是系统命令,可能需要sudo
sudo command
# 如果是其他用户的文件,修改所有者
sudo chown your-username file.txt
Q2: 什么权限最安全?
最小权限原则: 只给必需的权限,不多给!
| 文件类型 | 推荐权限 | 原因 |
|---|---|---|
| 私密文件(SSH密钥) | 600 | 仅自己可读写 |
| 配置文件 | 644 | 所有者可改,其他人只读 |
| 可执行文件/脚本 | 755 | 所有者可改,所有人可执行 |
| 目录 | 755 | 所有者可改,所有人可进入 |
| 上传目录 | 775 | 组用户也可写入 |
| 临时目录 | 1777 | 所有人可写,但只能删自己的文件 |
永远避免: 777权限(除非你完全理解风险)
Q3: chown和chmod的顺序?
正确顺序: 先chown,再chmod
# ✅ 正确
sudo chown www-data:www-data file.txt
sudo chmod 644 file.txt
# ❌ 错误顺序可能导致权限问题
sudo chmod 644 file.txt
sudo chown www-data:www-data file.txt
原因: 修改所有者后,权限归属改变了
Q4: 递归修改权限有风险吗?
有风险! 特别是在根目录或系统目录
# ⚠️ 危险! 不要在系统目录递归777
sudo chmod -R 777 /
# ⚠️ 危险! 可能影响系统文件
sudo chmod -R 755 /etc
# ✅ 安全: 仅在自己的项目目录
chmod -R 755 ~/my-project
安全建议:
- 使用前先用
ls -lR预览影响范围 - 只在项目目录使用递归
- 备份重要文件后再操作
- 优先使用find精确控制
9. 总结
核心要点
-
权限三层级: 所有者/组/其他人
-
权限三类型: 读(4)/写(2)/执行(1)
-
常用权限:
- 644: 普通文件
- 755: 目录和脚本
- 600: 私密文件
-
chmod: 修改权限
-
chown: 修改所有者
-
sudo: 临时提权,谨慎使用
检查清单
部署前检查:
- ✅ Web文件所有者是www-data或nginx
- ✅ 应用文件所有者是运行用户
- ✅ SSH密钥是600权限
- ✅ 配置文件是644权限
- ✅ 脚本文件有执行权限(755)
- ✅ 没有使用777权限
最小权限原则
记住: 从最严格的权限开始,按需放宽,而不是一开始就777!
继续学习: 04. 服务器部署
服务器部署
方法论: 部署不是玄学,理解架构原理后,所有问题都能迎刃而解。
📖 本节目标
学完本节,你将理解:
- ✅ 云服务器和安全组配置
- ✅ Nginx反向代理的原理和配置
- ✅ PM2进程管理器的使用
- ✅ HTTPS证书配置
- ✅ 域名解析和DNS配置
预计用时: 40分钟
1. 部署架构全景图
1.1 从用户访问到服务器响应
用户浏览器 www.yoursite.com
│
▼
域名解析(DNS) → 将域名转换为IP地址
│
▼
云服务器安全组 → 防火墙,检查是否允许访问
│
▼
Nginx反向代理 → 前台接待员,路由请求
│
├─→ 静态文件 → 直接返回HTML/CSS/JS
│
└─→ 后端API → PM2管理的Node.js/Python应用
│
└─→ 数据库 → 读取/写入数据
1.2 核心概念类比
| 组件 | 生活类比 | 作用 |
|---|---|---|
| 云服务器 | 商场大楼 | 24小时营业的电脑 |
| 安全组/防火墙 | 门禁系统 | 控制谁能进来 |
| 域名 | 商场地址 | www.yoursite.com |
| DNS | 导航地图 | 域名→IP地址 |
| Nginx | 前台接待 | 分流访客到不同部门 |
| PM2 | 部门经理 | 管理员工(进程),自动重启 |
| 应用进程 | 员工 | 处理具体业务 |
2. 云服务器和安全组
2.1 什么是云服务器?
云服务器 = 远程的24小时开机电脑
| 你的笔记本 | 云服务器 |
|---|---|
| 在你家里 | 在机房里 |
| 你关机就停止 | 24小时不停机 |
| 只有你能访问 | 全世界都能访问(如果配置正确) |
| 断网就用不了 | 多条网络线路,高可用 |
2.2 安全组配置 ⚠️ 新手必看!
最常见的部署失败原因: 忘记配置安全组!
安全组 = 云服务器的门禁系统
云安全组
用户 ─────────────> │端口80? 允许│ ────> Nginx
│端口443? 允许│
│端口3000? 拒绝│ ✗ 你的应用访问不了!
2.3 必须开放的端口
| 端口 | 协议 | 用途 | 是否必需 |
|---|---|---|---|
| 22 | SSH | 远程登录服务器 | ✅ 必需 |
| 80 | HTTP | 网站访问(HTTP) | ✅ 必需 |
| 443 | HTTPS | 网站访问(HTTPS) | ✅ 强烈推荐 |
| 3000/8000 | 自定义 | 应用直接访问 | ❌ 不推荐暴露 |
2.4 配置安全组(各云平台)
阿里云:
- 登录控制台
- 云服务器ECS → 网络与安全 → 安全组
- 配置规则 → 添加入方向规则
- 添加端口: 22, 80, 443
腾讯云:
- 登录控制台
- 云服务器 → 安全组 → 修改规则
- 入站规则 → 添加规则
- 添加端口: 22, 80, 443
AWS:
- EC2 → Security Groups
- Edit inbound rules
- Add Rule → 添加端口
验证配置:
# 在本地测试端口是否开放
telnet your-server-ip 80
telnet your-server-ip 443
# 或使用curl
curl http://your-server-ip
3. Nginx反向代理
3.1 为什么需要Nginx?
场景: 你有一个前端(React)和一个后端(Node.js)
不用Nginx的问题:
前端: http://your-ip:3000 ← 用户要记端口
后端: http://your-ip:8000 ← 两个地址,跨域问题
用Nginx后:
用户访问: https://www.yoursite.com
Nginx自动分流:
- www.yoursite.com/ → 前端静态文件
- www.yoursite.com/api/ → 后端API
一个域名,无跨域! ✅
3.2 Nginx的三大作用
| 作用 | 说明 | 类比 |
|---|---|---|
| 反向代理 | 隐藏真实服务器,统一入口 | 前台接待,分流访客 |
| 负载均衡 | 分发请求到多个服务器 | 开多个窗口,排队均匀 |
| 静态资源服务 | 高效提供HTML/CSS/JS | 自助服务区,不用麻烦后厨 |
3.3 安装Nginx
Ubuntu/Debian:
sudo apt update
sudo apt install nginx
# 启动Nginx
sudo systemctl start nginx
# 开机自启
sudo systemctl enable nginx
# 检查状态
sudo systemctl status nginx
CentOS/RHEL:
sudo yum install nginx
sudo systemctl start nginx
sudo systemctl enable nginx
验证安装:
打开浏览器,访问 http://your-server-ip
看到“Welcome to nginx!“说明成功!
3.4 Nginx配置文件
主配置文件位置:
# Ubuntu/Debian
/etc/nginx/nginx.conf
/etc/nginx/sites-available/default
# CentOS/RHEL
/etc/nginx/nginx.conf
/etc/nginx/conf.d/default.conf
基础配置示例:
# /etc/nginx/sites-available/mysite
server {
listen 80; # 监听80端口
server_name www.yoursite.com; # 你的域名
# 前端静态文件
location / {
root /var/www/mysite/dist; # 前端build后的文件夹
index index.html;
try_files $uri $uri/ /index.html; # 解决SPA刷新404
}
# 后端API代理
location /api/ {
proxy_pass http://localhost:3000; # 转发到后端
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
配置说明:
| 指令 | 作用 |
|---|---|
listen 80 | 监听HTTP请求(80端口) |
server_name | 域名或IP |
location / | 处理根路径请求 |
root | 静态文件目录 |
try_files | SPA应用防404 |
proxy_pass | 反向代理到后端 |
3.5 启用配置
# 创建软链接(Ubuntu/Debian)
sudo ln -s /etc/nginx/sites-available/mysite /etc/nginx/sites-enabled/
# 测试配置是否正确
sudo nginx -t
# 重载配置
sudo nginx -s reload
# 或重启Nginx
sudo systemctl restart nginx
3.6 解决SPA刷新404问题
问题: React/Vue应用刷新页面后404
原因: Nginx找不到物理文件/about.html
解决: 使用try_files
location / {
root /var/www/mysite/dist;
index index.html;
try_files $uri $uri/ /index.html; # 关键配置!
}
原理: 找不到文件时,返回index.html,让前端路由处理
4. PM2进程管理
4.1 为什么需要PM2?
问题: 直接运行node app.js
node app.js
# 程序崩溃了 → 应用停止! ✗
# 关闭终端 → 应用停止! ✗
# 服务器重启 → 应用不会自动启动! ✗
PM2解决方案:
- ✅ 自动崩溃重启
- ✅ 后台运行(关闭终端也不停)
- ✅ 服务器重启后自动启动
- ✅ 集群模式(多核CPU利用)
- ✅ 日志管理
- ✅ 零停机部署
4.2 安装PM2
# 全局安装PM2
sudo npm install -g pm2
# 验证安装
pm2 --version
4.3 PM2基础命令
启动应用:
# 启动应用
pm2 start app.js --name my-app
# 启动Python应用
pm2 start app.py --interpreter python3
# 集群模式(利用所有CPU核心)
pm2 start app.js -i max
管理应用:
# 查看所有应用
pm2 list
pm2 status
# 查看详细信息
pm2 show my-app
# 查看日志
pm2 logs my-app
# 实时监控
pm2 monit
重启和停止:
# 重启应用
pm2 restart my-app
# 重载应用(零停机)
pm2 reload my-app
# 停止应用
pm2 stop my-app
# 删除应用
pm2 delete my-app
# 重启所有应用
pm2 restart all
4.4 开机自启配置 ⚠️ 重要!
必须执行的两个命令:
# 1. 生成启动脚本
pm2 startup
# 会输出类似这样的命令,复制执行:
# sudo env PATH=$PATH:/usr/bin pm2 startup systemd -u username --hp /home/username
# 2. 保存当前应用列表
pm2 save
为什么两个都要?
pm2 startup: 让系统启动时启动PM2pm2 save: 告诉PM2启动时要运行哪些应用
验证:
# 重启服务器
sudo reboot
# 重新登录后检查
pm2 list
# 你的应用应该自动运行了!
4.5 使用ecosystem.config.js
创建配置文件:
pm2 init
编辑ecosystem.config.js:
module.exports = {
apps: [
{
name: 'my-app', // 应用名称
script: './server.js', // 启动文件
instances: 2, // 进程数量(或'max')
exec_mode: 'cluster', // 集群模式
env: { // 环境变量
NODE_ENV: 'development',
PORT: 3000
},
env_production: {
NODE_ENV: 'production',
PORT: 8000
},
error_file: './logs/err.log', // 错误日志
out_file: './logs/out.log', // 输出日志
log_date_format: 'YYYY-MM-DD HH:mm:ss',
merge_logs: true,
autorestart: true, // 自动重启
watch: false, // 文件变化重启(开发用)
max_memory_restart: '1G' // 内存超限重启
}
]
};
使用配置文件:
# 启动
pm2 start ecosystem.config.js
# 生产环境启动
pm2 start ecosystem.config.js --env production
# 更新配置后重启
pm2 restart ecosystem.config.js
5. HTTPS和SSL证书
5.1 为什么需要HTTPS?
HTTP的问题:
- ❌ 数据明文传输,容易被窃听
- ❌ 浏览器显示“不安全“
- ❌ 小程序/PWA必须HTTPS
- ❌ SEO排名更低
HTTPS的好处:
- ✅ 数据加密传输
- ✅ 浏览器显示安全锁
- ✅ 提升用户信任
- ✅ SEO更好
5.2 使用Let’s Encrypt免费证书
Let’s Encrypt = 免费、自动化、开放的证书颁发机构
安装Certbot:
# Ubuntu/Debian
sudo apt update
sudo apt install certbot python3-certbot-nginx
# CentOS/RHEL
sudo yum install certbot python3-certbot-nginx
自动配置Nginx:
# Certbot会自动修改Nginx配置
sudo certbot --nginx -d www.yoursite.com -d yoursite.com
# 按提示输入邮箱,同意协议
# 选择是否重定向HTTP到HTTPS(推荐选Yes)
Certbot做了什么:
- 验证你拥有这个域名
- 下载SSL证书
- 自动修改Nginx配置
- 设置HTTPS监听
- 设置HTTP→HTTPS重定向
配置自动续期:
# Let's Encrypt证书90天过期,需要自动续期
# 测试续期
sudo certbot renew --dry-run
# 设置自动续期(已自动配置,无需手动)
# Certbot会创建systemd定时器或cron任务
验证HTTPS:
打开浏览器,访问 https://www.yoursite.com
看到🔒安全锁,说明成功!
5.3 手动配置HTTPS(高级)
如果使用自己的证书:
server {
listen 443 ssl http2;
server_name www.yoursite.com;
# SSL证书配置
ssl_certificate /etc/nginx/ssl/cert.pem; # 证书
ssl_certificate_key /etc/nginx/ssl/key.pem; # 私钥
# SSL优化配置
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# 其他配置...
location / {
root /var/www/mysite;
index index.html;
}
}
# HTTP自动跳转HTTPS
server {
listen 80;
server_name www.yoursite.com;
return 301 https://$server_name$request_uri;
}
6. 域名和DNS配置
6.1 域名解析原理
用户输入: www.yoursite.com
│
▼
DNS服务器: "这个域名对应IP是 123.45.67.89"
│
▼
浏览器访问: http://123.45.67.89
6.2 DNS记录类型
| 记录类型 | 作用 | 示例 |
|---|---|---|
| A记录 | 域名→IPv4地址 | www.yoursite.com → 123.45.67.89 |
| AAAA记录 | 域名→IPv6地址 | www.yoursite.com → 2001:db8::1 |
| CNAME记录 | 域名→域名(别名) | blog.yoursite.com → www.yoursite.com |
| MX记录 | 邮件服务器 | 邮箱相关 |
| TXT记录 | 文本信息 | 域名验证 |
6.3 配置DNS解析
常见域名服务商:
- 阿里云(万网)
- 腾讯云DNSPod
- Cloudflare
- GoDaddy
- Namecheap
配置步骤 (以阿里云为例):
- 登录域名控制台
- 找到你的域名 → 解析
- 添加记录
示例配置:
| 记录类型 | 主机记录 | 记录值 | TTL |
|---|---|---|---|
| A | www | 123.45.67.89 | 600 |
| A | @ | 123.45.67.89 | 600 |
| CNAME | blog | www.yoursite.com | 600 |
记录说明:
www: 访问www.yoursite.com@: 访问yoursite.com(根域名)*: 泛解析(所有子域名)
TTL: 缓存时间(秒)
- 600 = 10分钟
- 3600 = 1小时
6.4 验证DNS解析
# 查询域名的A记录
nslookup www.yoursite.com
# 或使用dig(更详细)
dig www.yoursite.com
# 查看解析到的IP
ping www.yoursite.com
DNS生效时间: 通常5分钟到24小时
7. 完整部署流程
7.1 前端打包详解
7.1.1 为什么要打包?
打包 = 把开发代码变成浏览器能高效运行的代码
| 开发环境代码 | 生产环境代码(打包后) |
|---|---|
| 多个JS文件 | 合并成几个文件 |
| 有注释、有空格 | 压缩、混淆 |
| 完整的错误提示 | 最小化体积 |
| React JSX语法 | 转换成纯JS |
| ES6+新语法 | 转换成ES5兼容代码 |
| 图片原始大小 | 压缩优化 |
打包前后对比:
开发环境:
src/
├── App.jsx (5KB, JSX语法)
├── Header.jsx (3KB)
├── Footer.jsx (2KB)
├── utils.js (4KB)
└── ...50个文件
打包后:
dist/
├── index.html (2KB)
├── main.abc123.js (120KB, 压缩混淆)
└── main.abc123.css (15KB, 压缩)
体积减少60%+, 文件数量减少90%+
加载速度提升3-5倍! ⚡
7.1.2 打包前的准备
检查package.json的scripts:
{
"scripts": {
"dev": "vite", // 开发服务器
"build": "vite build", // 生产打包
"preview": "vite preview" // 预览打包结果
}
}
常见框架的打包命令:
| 框架 | 打包命令 | 输出目录 |
|---|---|---|
| Create React App | npm run build | build/ |
| Vite (React/Vue) | npm run build | dist/ |
| Next.js | npm run build | .next/ |
| Vue CLI | npm run build | dist/ |
7.1.3 环境变量配置
为什么需要环境变量?
开发环境和生产环境的API地址不同:
开发: http://localhost:3000/api
生产: https://api.yoursite.com/api
创建环境变量文件:
# .env.development (开发环境)
VITE_API_URL=http://localhost:3000
VITE_APP_NAME=MyApp Dev
# .env.production (生产环境)
VITE_API_URL=https://api.yoursite.com
VITE_APP_NAME=MyApp
在代码中使用:
// Vite项目
const apiUrl = import.meta.env.VITE_API_URL;
// Create React App项目
const apiUrl = process.env.REACT_APP_API_URL;
⚠️ 重要:
- 环境变量必须以
VITE_或REACT_APP_开头才会暴露给前端 - 不要在前端环境变量中存储密钥!
7.1.4 执行打包
标准打包流程:
# 1. 安装依赖(如果还没装)
npm install
# 2. 执行打包
npm run build
# 打包过程输出示例:
# vite v4.3.0 building for production...
# ✓ 123 modules transformed.
# dist/index.html 2.15 kB
# dist/assets/index-abc123.js 142.35 kB │ gzip: 45.23 kB
# dist/assets/index-abc123.css 15.67 kB │ gzip: 4.12 kB
# ✓ built in 3.45s
# 3. 检查打包结果
ls dist/
# index.html assets/ favicon.ico
打包成功的标志:
- ✅ 没有报错
- ✅ 生成了
dist/或build/文件夹 - ✅ 文件夹里有
index.html - ✅ 有打包后的 JS 和 CSS 文件
7.1.5 本地预览打包结果
为什么要预览?
打包后的代码可能和开发环境表现不同,需要本地测试!
# Vite项目
npm run preview
# ➜ Local: http://localhost:4173/
# 或使用http-server
npx http-server dist -p 8080
# 或使用serve
npx serve -s dist -p 8080
打开浏览器访问,检查:
- ✅ 页面能正常显示
- ✅ 路由跳转正常(SPA应用)
- ✅ API请求正常
- ✅ 打开控制台,没有错误
7.1.6 常见打包错误
错误1: 内存溢出
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
解决:
# 增加Node.js内存限制
NODE_OPTIONS=--max_old_space_size=4096 npm run build
错误2: 环境变量未定义
ReferenceError: process is not defined
原因: 直接使用了 process.env 而不是框架提供的方式
解决:
// ❌ 错误
const apiUrl = process.env.API_URL;
// ✅ 正确(Vite)
const apiUrl = import.meta.env.VITE_API_URL;
// ✅ 正确(CRA)
const apiUrl = process.env.REACT_APP_API_URL;
错误3: 路径引用错误
Failed to load resource: net::ERR_FILE_NOT_FOUND
/assets/logo.png 404
原因: 静态资源路径不对
解决:
// vite.config.js
export default {
base: '/', // 或 '/your-subpath/'
}
// 确保图片放在public/文件夹
public/
└── logo.png
// 代码中引用
<img src="/logo.png" />
错误4: 打包体积过大
(!) Some chunks are larger than 500kb after minification
解决 - 代码分割:
// 使用动态导入
const MyComponent = React.lazy(() => import('./MyComponent'));
// 路由懒加载
const About = lazy(() => import('./pages/About'));
7.1.7 打包优化建议
1. 分析打包体积:
# Vite项目
npm run build -- --report
# 或使用rollup-plugin-visualizer
npm install --save-dev rollup-plugin-visualizer
2. 代码分割:
- ✅ 路由懒加载
- ✅ 组件懒加载
- ✅ 第三方库分离
3. 压缩优化:
- ✅ 图片压缩(TinyPNG)
- ✅ 启用Gzip压缩(Nginx配置)
- ✅ 移除console.log
4. CDN加速:
// vite.config.js
export default {
build: {
rollupOptions: {
external: ['react', 'react-dom'],
output: {
globals: {
react: 'React',
'react-dom': 'ReactDOM'
}
}
}
}
}
7.2 前端部署
# 1. 本地构建
npm run build
# 生成dist/文件夹
# 2. 上传到服务器
scp -r dist/* user@your-server:/var/www/mysite/
# 或使用rsync
rsync -avz dist/ user@your-server:/var/www/mysite/
# 3. 设置权限
sudo chown -R www-data:www-data /var/www/mysite
sudo chmod -R 755 /var/www/mysite
# 4. 配置Nginx
sudo vim /etc/nginx/sites-available/mysite
# 5. 测试并重载
sudo nginx -t
sudo nginx -s reload
7.3 后端部署
# 1. 上传代码到服务器
git clone https://github.com/yourname/yourproject.git
cd yourproject
# 2. 安装依赖
npm install --production
# 或 pip install -r requirements.txt
# 3. 配置环境变量
cp .env.example .env
vim .env
# 4. 用PM2启动
pm2 start server.js --name my-api
# 5. 配置开机自启
pm2 startup
pm2 save
# 6. 查看日志
pm2 logs my-api
7.4 完整Nginx配置
# /etc/nginx/sites-available/mysite
server {
listen 80;
server_name www.yoursite.com yoursite.com;
# 重定向到HTTPS
return 301 https://www.yoursite.com$request_uri;
}
server {
listen 443 ssl http2;
server_name www.yoursite.com;
# SSL证书(Certbot自动配置)
ssl_certificate /etc/letsencrypt/live/www.yoursite.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/www.yoursite.com/privkey.pem;
# 前端静态文件
location / {
root /var/www/mysite/dist;
index index.html;
try_files $uri $uri/ /index.html;
}
# 后端API
location /api/ {
proxy_pass http://localhost:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# 静态资源缓存
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
root /var/www/mysite/dist;
expires 30d;
add_header Cache-Control "public, immutable";
}
}
8. 常见问题排查
Q1: 访问域名显示502 Bad Gateway
原因: Nginx无法连接到后端
排查步骤:
# 1. 后端应用是否运行?
pm2 list
# 2. 端口是否正确?
netstat -tuln | grep 3000
# 3. 防火墙是否阻止?
sudo ufw status
# 4. 查看Nginx错误日志
sudo tail -f /var/log/nginx/error.log
# 5. 查看应用日志
pm2 logs my-app
Q2: 域名无法访问
排查步骤:
# 1. DNS是否解析正确?
nslookup www.yoursite.com
# 2. 服务器IP是否正确?
ping www.yoursite.com
# 3. 云安全组是否开放80/443?
# 登录云控制台检查
# 4. Nginx是否运行?
sudo systemctl status nginx
# 5. Nginx配置是否正确?
sudo nginx -t
Q3: HTTPS证书错误
排查:
# 1. 证书是否过期?
sudo certbot certificates
# 2. 手动续期
sudo certbot renew
# 3. 强制重新获取
sudo certbot --nginx -d www.yoursite.com --force-renew
Q4: PM2应用重启后停止
原因: 没有配置开机自启
# 重新配置
pm2 startup
# 复制输出的命令执行
pm2 save
# 验证
sudo reboot
# 重启后检查
pm2 list
9. 部署检查清单
部署前
- ✅ 代码在本地测试通过
- ✅ 环境变量配置正确
- ✅ package.json依赖完整
- ✅ .gitignore配置正确
服务器配置
- ✅ 云安全组开放80/443/22端口
- ✅ Node.js/Python环境已安装
- ✅ npm/pip镜像源已配置
- ✅ Nginx已安装并运行
应用部署
- ✅ 代码已上传到服务器
- ✅ 依赖已安装(npm install/pip install)
- ✅ PM2应用已启动
- ✅ PM2开机自启已配置(startup+save)
- ✅ 应用日志无错误
Nginx配置
- ✅ 静态文件路径正确
- ✅ 反向代理配置正确
- ✅ SPA应用try_files配置
- ✅ nginx -t测试通过
- ✅ 配置已重载
HTTPS配置
- ✅ SSL证书已配置
- ✅ HTTP自动跳转HTTPS
- ✅ 浏览器显示安全锁
DNS配置
- ✅ A记录已添加
- ✅ DNS解析生效
- ✅ 域名可以访问
10. 总结
核心要点
-
部署三件套:
- Nginx: 前台接待(反向代理)
- PM2: 部门经理(进程管理)
- 云安全组: 门禁系统(防火墙)
-
HTTPS是必需的:
- 使用Let’s Encrypt免费证书
- Certbot自动配置
- 自动续期
-
DNS解析:
- A记录指向服务器IP
- 等待5分钟-24小时生效
-
PM2必须配置开机自启:
pm2 startuppm2 save- 两个都要!
典型错误
| 错误 | 原因 | 解决 |
|---|---|---|
| 502 Bad Gateway | 后端没运行 | 检查PM2 |
| 403 Forbidden | 权限不对 | chown+chmod |
| 无法访问 | 安全组没开 | 开放端口 |
| 证书错误 | 证书过期 | certbot renew |
| 重启后应用停止 | 没保存PM2 | pm2 save |
下一步
恭喜!你已经掌握了完整的部署流程。
继续深入:
- 学习Docker容器化部署
- 学习CI/CD自动化部署
- 学习Kubernetes集群管理
- 学习监控和日志分析
记住: 部署出问题是正常的,重要的是学会看日志排查!
Docker容器化部署(可选)
方法论: Docker是现代部署的标准方式,理解“集装箱“类比,就能理解容器化。
📖 本节目标
学完本节,你将理解:
- ✅ Docker是什么,为什么要用它
- ✅ Dockerfile编写和镜像构建
- ✅ docker-compose多容器编排
- ✅ 完整的容器化部署流程
预计用时: 35分钟
前置要求:
- ✅ 已学习04章服务器部署
- ✅ 理解前后端分离架构
1. Docker是什么?
1.1 生活类比
Docker = 集装箱运输系统
| 传统部署 | Docker容器化 |
|---|---|
| 散装货物(直接装车) | 标准集装箱 |
| 每种货物装法不同 | 所有集装箱规格统一 |
| 换车很麻烦 | 集装箱可以直接吊到任何车上 |
| 装卸慢,容易损坏 | 快速装卸,保护货物 |
软件部署中:
传统部署:
你的电脑 (Node 16, Ubuntu 20) ✅ 能运行
测试服务器 (Node 14, CentOS 7) ❌ 出错了!
生产服务器 (Node 18, Ubuntu 22) ❌ 又出错!
容器化部署:
你的电脑 (Docker) ✅ 容器运行正常
测试服务器 (Docker) ✅ 同样的容器,一样运行
生产服务器 (Docker) ✅ 同样的容器,一样运行
"在我电脑上能跑" 不再是玩笑!
1.2 Docker解决的核心问题
问题1: 环境不一致
开发: macOS + Node 18 + Python 3.11
服务器: Ubuntu + Node 16 + Python 3.9
结果: 代码在本地能跑,服务器跑不起来!
Docker解决: 把应用和环境打包在一起
问题2: 依赖冲突
项目A 需要 Node 14
项目B 需要 Node 18
同一台服务器上怎么办?
Docker解决: 每个项目独立容器,互不影响
问题3: 部署复杂
传统部署步骤:
1. 安装Node.js
2. 安装MySQL
3. 配置Nginx
4. 安装Redis
5. 配置防火墙
6. ...20个步骤
Docker部署:
docker-compose up -d
一个命令启动所有服务! ⚡
1.3 核心概念
| 概念 | 类比 | 说明 |
|---|---|---|
| 镜像(Image) | 集装箱模板 | 只读的应用模板,包含代码和环境 |
| 容器(Container) | 实际运行的集装箱 | 镜像的运行实例 |
| Dockerfile | 集装箱制造图纸 | 定义如何构建镜像 |
| Docker Hub | 集装箱仓库 | 存储和分享镜像 |
| docker-compose | 多个集装箱一起管理 | 编排多个容器 |
关系图:
Dockerfile (图纸)
│
▼ docker build
Image (模板)
│
▼ docker run
Container (运行中的应用)
2. 安装Docker
2.1 Linux安装(Ubuntu)
# 1. 更新包列表
sudo apt update
# 2. 安装依赖
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
# 3. 添加Docker官方GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 4. 添加Docker仓库
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 5. 安装Docker
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io
# 6. 安装docker-compose
sudo apt install -y docker-compose-plugin
# 7. 验证安装
docker --version
docker compose version
2.2 macOS/Windows安装
macOS:
- 下载 Docker Desktop for Mac
- 拖拽到Applications
- 启动Docker Desktop
Windows:
- 下载 Docker Desktop for Windows
- 运行安装程序
- 启动Docker Desktop(需要WSL2)
2.3 配置国内镜像加速
# 创建配置文件
sudo mkdir -p /etc/docker
sudo vim /etc/docker/daemon.json
# 添加以下内容
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://mirror.ccs.tencentyun.com"
]
}
# 重启Docker
sudo systemctl restart docker
# 验证
docker info | grep -A 5 "Registry Mirrors"
2.4 允许非root用户使用Docker
# 添加当前用户到docker组
sudo usermod -aG docker $USER
# 重新登录或执行
newgrp docker
# 测试
docker ps
# 不需要sudo了!
3. Dockerfile编写
3.1 Dockerfile基础语法
| 指令 | 作用 | 示例 |
|---|---|---|
FROM | 基础镜像 | FROM node:18-alpine |
WORKDIR | 工作目录 | WORKDIR /app |
COPY | 复制文件 | COPY package.json . |
RUN | 执行命令(构建时) | RUN npm install |
CMD | 默认命令(运行时) | CMD ["npm", "start"] |
EXPOSE | 暴露端口 | EXPOSE 3000 |
ENV | 环境变量 | ENV NODE_ENV=production |
3.2 前端Dockerfile示例
# Dockerfile (前端React/Vue项目)
# 阶段1: 构建阶段
FROM node:18-alpine AS builder
WORKDIR /app
# 复制package.json
COPY package*.json ./
# 安装依赖
RUN npm install
# 复制源代码
COPY . .
# 打包
RUN npm run build
# 阶段2: 运行阶段(多阶段构建,减小镜像体积)
FROM nginx:alpine
# 复制打包结果到Nginx
COPY --from=builder /app/dist /usr/share/nginx/html
# 复制Nginx配置(可选)
# COPY nginx.conf /etc/nginx/conf.d/default.conf
# 暴露80端口
EXPOSE 80
# 启动Nginx
CMD ["nginx", "-g", "daemon off;"]
为什么用多阶段构建?
单阶段:
镜像大小: 1.2GB (包含Node.js, npm, 源代码, node_modules...)
多阶段:
镜像大小: 25MB (只包含Nginx和打包后的静态文件)
体积减少98%! ⚡
3.3 后端Dockerfile示例
# Dockerfile (Node.js后端)
FROM node:18-alpine
# 安装dumb-init(更好的进程管理)
RUN apk add --no-cache dumb-init
# 设置工作目录
WORKDIR /app
# 非root用户运行(安全)
RUN addgroup -g 1001 -S nodejs && \
adduser -S nodejs -u 1001
# 复制package.json
COPY --chown=nodejs:nodejs package*.json ./
# 安装生产依赖
RUN npm ci --only=production
# 复制源代码
COPY --chown=nodejs:nodejs . .
# 切换到非root用户
USER nodejs
# 暴露端口
EXPOSE 3000
# 使用dumb-init启动
CMD ["dumb-init", "node", "server.js"]
3.4 Python后端Dockerfile示例
# Dockerfile (Python FastAPI)
FROM python:3.11-slim
WORKDIR /app
# 安装系统依赖
RUN apt-get update && \
apt-get install -y --no-install-recommends gcc && \
rm -rf /var/lib/apt/lists/*
# 复制requirements.txt
COPY requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制源代码
COPY . .
# 创建非root用户
RUN useradd -m -u 1000 appuser && \
chown -R appuser:appuser /app
USER appuser
# 暴露端口
EXPOSE 8000
# 启动应用
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
4. 构建和运行镜像
4.1 构建镜像
# 基本构建
docker build -t my-app:latest .
# -t: 镜像标签(名称:版本)
# .: Dockerfile所在目录
# 指定Dockerfile
docker build -t my-app -f Dockerfile.prod .
# 查看构建过程
docker build -t my-app --progress=plain .
4.2 运行容器
# 基本运行
docker run -d -p 3000:3000 --name my-container my-app
# -d: 后台运行
# -p 宿主机端口:容器端口
# --name: 容器名称
# 带环境变量
docker run -d \
-p 3000:3000 \
-e NODE_ENV=production \
-e DATABASE_URL=mysql://... \
--name my-app \
my-app:latest
# 挂载数据卷
docker run -d \
-p 3000:3000 \
-v $(pwd)/data:/app/data \
--name my-app \
my-app
4.3 常用管理命令
# 查看运行中的容器
docker ps
# 查看所有容器(包括停止的)
docker ps -a
# 查看容器日志
docker logs my-container
docker logs -f my-container # 实时查看
# 进入容器
docker exec -it my-container /bin/sh
# 停止容器
docker stop my-container
# 启动容器
docker start my-container
# 重启容器
docker restart my-container
# 删除容器
docker rm my-container
docker rm -f my-container # 强制删除运行中的容器
# 删除镜像
docker rmi my-app:latest
# 清理未使用的资源
docker system prune -a
5. docker-compose编排
5.1 为什么需要docker-compose?
场景: 一个完整的Web应用
需要运行:
- 前端容器
- 后端容器
- 数据库容器
- Redis缓存容器
- Nginx代理容器
手动运行5个docker run命令? 太麻烦!
docker-compose解决:
# 一个配置文件管理所有容器
docker-compose.yml
# 一个命令启动所有服务
docker compose up -d
5.2 docker-compose.yml示例
version: '3.8'
services:
# 前端服务
frontend:
build:
context: ./frontend
dockerfile: Dockerfile
ports:
- "80:80"
depends_on:
- backend
networks:
- app-network
# 后端服务
backend:
build:
context: ./backend
dockerfile: Dockerfile
ports:
- "3000:3000"
environment:
- NODE_ENV=production
- DATABASE_URL=mysql://root:password@db:3306/myapp
- REDIS_URL=redis://redis:6379
depends_on:
- db
- redis
networks:
- app-network
restart: unless-stopped
# 数据库
db:
image: mysql:8.0
environment:
- MYSQL_ROOT_PASSWORD=password
- MYSQL_DATABASE=myapp
volumes:
- db-data:/var/lib/mysql
networks:
- app-network
restart: unless-stopped
# Redis缓存
redis:
image: redis:7-alpine
networks:
- app-network
restart: unless-stopped
# 数据卷
volumes:
db-data:
# 网络
networks:
app-network:
driver: bridge
5.3 docker-compose命令
# 启动所有服务
docker compose up -d
# 查看服务状态
docker compose ps
# 查看日志
docker compose logs
docker compose logs -f backend # 查看某个服务
# 重启服务
docker compose restart backend
# 停止所有服务
docker compose stop
# 停止并删除所有容器
docker compose down
# 停止并删除所有容器+数据卷
docker compose down -v
# 重新构建并启动
docker compose up -d --build
6. 实战: 完整项目容器化
6.1 项目结构
my-project/
├── frontend/
│ ├── src/
│ ├── package.json
│ └── Dockerfile
├── backend/
│ ├── src/
│ ├── package.json
│ └── Dockerfile
├── docker-compose.yml
└── .dockerignore
6.2 .dockerignore配置
# .dockerignore (放在Dockerfile同级目录)
node_modules
npm-debug.log
.env
.git
.gitignore
README.md
dist
build
.DS_Store
6.3 完整部署流程
# 1. 克隆代码
git clone https://github.com/yourname/project.git
cd project
# 2. 配置环境变量
cp .env.example .env
vim .env
# 3. 启动所有服务
docker compose up -d --build
# 4. 查看日志
docker compose logs -f
# 5. 访问应用
# http://your-server-ip
# 6. 进入容器调试
docker compose exec backend sh
# 7. 重启某个服务
docker compose restart backend
# 8. 查看资源使用
docker stats
7. 镜像优化技巧
7.1 选择合适的基础镜像
| 镜像 | 大小 | 适用场景 |
|---|---|---|
node:18 | 1GB | 开发环境 |
node:18-slim | 200MB | 轻量生产环境 |
node:18-alpine | 120MB | 最小化生产环境 |
# ✅ 推荐: alpine镜像
FROM node:18-alpine
# ❌ 不推荐: 完整镜像
FROM node:18
7.2 利用构建缓存
# ✅ 正确顺序: 先复制package.json
COPY package*.json ./
RUN npm install
COPY . .
# ❌ 错误顺序: 代码变化导致重新安装依赖
COPY . .
RUN npm install
7.3 多阶段构建
# 构建阶段: 包含开发工具
FROM node:18 AS builder
RUN npm run build
# 运行阶段: 只包含必需文件
FROM node:18-alpine
COPY --from=builder /app/dist ./dist
7.4 清理缓存
# ✅ 一条RUN命令,减少层数
RUN apt-get update && \
apt-get install -y gcc && \
rm -rf /var/lib/apt/lists/*
# ❌ 多条RUN,增加镜像大小
RUN apt-get update
RUN apt-get install -y gcc
RUN rm -rf /var/lib/apt/lists/*
8. 生产环境最佳实践
8.1 安全性
# ✅ 使用非root用户
RUN adduser -D appuser
USER appuser
# ✅ 只暴露必需端口
EXPOSE 3000
# ✅ 使用secrets管理密钥
# docker compose secrets
8.2 健康检查
# Dockerfile添加健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=40s \
CMD node healthcheck.js || exit 1
# docker-compose.yml
services:
backend:
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
8.3 日志管理
services:
backend:
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
8.4 资源限制
services:
backend:
deploy:
resources:
limits:
cpus: '0.5'
memory: 512M
reservations:
cpus: '0.25'
memory: 256M
9. Docker 实战场景 🔥
9.1 场景1: 从零部署一个前端应用
完整流程:
# 1. 进入前端项目目录
cd my-react-app
# 2. 创建Dockerfile
cat > Dockerfile <<'EOF'
FROM node:18-alpine AS builder
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
FROM nginx:alpine
COPY --from=builder /app/dist /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
EOF
# 3. 创建.dockerignore
echo "node_modules
.git
.env" > .dockerignore
# 4. 构建镜像
docker build -t my-app:v1.0 .
# 5. 运行容器
docker run -d -p 80:80 --name my-app my-app:v1.0
# 6. 验证
curl http://localhost
# 7. 查看日志
docker logs my-app
9.2 场景2: 快速启动开发环境
使用docker-compose快速启动数据库:
# 创建docker-compose.yml
cat > docker-compose.yml <<'EOF'
version: '3.8'
services:
mysql:
image: mysql:8.0
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: myapp
volumes:
- mysql-data:/var/lib/mysql
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
mysql-data:
EOF
# 启动所有服务
docker compose up -d
# 连接MySQL测试
mysql -h 127.0.0.1 -u root -ppassword
# 停止所有服务
docker compose down
9.3 场景3: 容器调试和排错
进入容器内部调试:
# 进入运行中的容器
docker exec -it my-app sh
# 在容器内执行命令
docker exec my-app ls -la /app
# 查看容器内的文件
docker exec my-app cat /etc/nginx/nginx.conf
# 复制文件到容器
docker cp local-file.txt my-app:/app/
# 从容器复制文件出来
docker cp my-app:/var/log/nginx/error.log ./
# 查看容器详细信息
docker inspect my-app
# 查看容器资源使用
docker stats my-app
# 查看容器进程
docker top my-app
9.4 场景4: 镜像管理
镜像的完整生命周期:
# 查看本地镜像
docker images
# 搜索Docker Hub上的镜像
docker search nginx
# 拉取镜像
docker pull nginx:alpine
# 给镜像打标签
docker tag my-app:v1.0 myregistry.com/my-app:v1.0
# 推送到远程仓库
docker push myregistry.com/my-app:v1.0
# 删除本地镜像
docker rmi my-app:v1.0
# 删除所有未使用的镜像
docker image prune -a
# 查看镜像历史
docker history my-app:v1.0
# 保存镜像为tar文件
docker save -o my-app.tar my-app:v1.0
# 从tar文件加载镜像
docker load -i my-app.tar
9.5 场景5: 容器更新和回滚
零停机更新应用:
# 1. 构建新版本镜像
docker build -t my-app:v2.0 .
# 2. 启动新容器(不同端口测试)
docker run -d -p 8080:80 --name my-app-v2 my-app:v2.0
# 3. 测试新版本
curl http://localhost:8080
# 4. 如果测试通过,停止旧容器
docker stop my-app
# 5. 删除旧容器
docker rm my-app
# 6. 启动新容器到80端口
docker run -d -p 80:80 --name my-app my-app:v2.0
# 如果新版本有问题,快速回滚:
# 停止新版本
docker stop my-app
docker rm my-app
# 重新启动旧版本
docker run -d -p 80:80 --name my-app my-app:v1.0
9.6 场景6: 批量容器管理
一键操作多个容器:
# 停止所有运行的容器
docker stop $(docker ps -q)
# 删除所有停止的容器
docker container prune
# 删除所有容器(包括运行中的)
docker rm -f $(docker ps -aq)
# 按名称过滤删除
docker rm -f $(docker ps -a | grep "my-app" | awk '{print $1}')
# 查看所有容器(包括停止的)
docker ps -a
# 查看容器占用的磁盘空间
docker system df
# 清理所有未使用的资源
docker system prune -a --volumes
9.7 场景7: 日志管理
查看和管理容器日志:
# 查看容器日志
docker logs my-app
# 实时跟踪日志
docker logs -f my-app
# 查看最后100行日志
docker logs --tail 100 my-app
# 查看带时间戳的日志
docker logs -t my-app
# 查看最近30分钟的日志
docker logs --since 30m my-app
# 查看某时间段的日志
docker logs --since 2024-01-01T00:00:00 my-app
# 导出日志到文件
docker logs my-app > app.log 2>&1
9.8 场景8: 网络管理
容器网络配置:
# 查看所有网络
docker network ls
# 创建自定义网络
docker network create my-network
# 在自定义网络中运行容器
docker run -d --name app1 --network my-network nginx
# 将容器连接到网络
docker network connect my-network my-app
# 从网络断开容器
docker network disconnect my-network my-app
# 查看网络详情
docker network inspect my-network
# 删除网络
docker network rm my-network
# 容器间通信示例
docker run -d --name db --network my-network mysql
docker run -d --name app --network my-network \
-e DB_HOST=db \ # 直接用容器名作为主机名
my-app
9.9 Docker 命令速查表
| 场景 | 命令 | 说明 |
|---|---|---|
| 镜像操作 | ||
| 构建镜像 | docker build -t my-app:v1.0 . | 从Dockerfile构建 |
| 查看镜像 | docker images | 列出本地镜像 |
| 拉取镜像 | docker pull nginx:alpine | 从仓库下载 |
| 删除镜像 | docker rmi my-app:v1.0 | 删除本地镜像 |
| 清理镜像 | docker image prune -a | 删除未使用镜像 |
| 容器操作 | ||
| 运行容器 | docker run -d -p 80:80 --name app nginx | 后台运行 |
| 查看容器 | docker ps | 运行中的容器 |
| 查看所有 | docker ps -a | 包括停止的 |
| 停止容器 | docker stop app | 优雅停止 |
| 启动容器 | docker start app | 启动已停止的 |
| 重启容器 | docker restart app | 重启容器 |
| 删除容器 | docker rm app | 删除停止的容器 |
| 强制删除 | docker rm -f app | 删除运行中的 |
| 调试操作 | ||
| 查看日志 | docker logs -f app | 实时日志 |
| 进入容器 | docker exec -it app sh | 交互式shell |
| 查看进程 | docker top app | 容器内进程 |
| 查看统计 | docker stats app | 资源使用 |
| 查看详情 | docker inspect app | 完整配置 |
| Compose操作 | ||
| 启动服务 | docker compose up -d | 后台启动所有 |
| 停止服务 | docker compose down | 停止并删除 |
| 查看状态 | docker compose ps | 服务状态 |
| 查看日志 | docker compose logs -f | 所有服务日志 |
| 重启服务 | docker compose restart | 重启所有服务 |
| 清理操作 | ||
| 清理容器 | docker container prune | 删除停止的容器 |
| 清理镜像 | docker image prune -a | 删除未使用镜像 |
| 清理全部 | docker system prune -a | 清理所有未使用资源 |
9.10 Docker Compose 实战技巧
环境变量管理:
# 创建.env文件
cat > .env <<'EOF'
MYSQL_ROOT_PASSWORD=secretpassword
MYSQL_DATABASE=myapp
REDIS_PORT=6379
APP_PORT=3000
EOF
# docker-compose.yml使用环境变量
version: '3.8'
services:
db:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD}
MYSQL_DATABASE: ${MYSQL_DATABASE}
app:
build: .
ports:
- "${APP_PORT}:3000"
多环境配置:
# docker-compose.yml - 基础配置
# docker-compose.dev.yml - 开发环境
# docker-compose.prod.yml - 生产环境
# 开发环境启动
docker compose -f docker-compose.yml -f docker-compose.dev.yml up -d
# 生产环境启动
docker compose -f docker-compose.yml -f docker-compose.prod.yml up -d
10. 常见问题
Q1: 容器内时间不对
解决:
services:
backend:
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
Q2: 容器无法访问宿主机MySQL
原因: MySQL绑定了127.0.0.1
解决:
# 修改MySQL配置
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
# 改为
bind-address = 0.0.0.0
# 重启MySQL
sudo systemctl restart mysql
Q3: 修改代码后没生效
原因: 需要重新构建镜像
# 重新构建
docker compose up -d --build
# 或强制重建
docker compose build --no-cache
docker compose up -d
Q4: 容器启动失败
排查步骤:
# 1. 查看容器日志
docker compose logs backend
# 2. 查看容器状态
docker compose ps
# 3. 进入容器调试
docker compose exec backend sh
# 4. 检查端口冲突
netstat -tuln | grep 3000
11. 总结
核心要点
-
Docker = 标准化的运行环境
- 一次打包,到处运行
- 环境一致性
- 快速部署
-
Dockerfile编写原则
- 使用alpine镜像
- 多阶段构建
- 利用构建缓存
- 非root用户运行
-
docker-compose编排
- 一个文件管理所有服务
- 一个命令启动/停止
- 网络和数据卷自动管理
-
生产环境要点
- 健康检查
- 日志管理
- 资源限制
- 安全配置
Docker 命令记忆口诀
镜像三步: build(构建) → pull(拉取) → rmi(删除) 容器三步: run(运行) → stop(停止) → rm(删除) 调试三板斧: logs(日志) → exec(进入) → inspect(检查) Compose三连: up(启动) → ps(查看) → down(停止)
常用操作速查
# 快速启动MySQL开发环境
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=pass mysql:8.0
# 快速启动Redis
docker run -d -p 6379:6379 redis:alpine
# 查看运行容器
docker ps
# 停止所有容器
docker stop $(docker ps -q)
# 清理所有未使用资源
docker system prune -a
检查清单
Docker化项目前检查:
- ✅ Dockerfile编写完成
- ✅ .dockerignore配置正确
- ✅ docker-compose.yml编写完成
- ✅ 环境变量配置
- ✅ 本地测试通过
- ✅ 数据持久化(volumes)
- ✅ 健康检查配置
- ✅ 非root用户运行
实战学习路径
第1周: 基础命令
├── docker run/stop/rm
├── docker images/ps
└── docker logs/exec
第2周: Dockerfile
├── 编写Dockerfile
├── 多阶段构建
└── 镜像优化
第3周: docker-compose
├── 编写docker-compose.yml
├── 多容器编排
└── 环境变量管理
第4周: 生产实践
├── 容器监控
├── 日志管理
├── 性能优化
└── 安全加固
下一步
- 学习Kubernetes(K8s)容器编排
- 学习CI/CD自动化部署
- 学习Docker Swarm集群
- 学习监控和日志收集
记住: Docker不是万能的,但它解决了部署一致性问题!
Vibecoding教程培训 完整的服务器部署与终端操作指南
涵盖npm、pip、Linux命令、vim编辑器和服务器部署的核心知识
目录
- npm包管理器详解 1.1 npm安装与配置 1.2 npm常用命令 1.3 npm国内镜像源配置
- pip包管理器详解 2.1 pip安装与配置 2.2 pip常用命令 2.3 pip国内镜像源配置
- Linux终端权限管理 3.1 理解Linux权限系统 3.2 sudo命令详解 3.3 文件权限管理
- Linux常用命令全集 4.1 文件与目录操作 4.2 文本处理命令 4.3 系统管理命令
- Vim编辑器完全指南 5.1 Vim模式详解 5.2 Vim基本操作 5.3 Vim配置优化
- 服务器部署核心知识 6.1 SSH安全配置 6.2 防火墙管理 6.3 进程与服务管理 6.4 环境变量配置
- npm包管理器详解 npm(Node Package Manager)是Node.js的默认包管理器,用于安装、管理和发布JavaScript包。根据npm官方文档的最新指引,强烈建议使用Node版本管理器(如nvm)来安装Node.js和npm,而不是直接使用Node安装器,以避免权限错误问题。
1.1 npm安装与配置 检查npm版本 在开始之前,先检查系统中是否已安装npm及其版本:
检查Node.js版本 node –version # 检查npm版本 npm –version
使用nvm安装(推荐方法) 根据npm官方推荐,使用nvm(Node Version Manager)可以轻松管理多个Node.js版本。
macOS/Linux安装nvm
下载并安装nvm curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.0/install.sh | bash # 重新加载shell配置 source ~/.bashrc # 安装最新LTS版本的Node.js nvm install –lts # 设置默认版本 nvm use –lts nvm alias default node
Windows安装nvm-windows
1. 从GitHub下载nvm-windows安装器 # https://github.com/coreybutler/nvm-windows/releases # 2. 运行安装器并按提示完成安装 # 3. 打开新的命令提示符窗口,安装Node.js nvm install lts nvm use lts
直接安装Node.js(备用方法) 如果无法使用nvm,可以从Node.js官网下载安装器。对于Linux用户,npm官方文档推荐使用NodeSource安装器。
Ubuntu/Debian使用NodeSource安装 curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - sudo apt-get install -y nodejs # RHEL/CentOS使用NodeSource安装 curl -fsSL https://rpm.nodesource.com/setup_lts.x | sudo bash - sudo yum install -y nodejs
更新npm到最新版本
全局更新npm npm install -g npm@latest
1.2 npm常用命令 npm提供了丰富的命令来管理项目依赖。以下是最常用的npm命令及其详细说明:
命令 说明 示例
npm init 初始化新的npm项目,创建package.json npm init -y
npm install 安装package.json中的所有依赖 npm install
npm install
常用国内镜像源地址 镜像源名称 地址 说明 淘宝镜像(推荐) https://registry.npmmirror.com 阿里云CDN加速,稳定快速 腾讯云镜像 https://mirrors.cloud.tencent.com/npm/ 腾讯云提供的镜像服务 华为云镜像 https://repo.huaweicloud.com/repository/npm/ 华为云镜像源 npm官方源 https://registry.npmjs.org/ 官方源(国外访问快) 永久配置镜像源(推荐)
配置淘宝镜像源(永久生效) npm config set registry https://registry.npmmirror.com # 验证配置是否成功 npm config get registry # 查看所有npm配置 npm config list
临时使用镜像源 如果只想在单次安装时使用镜像源,可以使用–registry参数:
临时使用淘宝镜像安装包 npm install express –registry=https://registry.npmmirror.com
使用nrm管理镜像源 nrm是一个npm源管理工具,可以快速切换不同的镜像源:
全局安装nrm npm install -g nrm # 列出可用的镜像源 nrm ls # 切换到淘宝镜像 nrm use taobao # 测试镜像源速度 nrm test # 恢复到官方源 nrm use npm
手动编辑.npmrc配置文件 配置文件位于用户主目录下的~/.npmrc(Linux/macOS)或C:\Users\用户名.npmrc(Windows):
编辑配置文件 nano ~/.npmrc # 添加以下内容: registry=https://registry.npmmirror.com disturl=https://npmmirror.com/dist sass_binary_site=https://npmmirror.com/mirrors/node-sass phantomjs_cdnurl=https://npmmirror.com/mirrors/phantomjs electron_mirror=https://npmmirror.com/mirrors/electron/
配置验证
配置完成后,可以尝试安装一个包来验证镜像源是否生效:
npm install lodash 如果下载速度明显提升,说明镜像源配置成功。
- pip包管理器详解 pip是Python的标准包管理工具,用于安装和管理Python软件包。根据Python官方打包指南,pip从Python 3.4开始已经内置在Python安装包中。
2.1 pip安装与配置 检查pip版本
Python 3环境检查pip版本 python3 -m pip –version # 或者直接使用pip命令 pip3 –version # Windows系统 py -m pip –version
使用ensurepip安装pip(推荐) 根据官方文档,首先尝试使用Python标准库中的ensurepip模块:
Unix/macOS系统 python3 -m ensurepip –default-pip # Windows系统 py -m ensurepip –default-pip # 升级pip到最新版本 python3 -m pip install –upgrade pip
使用get-pip.py安装(备用方法) 如果ensurepip不可用,可以使用官方推荐的get-pip.py脚本:
1. 下载get-pip.py脚本 curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 或使用wget wget https://bootstrap.pypa.io/get-pip.py # 2. 运行安装脚本 python3 get-pip.py # Windows系统 py get-pip.py
Ubuntu/Debian系统安装pip
更新软件包列表 sudo apt update # 安装pip for Python 3 sudo apt install python3-pip # 验证安装 pip3 –version
CentOS/RHEL系统安装pip
安装EPEL仓库 sudo yum install epel-release # 安装pip sudo yum install python3-pip # 验证安装 pip3 –version
2.2 pip常用命令 以下是pip最常用的命令,基于Python官方文档整理:
命令 说明 示例
pip install 安装包 pip3 install requests
pip install ==版本 安装指定版本 pip3 install Django==3.2.0
pip install >=版本 安装版本范围 pip3 install numpy>=1.21.0
pip install =版本 安装兼容版本 pip3 install flask=2.0.0
pip install –upgrade 升级包到最新版本 pip3 install –upgrade pip
pip uninstall 卸载包 pip3 uninstall requests
pip list 列出已安装的包 pip3 list
pip show 显示包的详细信息 pip3 show requests
pip freeze 导出已安装包列表 pip3 freeze > requirements.txt
pip install -r 从文件安装依赖 pip3 install -r requirements.txt
pip search 搜索包(已弃用) 建议使用PyPI网站搜索
pip install –user 用户级安装 pip3 install –user pandas
requirements.txt使用方法
根据官方指南,requirements.txt是管理项目依赖的标准方式:
requirements.txt文件内容示例 requests>=2.25.0 numpy==1.21.0 pandas>=1.3.0,<2.0.0 flask~=2.0.0 Django>=3.2,<4.0 # 安装requirements.txt中的所有依赖 pip3 install -r requirements.txt # 导出当前环境的所有包到requirements.txt pip3 freeze > requirements.txt
Python虚拟环境配置 虚拟环境是Python项目管理的最佳实践,可以为每个项目创建独立的包环境。官方文档推荐使用内置的venv模块:
Unix/macOS创建虚拟环境 python3 -m venv myproject_env # 激活虚拟环境 source myproject_env/bin/activate # Windows创建虚拟环境 py -m venv myproject_env # Windows激活虚拟环境 myproject_env\Scripts\activate # 在虚拟环境中安装包 pip install requests # 退出虚拟环境 deactivate
虚拟环境最佳实践
为每个项目创建独立的虚拟环境 将虚拟环境目录添加到.gitignore 使用requirements.txt管理依赖 定期更新pip和包版本 避免在全局环境中安装包 2.3 pip国内镜像源配置 在中国大陆地区,配置国内镜像源可以显著提升pip下载速度。根据镜像配置指南,以下是常用的国内镜像源。
常用国内镜像源地址 镜像源名称 地址 说明 清华大学镜像(推荐) https://pypi.tuna.tsinghua.edu.cn/simple 更新及时,稳定可靠 阿里云镜像 https://mirrors.aliyun.com/pypi/simple/ 阿里云CDN加速 腾讯云镜像 https://mirrors.cloud.tencent.com/pypi/simple 腾讯云提供 华为云镜像 https://repo.huaweicloud.com/repository/pypi/simple 华为云镜像源 豆瓣镜像 https://pypi.douban.com/simple/ 老牌镜像源 官方源 https://pypi.org/simple PyPI官方源 临时使用镜像源 在单次安装时使用-i参数指定镜像源:
临时使用清华镜像源 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple requests # 临时使用阿里云镜像源 pip3 install -i https://mirrors.aliyun.com/pypi/simple/ numpy # 从requirements.txt安装时使用镜像源 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
永久配置镜像源(推荐) 根据配置指南,通过修改pip配置文件实现永久配置:
Linux/macOS配置方法
创建pip配置目录 mkdir -p ~/.pip # 编辑配置文件 nano ~/.pip/pip.conf # 添加以下内容(使用清华源): [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple trusted-host = pypi.tuna.tsinghua.edu.cn # 或使用命令行快速配置 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
Windows配置方法
配置文件位置:C:\Users\用户名\pip\pip.ini # 方法1:直接使用命令配置 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # 方法2:手动创建配置文件 # 在 C:\Users\用户名\ 目录下创建 pip 文件夹 # 在 pip 文件夹中创建 pip.ini 文件,内容如下: [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple trusted-host = pypi.tuna.tsinghua.edu.cn
验证镜像源配置
查看当前配置的镜像源 pip config list # 或查看配置文件内容 cat ~/.pip/pip.conf # 测试安装速度 pip3 install requests
镜像源选择建议
清华大学镜像:综合推荐,更新及时,稳定性好 阿里云镜像:CDN加速,适合阿里云服务器 腾讯云镜像:适合腾讯云服务器用户 建议根据地理位置和网络环境选择最快的镜像源 遇到包不存在时,可临时切换回官方源尝试 3. Linux终端权限管理 Linux权限系统是系统安全的基础。根据DigitalOcean权限管理指南,理解和正确配置文件权限对于服务器安全至关重要。
3.1 理解Linux权限系统 权限的三种类型 权限类型 符号 数字 文件含义 目录含义 读权限 r 4 可以读取文件内容 可以列出目录内容 写权限 w 2 可以修改文件内容 可以在目录中创建/删除文件 执行权限 x 1 可以执行文件 可以进入目录 权限的三个级别 级别 符号 说明 所有者(Owner) u 文件/目录的创建者 组(Group) g 文件所属的用户组 其他人(Others) o 系统上的其他所有用户 权限数字表示法 根据DigitalOcean指南,权限可以用三位数字表示,每位是对应权限值的和:
数字 二进制 权限 说明 0 000 — 无权限 1 001 –x 仅执行 2 010 -w- 仅写入 3 011 -wx 写入和执行 4 100 r– 仅读取 5 101 r-x 读取和执行 6 110 rw- 读取和写入 7 111 rwx 全部权限 常见权限组合示例
755:rwxr-xr-x(所有者全部权限,组和其他人读取+执行)- 常用于目录和可执行文件 644:rw-r–r–(所有者读写,组和其他人只读)- 常用于普通文件 600:rw—––(仅所有者可读写)- 用于私密文件如SSH密钥 700:rwx——(仅所有者全部权限)- 用于私人目录 777:rwxrwxrwx(所有人全部权限)- 不推荐使用,存在安全风险 查看文件权限
查看文件详细信息(包括权限) ls -l filename # 查看目录及其内容的权限 ls -la /path/to/directory # 输出示例: # -rw-r–r– 1 user group 1234 Nov 25 10:00 file.txt # drwxr-xr-x 2 user group 4096 Nov 25 10:00 directory # 第一列解析: # 第1位:文件类型(-=文件,d=目录,l=链接) # 第2-4位:所有者权限 # 第5-7位:组权限 # 第8-10位:其他人权限
3.2 sudo命令详解 sudo(Super User Do)允许普通用户以超级用户(root)权限执行命令,是Linux系统管理的核心工具。
sudo基本用法
以root权限执行单个命令 sudo command # 示例:更新系统包 sudo apt update # 以root权限编辑文件 sudo nano /etc/hosts # 切换到root用户shell sudo -i sudo su # 以其他用户身份执行命令 sudo -u username command # 查看sudo权限 sudo -l
配置sudo权限
编辑sudoers文件(务必使用visudo命令) sudo visudo # 将用户添加到sudo组(Ubuntu/Debian) sudo usermod -aG sudo username # 将用户添加到wheel组(CentOS/RHEL) sudo usermod -aG wheel username # 在sudoers文件中添加用户权限示例: # username ALL=(ALL:ALL) ALL # 允许用户无密码执行所有命令(谨慎使用): # username ALL=(ALL) NOPASSWD: ALL
sudo使用注意事项
永远使用visudo编辑sudoers文件:直接编辑可能导致语法错误,使系统无法使用sudo 避免长期使用root账户:应该使用sudo按需提权 定期审查sudo日志:检查/var/log/auth.log或/var/log/secure 限制NOPASSWD使用:仅对特定命令开启无密码sudo sudo会话超时:默认15分钟内不需要重新输入密码 3.3 文件权限管理 chmod命令 - 修改文件权限 根据DigitalOcean指南,chmod支持数字模式和符号模式两种方式。
数字模式 - 直接设置权限 chmod 755 file.sh chmod 644 config.txt chmod 600 private_key # 符号模式 - 增加权限 chmod u+x script.sh # 给所有者添加执行权限 chmod g+w file.txt # 给组添加写权限 chmod o+r document.pdf # 给其他人添加读权限 chmod a+x program # 给所有人添加执行权限 # 符号模式 - 移除权限 chmod u-x file # 移除所有者的执行权限 chmod g-w file # 移除组的写权限 chmod o-rwx file # 移除其他人的所有权限 # 符号模式 - 设置权限 chmod u=rwx,g=rx,o=r file # 精确设置各级别权限 # 递归修改目录权限 chmod -R 755 /var/www/html # 仅修改目录权限(不影响文件) find /path -type d -exec chmod 755 {} ; # 仅修改文件权限(不影响目录) find /path -type f -exec chmod 644 {} ;
chown命令 - 修改文件所有者
修改文件所有者 sudo chown username file.txt # 同时修改所有者和组 sudo chown username:groupname file.txt # 仅修改组 sudo chown :groupname file.txt # 递归修改目录所有者 sudo chown -R username:groupname /var/www/html # Web服务器常用配置 sudo chown -R www-data:www-data /var/www/html sudo chmod -R 755 /var/www/html
chgrp命令 - 修改文件所属组
修改文件所属组 sudo chgrp groupname file.txt # 递归修改目录所属组 sudo chgrp -R developers /opt/project
特殊权限位 权限 符号 数字 作用 SUID s(所有者位置) 4000 执行文件时以文件所有者身份运行 SGID s(组位置) 2000 目录中创建的文件继承目录的组 Sticky Bit t 1000 仅文件所有者可删除自己的文件
设置SUID(如/usr/bin/passwd) sudo chmod 4755 /path/to/file # 设置SGID(如/tmp目录) sudo chmod 2755 /path/to/directory # 设置Sticky Bit(如/tmp目录) sudo chmod 1777 /tmp
权限管理最佳实践
根据DigitalOcean指南,遵循以下最佳实践:
最小权限原则:从最严格的权限开始(如755/644),按需增加 使用组管理协作:通过组权限实现团队协作,而非开放给所有人 避免使用777权限:除非绝对必要,否则不要使用777权限 递归操作前先检查:使用ls -lR预览影响范围 脚本需要执行权限:记得给脚本添加chmod +x Web目录标准权限:目录755,文件644,确保Web服务器可访问 私钥文件权限:SSH私钥必须是600权限,否则会被拒绝使用 常见权限问题解决 基于DigitalOcean的故障排除指南:
问题1:脚本无法执行
症状:运行脚本时提示“Permission denied“
解决方案:添加执行权限 chmod +x script.sh ./script.sh
问题2:Web服务器无法访问文件
症状:网页显示403 Forbidden错误
解决方案:设置正确的所有者和权限 sudo chown -R www-data:www-data /var/www/html sudo chmod -R 755 /var/www/html sudo chmod -R 644 /var/www/html/*.html
问题3:SSH密钥被拒绝
症状:SSH提示“Permissions are too open“
解决方案:修正密钥权限 chmod 700 ~/.ssh chmod 600 ~/.ssh/id_rsa chmod 644 ~/.ssh/id_rsa.pub chmod 600 ~/.ssh/authorized_keys
- Linux常用命令全集 掌握Linux命令是系统管理的基础。根据DigitalOcean的Linux命令指南,以下是50多个最常用且最重要的命令。
4.1 文件与目录操作 基本导航命令
pwd - 显示当前工作目录 pwd # ls - 列出目录内容 ls # 基本列表 ls -l # 长格式(显示权限、大小等) ls -la # 包括隐藏文件 ls -lh # 人类可读的文件大小 ls -lt # 按修改时间排序 ls -lS # 按文件大小排序 # cd - 切换目录 cd /path/to/directory # 切换到指定目录 cd ~ # 切换到家目录 cd .. # 返回上级目录 cd - # 返回上一个目录 cd # 切换到家目录
文件和目录创建
touch - 创建空文件或更新时间戳 touch newfile.txt touch file1.txt file2.txt file3.txt # mkdir - 创建目录 mkdir new_directory mkdir -p parent/child/grandchild # 递归创建 mkdir -m 755 secure_dir # 创建时设置权限 # rmdir - 删除空目录 rmdir empty_directory
文件复制、移动和删除
cp - 复制文件或目录 cp source.txt destination.txt cp file.txt /path/to/directory/ cp -r directory/ /backup/ # 递归复制目录 cp -i file.txt dest.txt # 覆盖前提示 cp -u *.txt /backup/ # 仅复制更新的文件 # mv - 移动或重命名文件 mv oldname.txt newname.txt # 重命名 mv file.txt /path/to/directory/ # 移动文件 mv -i file.txt dest/ # 覆盖前提示 # rm - 删除文件或目录 rm file.txt # 删除文件 rm -i file.txt # 删除前确认 rm -r directory/ # 递归删除目录 rm -rf directory/ # 强制删除(谨慎使用) rm *.tmp # 删除所有.tmp文件
危险命令警告
以下命令极其危险,使用前请三思:
永远不要执行这些命令! rm -rf / # 删除整个系统(已被现代系统阻止) rm -rf /* # 删除根目录下所有内容 rm -rf $HOME # 删除整个主目录 # 使用rm -rf时,务必先用ls确认路径正确 ls /path/to/delete rm -rf /path/to/delete
文件查看命令
cat - 查看文件内容 cat file.txt # 显示整个文件 cat -n file.txt # 显示行号 cat file1.txt file2.txt > combined.txt # 合并文件 # less - 分页查看文件(推荐) less file.txt # 快捷键:空格=下一页,b=上一页,q=退出,/搜索 # more - 分页查看文件(传统) more file.txt # head - 查看文件开头 head file.txt # 默认显示前10行 head -n 20 file.txt # 显示前20行 # tail - 查看文件结尾 tail file.txt # 默认显示后10行 tail -n 50 file.txt # 显示后50行 tail -f /var/log/syslog # 实时监控日志文件
文件查找和定位
find - 在目录树中查找文件 find . -name “.txt” # 查找所有txt文件 find /var/log -name “.log” # 在指定目录查找 find . -type f -name “.py” # 仅查找文件 find . -type d -name “backup” # 仅查找目录 find . -mtime -7 # 查找7天内修改的文件 find . -size +100M # 查找大于100MB的文件 find . -name “.tmp” -delete # 查找并删除 # locate - 快速查找文件(使用数据库) locate filename sudo updatedb # 更新locate数据库 # which - 查找命令的可执行文件位置 which python3 which node # whereis - 查找二进制文件、源代码和手册页 whereis sudo
文件链接
ln - 创建链接 ln -s /path/to/file linkname # 创建符号链接(软链接) ln /path/to/file hardlink # 创建硬链接 # 查看链接 ls -l linkname readlink -f linkname # 显示链接的真实路径
4.2 文本处理命令 根据DigitalOcean指南,以下是最强大的文本处理工具。
grep - 文本搜索
基本搜索 grep “pattern” file.txt # 在文件中搜索模式 grep -i “pattern” file.txt # 忽略大小写 grep -v “pattern” file.txt # 显示不匹配的行 grep -n “pattern” file.txt # 显示行号 grep -c “pattern” file.txt # 统计匹配行数 # 递归搜索 grep -r “pattern” /path/to/directory # 递归搜索目录 grep -r –include=“*.py” “pattern” . # 仅搜索指定类型文件 # 正则表达式搜索 grep -E “^ERROR|^WARN” logfile # 扩展正则表达式 grep -P “\d{3}-\d{3}-\d{4}” file # Perl正则表达式 # 组合使用 ps aux | grep nginx # 搜索进程 history | grep ssh # 搜索命令历史
sed - 流编辑器
替换文本 sed ‘s/old/new/’ file.txt # 替换每行第一个匹配 sed ‘s/old/new/g’ file.txt # 替换所有匹配 sed ‘s/old/new/gi’ file.txt # 忽略大小写替换 # 就地编辑文件 sed -i ‘s/old/new/g’ file.txt # 直接修改文件 sed -i.bak ‘s/old/new/g’ file.txt # 修改前备份 # 删除行 sed ‘/pattern/d’ file.txt # 删除匹配的行 sed ‘5d’ file.txt # 删除第5行 sed ‘1,3d’ file.txt # 删除第1到3行 # 插入和追加 sed ‘2i\New line’ file.txt # 在第2行前插入 sed ‘2a\New line’ file.txt # 在第2行后追加 # 指定行范围替换 sed ‘2,5s/old/new/g’ file.txt # 仅在第2-5行替换
awk - 文本分析工具
打印列 awk ‘{print $1}’ file.txt # 打印第一列 awk ‘{print $1, $3}’ file.txt # 打印第1和第3列 awk ‘{print $NF}’ file.txt # 打印最后一列 # 使用分隔符 awk -F’:’ ‘{print $1}’ /etc/passwd # 使用:作为分隔符 awk -F’,’ ‘{print $2}’ data.csv # 处理CSV文件 # 条件过滤 awk ‘$3 > 100’ file.txt # 第3列大于100的行 awk ‘/pattern/ {print $1}’ file.txt # 匹配模式后打印第1列 # 计算和统计 awk ‘{sum+=$1} END {print sum}’ file.txt # 求和第1列 awk ‘{sum+=$1; count++} END {print sum/count}’ file.txt # 求平均值 # 格式化输出 awk ‘{printf “%-10s %5d\n”, $1, $2}’ file.txt
其他文本处理命令
sort - 排序 sort file.txt # 字母排序 sort -n file.txt # 数字排序 sort -r file.txt # 逆序 sort -k2 file.txt # 按第2列排序 sort -u file.txt # 排序并去重 # uniq - 去重(需要先排序) sort file.txt | uniq # 去除重复行 sort file.txt | uniq -c # 统计重复次数 sort file.txt | uniq -d # 仅显示重复行 # wc - 字数统计 wc file.txt # 显示行数、字数、字节数 wc -l file.txt # 仅显示行数 wc -w file.txt # 仅显示字数 wc -c file.txt # 仅显示字节数 # cut - 切割文本 cut -d’:’ -f1 /etc/passwd # 提取第1列 cut -d’,’ -f2-4 data.csv # 提取第2-4列 cut -c1-10 file.txt # 提取每行的前10个字符 # tr - 字符转换 tr ‘a-z’ ‘A-Z’ < file.txt # 转换为大写 tr -d ‘\r’ < file.txt # 删除回车符 tr -s ’ ’ < file.txt # 压缩连续空格 # diff - 比较文件差异 diff file1.txt file2.txt diff -u file1.txt file2.txt # 统一格式输出 diff -y file1.txt file2.txt # 并排显示
4.3 系统管理命令 系统信息
uname - 系统信息 uname -a # 显示所有系统信息 uname -r # 显示内核版本 uname -m # 显示系统架构 # hostname - 主机名 hostname # 显示主机名 hostname -I # 显示所有IP地址 # whoami - 当前用户 whoami # uptime - 系统运行时间 uptime # date - 日期时间 date date “+%Y-%m-%d %H:%M:%S” # 格式化输出
进程管理
ps - 查看进程 ps # 显示当前终端进程 ps aux # 显示所有进程详细信息 ps aux | grep nginx # 查找特定进程 # top - 实时进程监控 top # 交互式进程查看器 # 快捷键:h=帮助,q=退出,k=杀死进程,P=按CPU排序,M=按内存排序 # htop - 增强版top(需要安装) htop # kill - 终止进程 kill PID # 优雅终止进程 kill -9 PID # 强制终止进程 killall process_name # 按名称终止所有进程 # pkill - 按名称终止进程 pkill nginx pkill -u username # 终止某用户的所有进程 # jobs - 后台任务 jobs # 列出后台任务 command & # 在后台运行命令 fg %1 # 将后台任务1调到前台 bg %1 # 继续后台任务1
磁盘和存储
df - 磁盘空间使用情况 df -h # 人类可读格式 df -i # 显示inode使用情况 # du - 目录空间使用 du -h /path/to/directory # 显示目录大小 du -sh /path/to/directory # 仅显示总大小 du -sh * | sort -h # 排序显示当前目录各项大小 # mount - 挂载文件系统 mount # 显示已挂载的文件系统 sudo mount /dev/sdb1 /mnt # 挂载设备 sudo umount /mnt # 卸载 # lsblk - 列出块设备 lsblk
网络命令
ping - 测试网络连通性 ping google.com ping -c 4 google.com # 发送4个数据包后停止 # curl - 传输数据 curl https://api.example.com # GET请求 curl -o file.zip https://example.com/file.zip # 下载文件 curl -I https://example.com # 仅获取HTTP头 # wget - 下载文件 wget https://example.com/file.zip wget -c https://example.com/file.zip # 断点续传 # netstat - 网络统计(传统) netstat -tuln # 显示监听的端口 netstat -a # 显示所有连接 # ss - 套接字统计(现代替代品) ss -tuln # 显示监听的端口 ss -s # 显示统计摘要 # ip - 网络配置(现代) ip addr show # 显示网络接口 ip route show # 显示路由表 # ifconfig - 网络配置(传统) ifconfig
包管理
Ubuntu/Debian (apt) sudo apt update # 更新包列表 sudo apt upgrade # 升级所有包 sudo apt install package_name # 安装包 sudo apt remove package_name # 卸载包 sudo apt autoremove # 清理不需要的包 # CentOS/RHEL (yum/dnf) sudo yum update # 更新系统 sudo yum install package_name # 安装包 sudo yum remove package_name # 卸载包 # 或使用dnf(较新系统) sudo dnf install package_name
压缩和归档
tar - 打包和解包 tar -cvf archive.tar files/ # 创建tar归档 tar -xvf archive.tar # 解包tar归档 tar -czvf archive.tar.gz files/ # 创建gzip压缩归档 tar -xzvf archive.tar.gz # 解压gzip归档 tar -cjvf archive.tar.bz2 files/ # 创建bzip2压缩归档 tar -xjvf archive.tar.bz2 # 解压bzip2归档 # zip/unzip zip -r archive.zip directory/ # 创建zip压缩包 unzip archive.zip # 解压zip文件 unzip -l archive.zip # 列出zip内容而不解压 # gzip/gunzip gzip file.txt # 压缩文件(生成file.txt.gz) gunzip file.txt.gz # 解压文件
命令组合技巧
Linux命令的真正威力在于组合使用:
管道(|)- 将一个命令的输出传递给另一个命令 ps aux | grep nginx | awk ‘{print $2}’ # 重定向(>、>>)- 将输出保存到文件 ls -l > filelist.txt # 覆盖写入 echo “new line” >> file.txt # 追加写入 # 命令替换 $() - 使用命令的输出 echo “Today is $(date)” rm $(find . -name “*.tmp”) # 逻辑操作符 command1 && command2 # command1成功后才执行command2 command1 || command2 # command1失败后才执行command2 command1 ; command2 # 依次执行,不管成功失败
- Vim编辑器完全指南 Vim是Linux系统中最强大的文本编辑器之一。根据freeCodeCamp的Vim初学者指南,掌握Vim可以大幅提升文本编辑效率。
5.1 Vim模式详解 Vim有四种主要模式,理解这些模式是掌握Vim的关键:
模式 说明 进入方式 退出方式 Normal Mode (命令模式) 默认模式,用于导航和执行命令 启动Vim时的默认模式 按Esc从其他模式返回 Insert Mode (插入模式) 用于输入和编辑文本 按i, a, o等 按Esc返回Normal模式 Visual Mode (可视模式) 用于选择文本块 按v(字符), V(行), Ctrl+v(块) 按Esc返回Normal模式 Command-Line Mode (命令行模式) 用于执行Ex命令 按:, /, ? 按Enter执行或Esc取消 启动Vim
启动Vim vim # 打开或创建文件 vim filename.txt # 以只读模式打开 vim -R filename.txt view filename.txt # 打开文件并跳到指定行 vim +10 filename.txt # 打开多个文件 vim file1.txt file2.txt
- 5.2 Vim基本操作 进入插入模式 命令 说明 i 在光标前插入 a 在光标后插入 I 在行首插入 A 在行尾插入 o 在下方新建一行并插入 O 在上方新建一行并插入 光标移动(Normal模式) 命令 说明 h / j / k / l 左 / 下 / 上 / 右(推荐) w 移动到下一个单词开头 b 移动到上一个单词开头 e 移动到单词结尾 0 移动到行首 $ 移动到行尾 gg 移动到文件开头 G 移动到文件结尾
- n 跳到第n行 Ctrl+f 向下翻页 Ctrl+b 向上翻页 删除和修改 命令 说明 x 删除光标处的字符 dd 删除当前行 dw 删除一个单词 d$ 删除到行尾 D 删除到行尾(同d$) cc 删除当前行并进入插入模式 cw 修改一个单词 r 替换单个字符 R 进入替换模式 复制和粘贴 根据freeCodeCamp指南,Vim使用寄存器来管理复制粘贴。
命令 说明 yy 复制当前行 yw 复制一个单词 y$ 复制到行尾 p 在光标后粘贴 P 在光标前粘贴 v+移动+y 可视选择后复制 v+移动+d 可视选择后剪切 撤销和重做
撤销 u # 撤销上一次操作 2u # 撤销最近2次操作 # 重做 Ctrl+r # 重做被撤销的操作 # 查看撤销历史 :un
Vibecoding 零基础入门教程
用生活化比喻,让你真正理解编程概念
不再机械操作,而是知其然更知其所以然
为什么写这份教程? 如果你是编程零基础的小白,可能会遇到这样的困惑:
教程让我输入命令,但我不知道为什么要这样做 什么是前端?什么是后端?为什么要分开? 服务器、终端、命令行…这些到底是什么东西? 照着步骤做可以运行,但一旦出错就完全不知道怎么办 这份教程的目标是:让你真正理解每个概念的本质,而不只是机械地执行操作。
第一部分:核心概念理解 前端 vs 后端:餐厅的完美比喻 想象你去一家餐厅吃饭… 前端和后端的关系,就像餐厅的前台和厨房的关系。理解这个比喻,你就能理解整个Web应用的工作原理。
前端 = 餐厅前台 菜单:你看到的界面(HTML + CSS) 服务员:处理你的互动(JavaScript) 点餐:你点击按钮、填写表单 装饰和氛围:页面的美观设计 核心职责:创造良好的用户体验,让客户(用户)感到舒适和满意 后端 = 餐厅厨房 厨师:处理复杂逻辑(Python/Node.js) 食材库:存储数据(数据库) 烹饪过程:数据处理和计算 出菜:返回处理结果 核心职责:高效处理复杂任务,确保数据安全和逻辑正确 数据流动的完整过程 1 你(用户)看菜单决定要吃什么 → 浏览器加载网页(HTML/CSS显示界面) 2 你告诉服务员你的订单 → JavaScript收集你的输入(点击按钮、填写表单) 3 服务员把订单传到厨房 → JavaScript发送请求到服务器(后端) 4 厨房处理订单,准备食物 → 后端处理逻辑、查询数据库、计算结果 5 服务员把食物端给你 → 后端返回数据,JavaScript更新页面显示 为什么要这样设计? 专业分工:前台专注用户体验,厨房专注效率和质量,各司其职才能提供最好的服务。
安全性:你不能直接进厨房拿食材(数据安全),必须通过服务员(接口)。
可扩展性:可以换不同的菜单设计(前端),但厨房逻辑不变;也可以升级厨房设备(后端),前台体验不受影响。
参考来源:CSDN - 类比餐厅桌前就餐来解释前端和后端
服务器、终端、命令行:拨开迷雾 服务器就是一台远程电脑 不要被“服务器“这个词吓到!它本质上就是一台24小时开机、联网的电脑,专门用来提供服务。就像你家的电脑,只是它在机房里,一直开着。
你的电脑 • 有鼠标、键盘、屏幕 • 有图形界面(桌面) • 你能看到文件夹和图标 • 关机就停止工作 服务器 • 在机房里24小时运行 • 通常没有屏幕和鼠标 • 只能通过网络远程控制 • 需要一直开机服务用户 终端/命令行 • 用文字控制电脑 • 代替鼠标点击的方式 • 可以远程操作服务器 • 效率更高、功能更强 为什么要用命令行而不是图形界面? 对比维度 图形界面(GUI) 命令行(CLI) 学习曲线 ✅ 直观易懂,点击即可 ⚠️ 需要记命令,有学习成本 效率 ❌ 重复操作很慢(点来点去) ✅ 一个命令完成批量任务 自动化 ❌ 难以自动化 ✅ 可以写脚本自动执行 远程操作 ❌ 需要图形界面传输(慢) ✅ 只传输文字(超快) 服务器使用 ❌ 大多数服务器没有GUI ✅ 唯一选择 命令行的超能力举例 场景1:重命名100个文件
图形界面:
右键→重命名→输入新名字 重复100次… 😫
命令行:
for file in *.jpg; do mv “$file” “new_$file”; done 1秒完成!✨
场景2:查找所有包含“error“的日志文件
图形界面:
一个个文件打开查看 可能要找几小时… 😫
命令行:
grep -r “error” *.log 瞬间找到所有结果!✨
小白提示 刚开始用命令行可能会不习惯,但就像学骑自行车,过了最初的陌生期,你会发现它其实很简单,而且快得飞起!
记住:命令行不是用来吓唬你的,而是让你变得更强大的工具。
参考来源:MDN - 命令行速成课
包管理器:代码界的乐高仓库 编程就像搭乐高积木 想象你要搭建一座城堡。你可以自己用黏土捏每一块砖(从零写代码),也可以用现成的乐高积木组装(使用别人写好的代码包)。
包管理器就是乐高积木的仓库,帮你找到需要的积木,并确保它们能拼在一起。
npm(Node.js) 全称:Node Package Manager
用于JavaScript项目 管理前端和Node.js后端的代码包 全球最大的软件注册表 超过200万个可用包 pip(Python) 全称:Package Installer for Python
用于Python项目 从PyPI安装Python包 简化Python库的安装 超过40万个可用包 为什么需要包管理器? 🚫 没有包管理器的噩梦 • 需要手动去网站下载每个代码包 • 不知道这个包依赖哪些其他包 • 版本冲突(A需要包C的1.0版本,B需要包C的2.0版本) • 更新很麻烦,要手动检查每个包的新版本 • 团队协作时,每个人环境可能不一样 ✅ 有包管理器的便利 • 一个命令安装所有需要的东西 • 自动处理依赖关系(包A需要包B,会自动装上包B) • 版本管理清晰,避免冲突 • 一键更新所有包 • 团队协作时,用同一个配置文件,环境完全一致 包管理器工作原理(以npm为例) 1 你告诉npm你需要什么 npm install express 意思是:“我需要express这个包”
2 npm去仓库查找这个包 就像去乐高仓库找对应的积木盒子
3 npm检查这个包需要什么其他包 express可能需要10个其他小包,npm会把它们也一起装上
4 下载并安装到你的项目文件夹 所有包都放在 node_modules 文件夹里
5 记录安装信息 在 package.json 文件中记录你装了什么,下次别人可以直接用这个文件一键安装相同环境
常见疑问:为什么node_modules文件夹这么大? 你可能安装一个小包,却发现node_modules有几百MB。这是因为:
这个包依赖其他包,其他包又依赖更多包(依赖链) 为了确保兼容性,每个包都可能带着自己的依赖版本 这是正常的!包管理器正在帮你处理复杂的依赖关系 类比总结 没有包管理器:你要自己去玩具店买每个乐高零件,还要确保它们能拼在一起。
有包管理器:你只需要说“我要搭城堡“,包管理器自动帮你准备好所有需要的积木,并且确保它们都能完美组合。
参考来源:知乎 - 什么是NPM以及为什么NPM如此重要
权限系统:电脑里的“房间钥匙“ 想象你的电脑是一栋大楼 有些房间是公共区域(你的个人文件夹),任何人都能进。有些房间是机房(系统核心文件),只有管理员才能进。权限系统就是这栋大楼的钥匙管理系统。
普通用户 就像大楼里的普通员工
可以访问自己的文件夹 可以运行普通程序 不能修改系统文件 不能安装影响整个系统的软件 不能更改系统设置 管理员/Root用户 就像大楼的物业经理
拥有所有房间的钥匙 可以修改任何文件 可以安装任何软件 可以更改系统配置 权力大,责任也大! sudo:临时升级为管理员 sudo 是 “Super User DO”(超级用户执行)的缩写。
现实类比:你是普通员工,但需要进机房修电脑。你不能随时带着机房钥匙(不安全),所以你去找保安,说“我需要进机房“,保安核实你的身份后,暂时给你钥匙,办完事就还回去。
sudo 就是这个过程:你告诉系统“我需要临时的管理员权限“,系统确认你的密码后,给你临时权限执行这一条命令。
实际例子对比 ❌ 没有权限(会失败)
npm install -g some-package 错误:Permission denied(权限被拒绝)
因为全局安装(-g)需要写入系统文件夹,普通用户没权限
✅ 使用sudo(成功)
sudo npm install -g some-package 系统会要求输入密码,验证后执行成功
用管理员权限安装,可以写入系统文件夹
为什么要有权限系统? 防止误操作 想象你不小心运行了一个删除命令 rm -rf /(删除所有文件)。如果没有权限保护,整个系统就毁了!
防止病毒破坏 病毒程序作为普通用户运行,无法修改系统文件,破坏力大大降低。
多用户隔离 服务器上有多个用户,A用户不能看B用户的文件,保护隐私。
系统稳定性 关键系统文件受保护,普通软件无法随意修改,确保系统稳定运行。
重要警告:慎用sudo 网上有些教程说“如果命令不工作,加sudo试试“。这是危险的!
sudo给你完全的系统控制权,错误命令可能破坏系统 只在你确实理解这个命令在做什么时才用sudo 不要盲目复制粘贴带sudo的命令 如果一个命令需要sudo才能运行,先搞清楚为什么 什么时候应该用sudo? 安装全局软件(如 sudo npm install -g) 修改系统配置文件(如 sudo nano /etc/hosts) 管理系统服务(如 sudo systemctl restart nginx) 修改系统文件夹权限(如 sudo chmod) 但是:开发自己的项目时,通常不需要sudo! 参考来源:CSDN - Linux的文件、用户权限以及sudo原理
第二部分:Vibecoding实战入门 现在你已经理解了概念,让我们开始实战 重要思维转变:
从现在开始,每当你执行一个命令,不要只是照做。问自己:
这个命令在做什么? 为什么需要这个步骤? 执行后会发生什么? 如果出错,可能是哪里的问题? 步骤1:环境准备 1 安装Node.js(JavaScript运行环境) 这是什么?
Node.js让你的电脑能运行JavaScript代码(不只是在浏览器里)。它还自带npm包管理器。
为什么需要?
Vibecoding的前端和后端都需要Node.js环境来运行开发工具和执行代码。
怎么做?
- 访问 nodejs.org
- 下载LTS版本(Long Term Support,长期支持版,更稳定)
- 安装(像装其他软件一样,一路“下一步“即可)
- 验证安装:打开终端,输入 node -v 会发生什么:
如果看到版本号(如 v18.17.0),说明安装成功。Node.js已经在你的电脑上了,可以运行JavaScript了。
2 安装Python(如果做后端) 这是什么?
Python是一门编程语言,很多AI和数据处理应用用它来写后端。
为什么需要?
如果你的Vibecoding项目后端用Python(如Flask、Django),就需要Python环境。
怎么做?
- 访问 python.org
- 下载最新版本(建议Python 3.10+)
- 安装时勾选“Add Python to PATH“(重要!)
- 验证:终端输入 python –version 3 配置镜像源(中国用户强烈推荐) 这是什么?
npm和pip的服务器在国外,中国访问很慢。镜像源是国内的复制版,速度快得多。
为什么需要?
不配置的话,安装包可能超级慢,甚至失败。配置后,从分钟级变成秒级。
npm镜像配置(淘宝源):
npm config set registry https://registry.npmmirror.com pip镜像配置(清华源):
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 会发生什么:以后运行 npm install 或 pip install 时,会从国内服务器下载,速度飞快!
步骤2:创建你的第一个项目 场景:我们要创建一个简单的网页,有前端界面,有后端处理。
就像开一家小餐厅:前台展示菜单(前端),厨房准备食物(后端)。
步骤2.1:创建项目文件夹 mkdir my-first-app cd my-first-app 解释:
• mkdir = make directory(创建文件夹) • cd = change directory(进入这个文件夹) • 现在你在 my-first-app 文件夹里了,所有后续操作都在这里 步骤2.2:初始化npm项目 npm init -y 解释:
• npm init = 创建一个npm项目 • -y = yes to all(所有选项都选默认,不用一个个确认) • 会生成 package.json 文件,这是项目的“身份证“ 会发生什么:
文件夹里出现一个 package.json 文件,里面记录了项目名称、版本等信息。以后安装的包也会记录在这里。
步骤2.3:安装第一个包(Express) npm install express 解释:
• Express是一个超流行的Node.js后端框架 • 它让创建Web服务器变得超级简单 • npm会自动下载Express及其所有依赖 会发生什么:
- npm去镜像源下载Express
- 创建 node_modules 文件夹,把Express放进去
- 在 package.json 中记录“这个项目用了Express“
- 创建 package-lock.json,锁定所有包的确切版本 步骤2.4:创建一个简单的服务器 创建一个 server.js 文件,输入以下代码:
const express = require(‘express’); const app = express(); const port = 3000;
app.get(‘/’, (req, res) => { res.send(‘你好,这是我的第一个服务器!’); });
app.listen(port, () => {
console.log(服务器运行在 http://localhost:${port});
});
代码解释:
• 第1行:导入Express(就像从仓库拿出乐高积木) • 第2行:创建一个Express应用 • 第5-7行:定义一个路由(用户访问首页时,显示问候语) • 第9-11行:启动服务器,监听3000端口 步骤2.5:运行服务器 node server.js 解释:
• node = 用Node.js运行 • server.js = 运行这个文件 会发生什么:
- 终端显示:“服务器运行在 http://localhost:3000”
- 服务器开始监听3000端口,等待访问
- 打开浏览器,访问 http://localhost:3000
- 你会看到:“你好,这是我的第一个服务器!”
- 🎉 恭喜!你的第一个Web应用运行成功! 你刚才做了什么? 用餐厅比喻:
租了一个店面(创建项目文件夹) 办理了营业执照(npm init) 从供应商进货(npm install express) 设计了菜单和服务流程(写server.js代码) 开门营业(node server.js) 顾客来访问,你成功接待了他们! 你已经创建了一个真正的Web服务器,虽然简单,但它是真实工作的!
常见问题解答 Q: 命令运行后没反应,或报错“command not found“ A: 可能原因:
软件没安装成功 → 重新安装Node.js/Python 没有添加到PATH → 安装时勾选“Add to PATH“ 需要重启终端 → 关闭终端重新打开 Q: npm install 很慢或失败 A: 检查镜像源是否配置成功:
npm config get registry 应该显示淘宝镜像地址。如果不是,重新配置镜像源。
Q: 端口被占用(Port already in use) A: 说明3000端口已经被其他程序使用。解决方法:
改用其他端口(如3001、8080) 或者关闭占用3000端口的程序 Q: 权限错误(Permission denied) A: 不要急着用sudo!先检查:
是否在自己的用户文件夹里操作? 是否在用全局安装(-g)?如果是,可能需要sudo 项目文件夹权限是否正确? Q: 为什么按教程做还是不行? A: 不要慌!调试是编程的一部分:
读错误信息:虽然可能看不懂,但往往提示了问题所在 Google是你的朋友:复制错误信息搜索,通常能找到答案 检查拼写:少一个字符都不行(特别是引号、括号) 对比代码:逐行对比教程和你的代码,找出差异 下一步学什么? 前端方向 • 学习HTML/CSS基础 • 掌握JavaScript基本语法 • 尝试React或Vue框架 • 学习响应式设计 后端方向 • 深入学习Node.js或Python • 学习数据库(MySQL、MongoDB) • 理解RESTful API设计 • 学习身份验证和授权 记住:每个大神都是从小白开始的!
重要的不是记住每个命令,而是理解背后的原理。
🎉 恭喜你完成入门学习! 你已经从“不明所以“进化到“知其所以然“
现在你不仅会操作,更重要的是理解了为什么要这样操作
继续保持好奇心,不断提问“为什么“,你会走得更远!
这份教程是一个起点,不是终点 服务器部署终端知识高级培训教程:从架构原理到生产运维 本报告旨在为零基础的初学者(“0基础小白”)提供一套系统、深入的服务器部署终端知识培训。报告将超越简单操作步骤的罗列,聚焦于解释设计背后的原理(Why)和操作可能导致的后果(What Happened),从而构建一个扎实的技术基础,确保学员能够进行安全、可靠的应用部署。
Section I: Unpacking the Deployment Blueprint: Establishing Architecture (The Critical “Why”) 现代网络应用建立在分布式架构之上。理解构成这些应用的各个组件及其交互方式,是进行任何服务器配置或故障排除的前提。缺乏这种基础理解,部署工作将始终停留在盲目执行命令的层面。 1.1 The Client-Server Model: The Foundational Contract of the Web 网络通信的基石是客户端-服务器模型。在这种分布式架构中,责任和资源被明确划分 [1]。 1.1.1 定义角色和发起通信 客户端(Client)是任何发起通信的设备或软件,它通过请求数据或服务来启动通信会话 [1, 2]。常见的客户端应用包括用户的网页浏览器、智能手机应用等。客户端通常不共享其计算资源,而是请求服务器上的内容或服务 [2]。 服务器(Server)是一个功能强大的系统,它运行一个或多个服务器程序,等待并响应客户端的传入请求 [2]。服务器负责提供数据或执行特定任务,并且通常需要处理大量的并发请求 [1]。 1.1.2 理解状态与容量(“What Happens”) 服务器在短时间内可能收到来自许多不同客户端的请求。由于一台计算机在任何时刻只能执行有限的任务,服务器依赖调度系统来安排和处理这些传入的请求 [2]。为了防止系统被滥用并最大化可用性,服务器软件可能会限制对客户端的可用性,这解释了分布式拒绝服务(DDoS)攻击如何通过超载请求率来利用服务器处理请求的义务 [2]。 此外,这种分布式架构的优势在于其固有的集中性,这使得数据管理、备份和恢复变得更容易,并允许实施集中的安全策略和身份验证 [1]。客户端负责本地操作,例如数据渲染和分析;而服务器则专注于数据选择、处理和安全检查 [2]。 1.2 Architectural Layers: Distinguishing Frontend, Backend, and the Glue 在 Web 部署中,前端和后端的分离是实现可扩展性和专业化的核心原则。 1.2.1 前端编译与静态资源 现代前端框架(如 React、Vue)在部署前会通过命令(例如 npm run build)编译成一组静态资产 [3, 4]。这些静态文件(HTML、CSS、JavaScript)是纯粹的资源,不包含动态逻辑,因此它们被设计为可以被快速、高效地提供服务,对服务器计算能力的要求极低。 1.2.2 后端 API 与应用逻辑 后端负责处理核心业务逻辑、用户认证以及与持久存储(数据库)的交互 [3]。它生成动态内容,响应前端发出的 API 请求。一个运行在 Node.js/Express 或 Python/Flask 上的应用服务器,其主要职责是执行业务代码,而不是处理复杂的网络连接和静态文件服务。 1.3 The Reverse Proxy (Nginx): The Gatekeeper and Scalability Enabler 反向代理是连接前端和后端、并为整个应用提供生产级稳定性的关键中间层。 1.3.1 Nginx 作为反向代理的功能 Nginx 是一种开源 Web 服务器,其核心功能之一是充当反向代理 [5]。它位于客户端和应用服务器(即上游后端服务器)之间,拦截客户端请求并将其转发给适当的后端服务器,然后将响应传回客户端 [5]。 反向代理作为上游服务器的抽象层,提供了多项关键益处:
- 安全性(Security): 反向代理将后端应用服务器隐藏在私有网络中,保护其身份,使其不直接暴露给互联网 [5, 6]。
- 负载均衡(Load Balancing): Nginx 可以将客户端请求均匀地分配给多个上游服务器,从而提高性能,并在某个服务器发生故障时提供冗余 [5]。
- 功能卸载(Feature Offloading): 反向代理可以提供附加功能,例如高效地服务静态内容、缓存请求、压缩请求以及执行 SSL 终止(HTTPS 管理) [5, 6]。 1.3.2 设计模式:独立部署与路由 应用服务器(例如 Kestrel 或 Node.js)虽然在服务动态内容方面至关重要,但其 Web 服务能力往往不如 Nginx 或 Apache 等专业服务器功能丰富 [5]。因此,架构师会故意将应用逻辑和网络服务层分开。 这种安全通过抽象实现的设计模式,解释了为什么部署需要 Nginx:Nginx 专注于提供生产成熟度所需的功能(例如安全性和缓存),而应用服务器则专注于快速执行应用逻辑。如果绕过代理,服务器将面临脆弱、缓慢且不可靠的风险。 通过配置 Nginx,可以实现统一托管,即使前端和后端作为独立服务部署,也可以通过单一域名进行路由 [3]。例如,Nginx 可以根据 URL 路径(如 location / 转发到前端,location /api 转发到后端)来路由请求 [3]。这种方法支持更好的独立扩展能力和独立的部署周期 [3]。 Table 1: Architectural Component Roles Component Primary Role Typical Technology Key Benefit (The “Why”) Client Initiates requests, Renders output Web Browser (Chrome, Firefox) User Interaction and Local Processing Reverse Proxy Intercepts, Routes, Secures Nginx, Apache, Caddy Security (hides backend), Load Balancing, Caching [5, 6] Application Server Executes business logic, Handles API Node/Express, Python/Flask Dynamic Content Generation, Data Processing Database Persistence, Data Storage PostgreSQL, MongoDB, MySQL Centralized Data Management [1]
Section II: Dependency Ecosystem Management (npm, pip, and Optimization) 在服务器上部署应用涉及安装大量的第三方库和模块。包管理器(Package Managers)是处理这些依赖关系的关键工具,而镜像源配置则是确保部署过程快速和可靠的重要步骤。 2.1 The Philosophy of Package Management 包管理器的出现是为了解决开发者在安装软件及其依赖项时面临的耗时且繁琐的手动过程 [7]。 2.1.1 工具的必要性(“The Why”) 包管理器通过自动化安装过程来节省开发时间 [7]。它能确保代码的添加和删除是干净的,并且有助于解决版本冲突 [8]。在大型项目中,依赖项数量众多,手动跟踪版本更新和依赖关系管理会变得非常困难,使用包管理器则能保证代码的可追溯性和环境的再现性 [8]。 2.2 Node.js Management: npm 对于基于 JavaScript/Node.js 的项目,npm(Node Package Manager)是标准工具。项目通过 package.json 文件定义所需的依赖项和项目元数据,而 package-lock.json 则用于锁定确切的版本号,以确保部署环境的精确重现性。核心命令包括用于安装依赖的 npm install 和用于构建前端静态文件的 npm run build。 2.3 Python Management: pip and Environment Isolation pip 是 Python 默认的包安装工具,通常随 Python 一起安装,也是使用最广泛的 [9]。 2.3.1 Pip 和 requirements.txt pip 所需的依赖项列表通常保存在项目根目录下的 requirements.txt 文件中 [9]。该文件格式允许指定包名、精确版本约束(例如 docopt == 0.6.1)以及引用其他要求文件或 URL [10]。开发者可以使用 pip install -r requirements.txt 命令一次性安装所有所需依赖 [9]。此外,pip freeze > requirements.txt 可用于将当前环境中所有已安装的包导出到文件中 [9]。 2.3.2 环境隔离的概念 对于 Python 部署,理解虚拟环境(Virtual Environments)的概念至关重要。虚拟环境允许为每个项目创建独立的环境,从而防止全局依赖项之间的冲突,这是仅靠 pip 自身无法完全解决的故障模式。虽然 pip 是默认选择,但 pipenv 和 poetry 等较新的工具提供了更健壮的依赖解析和环境管理功能 [9]。 2.4 Advanced Optimization: Configuring Download Mirrors (The Reliability Factor) 在服务器部署中,配置下载源(或镜像)是提高稳定性和速度的关键步骤,尤其在面临网络连接限制的地理区域。 2.4.1 镜像的必要性(“The Why”) 在某些地区,由于网络策略(例如防火墙)可能显著减慢甚至阻止对外部服务器的访问,因此使用本地镜像(Mirrors)至关重要 [11]。镜像源是包仓库的复制品 [12]。通过连接到国内的镜像源(例如淘宝镜像或阿里云源),可以获得更快的更新速度和更可靠的连接,确保下载和更新软件包时的效率 [11, 13]。这解决了跨国网络连接导致的部署超时和失败问题,将基础设施知识适应了本地网络环境。 2.4.2 配置指南
- npm 配置: 通过命令行工具设置全局或特定作用域的注册表地址,指向国内镜像(如淘宝镜像) [13]。
- pip 配置: 通过修改配置文件或使用命令行选项,将默认的索引 URL 设置为国内镜像源(如阿里云源) [13]。 Table 2: Comparison of Core Package Managers and Configuration Manager Platform Dependency File Source Configuration Method Key Command for Setup npm Node.js/JS package.json Registry URL setting (e.g., npm config set registry) [13] npm install pip Python requirements.txt Index URL setting in config file or command line pip install -r requirements.txt [9, 10]
Section III: Command Line Fundamentals and Linux Server Survival 服务器部署的核心工作是在终端环境中完成的。掌握基础的 Linux 命令和终端文本编辑器(Vim)是服务器操作人员的必备技能。 3.1 Terminal Introduction and File System Navigation 服务器部署通常使用 Bash Shell (/bin/bash) 作为标准命令行环境 [14]。 3.1.1 基础导航命令 • pwd (Print Working Directory): 显示当前所在的目录位置。 • ls (List): 列出文件和目录。使用选项 -la 可以显示所有文件(包括隐藏文件)和详细信息 [14]。 • cd (Change Directory): 更改目录。理解 ~ 代表用户家目录,/etc 包含系统范围的配置文件,是进行系统配置和探索时常用的路径 [14]。 3.1.2 效率提升:掌握 Tab 补全 在终端中使用 Tab 键补全命令或文件名是提高工作效率的最佳功能之一 [14]。通过开始输入命令或路径,然后按下 Tab 键,系统会自动完成输入。如果存在多个可能的补全选项,连续按两次 Tab 键会显示所有选项 [14]。这不仅节省了输入时间,更重要的是防止了因路径或命令名称输入错误而导致的部署错误,直接关系到系统稳定性。 3.2 Essential File and Directory Management 在 Linux 系统中,文件管理是日常运维的基础: • 创建: mkdir 用于创建目录,例如 mkdir -p ~/practice/documents 可以递归地创建多层目录 [14]。 • 复制/移动: cp 和 mv 分别用于复制和移动文件。 • 删除: rm 用于删除文件,由于 Linux 中没有“回收站”或“撤销”功能,使用 rm 必须极端谨慎。 • 搜索: locate 和 find 命令用于在文件系统中查找文件,这对调试和资源管理至关重要 [14]。 3.3 Networking and Diagnostics Commands 了解基础网络命令有助于验证应用的可访问性和诊断连接问题: • ssh (Secure Shell): 用于安全地远程登录到服务器 [15]。 • ping: 用于检查主机之间的基本网络连通性 [15]。 • netstat: 用于显示网络连接、路由表和网络接口信息 [15]。在部署完成后,该命令对于检查应用程序是否正在监听预期的端口至关重要。 3.4 Text Editing Survival: Mastering Vim in the Terminal Vim 是远程服务器上进行配置编辑的标准编辑器,因为它不需要图形界面。所有服务器操作员都必须掌握 Vim 的生存命令。 3.4.1 Vim 模式介绍 Vim 具有三种主要模式:
- 普通模式(Normal Mode): 用于光标移动、删除、复制等命令输入 [16]。
- 插入模式(Insert Mode): 用于实际的文本输入 [16]。
- 命令行模式(Command Line Mode): 用于保存、退出或执行其他系统操作 [16]。 3.4.2 核心生存命令 在普通模式下,需要掌握以下基本操作: • 光标移动: h, j, k, l 分别向左、下、上、右移动光标 [17]。w 跳到下一个单词开头,b 跳到上一个单词开头 [17]。 • 剪切/删除: dd 删除并剪切(cut)一整行;dw 删除光标到词尾的字符 [17]。 • 复制/粘贴: yy 复制(yank)一整行;p 在光标后粘贴剪贴板内容 [17]。 3.4.3 关键的保存与退出命令 在命令行模式下(输入 : 激活): • 保存文件::w [16]。 • 退出 Vim::q [16]。 • 保存并退出::wq 或 :x,或直接使用 ZZ 命令 [16]。 • 强制退出不保存(放弃错误)::q! [16]。 终端操作的熟练程度与系统稳定性直接相关。一个能够在 10 秒内编辑并保存关键配置文件的运维人员,相比一个可能花费 5 分钟在移动和保存命令上挣扎的人,可以显著减少服务停机时间。
Section IV: Deep Dive into Terminal Permissions (The Security and Consequence Layer) 权限管理是服务器部署中一个至关重要的安全环节,它决定了哪个用户可以访问哪些文件以及他们可以执行什么操作。不正确的权限设置(例如,使用过于宽松的权限)是导致安全漏洞和操作错误的常见原因。 4.1 Understanding Linux Multi-User Access Control Linux 是一个多用户、多任务的操作系统。对文件的访问控制基于三个层次:文件所有者(User)、文件所有者所在的组(Group)以及其他用户(Others) [18]。 访问权限包括三种核心权利 [18]: • 读取(r=4): 允许查看文件内容或列出目录内容。 • 写入(w=2): 允许修改、添加或删除文件内容(或在目录中创建/删除文件)。 • 执行(x=1): 允许运行可执行文件或进入目录。 4.2 Changing Ownership: The Power of chown (The “Who” Can Access) chown(change owner)命令用于修改文件或目录的所有者和关联的组 [18]。执行此命令通常需要超级用户 root 的权限 [18]。 4.2.1 部署的必要性(“The Why”) 在部署应用时,最常见的错误之一是权限不足。例如,如果代码由 root 用户部署,文件的所有权将归 root 所有。然而,出于安全考虑,Web 应用程序通常会以低权限用户(例如 www-data 或 nginx)身份运行 [18]。如果应用程序尝试写入日志文件或处理用户上传,但文件仍归 root 所有,就会发生“Permission Denied”的故障 [18]。 解决方案是使用 chown -R www-data:www-data /path/to/app,递归地将应用目录的所有权授予运行该应用的低权限用户和组 [18]。这确保了应用程序在运行时拥有对自身文件执行必要操作的权限。 4.2.2 语法 chown 的基本语法是 chown [选项] 所有者[:组] 文件… [18]。选项 -R(recursive,递归)用于将更改应用于目录及其所有子文件 [18]。 4.3 Changing Permissions: Decoding chmod (The “How” They Can Access) chmod(change mode)命令用于控制不同用户对文件访问的方式 [18]。 4.3.1 八进制表示法与安全原则 权限最常见且最精确的表示方式是八进制数字,它由三个数字组成,分别对应所有者、组、和其他人的权限总和 [18]。 例如,权限 755 意味着: • 所有者:4+2+1=7(rwx,读/写/执行) • 组:4+1=5(r-x,读/执行) • 其他人:4+1=5(r-x,读/执行) [18] 最小权限原则是安全性的核心指导法律。 这一原则要求只授予进程或用户完成任务所需的精确权限,并积极拒绝任何危险的、非必需的权限(例如写入或删除)。 4.3.2 权限误配置的后果(“What Happens”) • 危险配置(777): 意味着所有用户都拥有完全的读、写和执行权限 [18]。这是极其不推荐的做法,因为它使系统面临最大的安全风险。如果应用程序的任何部分被攻破,攻击者将获得修改或注入恶意代码的完全控制权 [18]。 • 标准目录权限(755): 所有者拥有完全权限,组和其他用户只有读和进入目录的权限 [18]。 • 限制性配置(500): 权限 500(r-x)意味着所有者只有读取和执行权限,但没有写入权限 [18]。这种配置对于应确保代码完整性、不允许被运行进程修改的应用目录至关重要。例如,通过设置 chmod -R 500 file_a/,可以阻止 user_A 删除或写入共享文件夹,即使他们是所有者 [18]。 在实际应用中,chown 和 chmod 必须按顺序执行,才能确保操作完整性。只有先使用 chown 将正确的用户设置为所有者,才能通过 chmod 700 等命令有效地限制其他用户的访问。 Table 3: Numerical Permission Cheat Sheet and Security Context Octal Symbolic Owner:Group:Other Security Use Case Consequence if Used Incorrectly 777 -rwxrwxrwx R/W/X: R/W/X: R/W/X NEVER USE (Debug only) 最大安全暴露 [18] 755 -rwxr-xr-x R/W/X: R/X: R/X 标准可执行目录 (e.g., web root) [18] 无法被组/其他人修改。 644 -rw-r–r– R/W: R: R 标准静态配置文件 保护文件内容免受未经授权的修改。 500 -r-x—— R/X: —: — 严格限制;禁止写入/删除 [18] 确保代码完整性;进程无法修改二进制文件。
Section V: Production Deployment and Continuous Operation 将应用程序从开发阶段推进到生产环境,意味着它必须能够自主运行、应对故障,并在服务器重启后保持在线。 5.1 The Problem with Simple Execution in Production 简单地通过终端命令(例如 node app.js)运行应用程序对于开发是可接受的。然而,这种方法对于生产环境而言是不可持续的 [19]。 不可靠因素(“What Happens”): 如果应用程序由于某种异常而崩溃,它将无法自行重启 [19]。如果服务器重启,应用程序将保持离线状态,直到有人手动启动它 [19]。这造成了显著的可靠性问题,任何生产系统都无法容忍。为了解决这一问题,必须使用进程管理器。 5.2 Ensuring Uptime: Introduction to PM2 (Process Manager) PM2 是一种专为 Node.js 应用程序设计的生产级开源进程管理器 [19, 20]。它充当系统的守护者,确保应用程序持续运行、管理日志、监控资源并最大限度地减少停机时间 [20]。 5.2.1 核心可靠性功能 PM2 提供以下功能,实现生产环境的稳定运行:
- 自动崩溃恢复(Automatic Crash Recovery): PM2 持续监控应用程序,一旦检测到崩溃,它会立即重启进程,从而无限期地保持应用程序运行 [19]。
- 集群模式(Scaling): PM2 的集群模式(例如 pm2 start app.js -i max)可以跨所有可用 CPU 核心运行多个实例,并在它们之间进行流量负载均衡,从而显著提高吞吐量和资源利用率 [19]。
- 零停机部署(Zero-Downtime Deployment): 在更新代码时,使用 pm2 reload 而非 pm2 restart。在集群模式下,PM2 会一次只重启一个工作进程,确保在部署过程中始终至少有一个实例可用,从而避免服务中断 [19]。 5.3 Deployment Workflow Integration: PM2 and System Startup 为了实现真正的生产可靠性,必须将 PM2 管理的应用程序整合到 Linux 操作系统的生命周期管理中。 系统服务集成是部署的硬性要求。 缺乏这一关键步骤,应用程序就不能被视为真正的系统服务。为了确保应用程序在服务器重启后能够自动重新启动,必须执行以下两个独立且同等重要的命令:
- pm2 startup: 生成并注册一个 systemd 服务,使 PM2 进程本身能在系统启动时运行 [19]。
- pm2 save: 保存当前 PM2 正在管理的所有应用程序列表 [19]。 如果缺少其中任何一个步骤,应用程序将无法在服务器重启后自动上线 [19]。pm2 startup 负责 OS 持久性,而 pm2 save 负责状态保持。 5.4 Troubleshooting and Monitoring PM2 也简化了运维和调试工作: • 监控状态: pm2 status 或 pm2 list 用于快速查看所有应用程序的运行状态。 • 日志审查: pm2 logs [app_name] 用于实时查看和调试日志。 • 集中配置: 使用 ecosystem.config.js 文件,可以清晰地管理多个应用程序、环境变量、集群设置和部署环境,取代复杂的命令行参数 [19]。 进程管理器的使用引入了资源隔离的概念。通过集群模式,流量被分配到多个轻量级进程中,避免了单个进程故障导致整个服务中断,显著提高了响应时间和整体系统弹性。 Table 4: PM2 Survival Commands and System Interaction Command Description The “What Happens” System Interaction pm2 start app.js 启动应用程序 守护程序化应用,并管理内部进程恢复。 内部 PM2 守护进程 pm2 reload app_name 无中断地更新代码 循环优雅地重启工作进程,避免客户停机。 内部 PM2 守护进程 [19] pm2 startup 生成 OS 启动脚本 将 PM2 注册为系统服务 (e.g., systemd)。 Linux OS 服务管理器 [19] pm2 save 保存当前进程列表 指示 PM2 在系统重启后应重新启动哪些应用。 PM2 配置文件 [19] Conclusions and Recommendations 本教程已经全面覆盖了零基础用户从理解分布式架构到终端生存,再到生产级可靠部署所需的全部关键知识点。 关键结论与行动建议:
- 架构优先于操作: 始终理解客户端-服务器模型以及 Nginx 反向代理在安全和扩展中的作用。认识到 Nginx 提供了生产成熟度,而应用服务器专注于逻辑速度,这种分离是刻意为之的设计决策 [5, 6]。
- 环境配置是区域性挑战: 部署的可靠性不仅取决于代码,也取决于网络环境。在受网络限制的地区,配置国内镜像源(如 npm 和 pip 镜像)是确保部署流程顺畅且高效的必要步骤 [11]。
- 权限是安全基石: 权限管理是防止安全漏洞的第一道防线。严格遵循最小权限原则,先使用 chown 确定文件归属,再用 chmod 赋予精确的权限,并避免使用宽松的 777 权限 [18]。
- 持久化是生产的定义: 生产环境的应用必须能够自行从崩溃中恢复并在服务器重启后自动上线。这要求使用 PM2 等进程管理器,并确保同时运行 pm2 startup 和 pm2 save,将应用集成到操作系统的服务生命周期中 [19]。 通过掌握上述理论和实践知识,特别是理解每个终端操作背后的安全和可靠性含义,初学者将能够安全、高效地进行服务器部署。
-
Client-Server Model - GeeksforGeeks, https://www.geeksforgeeks.org/system-design/client-server-model/
-
Client–server model - Wikipedia, https://en.wikipedia.org/wiki/Client%E2%80%93server_model
-
How to Securely Host Frontend and Backend Together - DEV Community, https://dev.to/arunangshu_das/how-to-securely-host-frontend-and-backend-together-3236
-
How to deploy frontend and backend on Render?, https://community.render.com/t/how-to-deploy-frontend-and-backend-on-render/7449
-
Understanding Nginx As A Reverse Proxy | by Amit Kumar Shinde | Globant - Medium, https://medium.com/globant/understanding-nginx-as-a-reverse-proxy-564f76e856b2
-
How To Configure Nginx as a Reverse Proxy on Ubuntu - DigitalOcean, https://www.digitalocean.com/community/tutorials/how-to-configure-nginx-as-a-reverse-proxy-on-ubuntu-22-04
-
Need of Package Managers in Developer’s Life - GeeksforGeeks, https://www.geeksforgeeks.org/blogs/need-of-package-managers-in-developers-life/
-
Package management basics - Learn web development | MDN, https://developer.mozilla.org/en-US/docs/Learn_web_development/Extensions/Client-side_tools/Package_management
-
Is there anything like package.json from Node for python? : r/learnpython - Reddit, https://www.reddit.com/r/learnpython/comments/142kywg/is_there_anything_like_packagejson_from_node_for/
-
Requirements File Format - pip documentation v25.3, https://pip.pypa.io/en/stable/reference/requirements-file-format/
-
dautovri/mirrors-china: Mirrors and registries in Mainland China - GitHub, https://github.com/dautovri/mirrors-china
-
Package mirrors - Akamai TechDocs, https://techdocs.akamai.com/cloud-computing/docs/package-mirrors
-
NPM镜像站- 阿里云, https://www.aliyun.com/sswd/11863509-2.html
-
File System Navigation: First Steps in the Terminal - Part 1 of 5 of the Terminal Techniques for You (TTY): Making Linux Security Accessible Blog Series, https://www.sans.org/blog/file-system-navigation-first-steps-in-the-terminal-part-1-of-5
-
Linux 常用命令, https://math.ecnu.edu.cn/~jypan/Teaching/Linux/command/index.htm
-
Untitled, https://help.aliyun.com/zh/ecs/user-guide/use-the-vim-editor
-
Vim Cheat Sheet, https://vim.rtorr.com/
-
在linux系统上部署FTP服务时进行权限管理(利用chown,chmod命令 …, https://blog.csdn.net/LoseInVain/article/details/84638932
-
Use PM2 to Setup a Node.js Environment On An Ubuntu VPS | DigitalOcean, https://www.digitalocean.com/community/tutorials/how-to-use-pm2-to-setup-a-node-js-production-environment-on-an-ubuntu-vps
-
Running Node.js Apps with PM2 (Complete Guide) - Better Stack, https://betterstack.com/community/guides/scaling-nodejs/pm2-guide/ 0级别(必须掌握,否则无法部署成功)
-
云厂商安全组/防火墙 ⚠️ 这是初学者部署失败的Top 1原因 - 问题:在Linux里开了端口,但云控制台没开,外网仍 无法访问 - 类比:Linux防火墙是你家房门的锁,云安全组是小区 的门禁。房门开了但门禁没开,访客还是进不来 - 关键点:入站规则配置、端口80/443/22放行
-
域名与DNS解析(你已想到✅) - 类比:域名是通讯录里的名字,IP是电话号码,DNS就 是通讯录 - 关键点:域名购买、A记录(指向IP)、CNAME(别名 )、TTL概念
-
Nginx实战配置(不只是概念) - 现有问题:运维.md讲了Nginx的原理,但缺少“怎么配“ - 关键场景:
- 静态资源托管(前端)
- API转发配置(后端)
- 解决SPA刷新404问题 - 类比:Nginx是前台接待员,客人要看画(前端)带去 画廊,客人要办事(后端API)带去办公室
P1级别(强烈建议,现代Web标配)
- HTTPS与SSL证书 - 必要性:现代浏览器对HTTP显示“不安全“,小程序/PW A必须HTTPS - 类比:HTTP是明信片(谁都能看),HTTPS是密封信封 - 关键点:Let’s Encrypt免费证书、Certbot自动化工具
- CORS跨域问题 - 场景:前端在www.site.com,后端在api.site.com, 浏览器默认拦截 - 这是前后端分离项目最常见的红字报错 - 关键点:浏览器同源策略、后端或Nginx配置跨域
Vercel 配置完全指南 (小白专用)
什么是 Vercel?
Vercel 是一个超级强大的前端部署平台,让你不用搭建服务器就能把网站发布到全世界!
核心优势:
- 免费额度超大 (个人项目完全够用)
- 从 GitHub 一键部署 (不到 1 分钟)
- 全球 CDN 加速 (网站访问超快)
- 自动 HTTPS (网站更安全)
- 支持自定义域名
第一步: 注册 Vercel 账号
1.1 访问 Vercel 官网
打开浏览器,访问: https://vercel.com
1.2 使用 GitHub 账号登录 (强烈推荐)
点击 "Sign Up" 按钮
↓
选择 "Continue with GitHub"
↓
授权 Vercel 访问你的 GitHub
↓
注册成功!
小白提示: 为什么用 GitHub 登录? 因为后面部署项目时,可以直接选择 GitHub 上的代码仓库,超级方便!
第二步: 部署你的第一个项目
方法一: GitHub 仓库一键部署 (推荐)
具体操作步骤:
- 登录 Vercel 后,你会看到控制台首页
- 点击右上角 “Add New…” 按钮 → 选择 “Project”
- 导入 GitHub 仓库:
- 如果是第一次使用,需要点击 “Import Git Repository”
- 选择 “GitHub”
- 可能需要安装 Vercel GitHub App (点击 Install 授权)
- 选择要部署的仓库:
- 在列表中找到你的项目
- 点击 “Import” 按钮
- 配置项目设置 (通常 Vercel 会自动检测):
- Framework Preset: 自动识别 (Next.js / React / Vue 等)
- Root Directory: 项目根目录 (默认
.) - Build Command: 构建命令 (通常自动填好)
- Output Directory: 输出目录 (通常自动填好)
- 点击 “Deploy” 按钮
等待 1-2 分钟,部署完成!
方法二: 使用 Vercel CLI (命令行)
# 第一步: 安装 Vercel CLI
npm install -g vercel
# 第二步: 在项目目录运行
cd your-project
vercel
# 第三步: 跟随命令行提示
# - 登录账号
# - 选择项目配置
# - 确认部署
第三步: 配置环境变量 (核心!)
3.1 什么是环境变量?
环境变量就是存放敏感信息的地方,比如:
- API 密钥 (OpenAI API Key)
- 数据库地址 (Supabase URL)
- 第三方服务 Token
为什么要用环境变量?
- 保护隐私: 不会把密钥暴露在代码里
- 安全: 即使代码公开,别人也拿不到你的密钥
- 灵活: 不同环境 (开发/生产) 可以用不同的配置
3.2 重要! 理解 Key 的来源 (小白必读)
Vercel 是部署平台,不是 API Key 提供商!
❌ 错误理解: 所有 Key 都在 Vercel 获取
✅ 正确理解:
- 大部分 Key 在其他服务获取 (Supabase、OpenAI 等)
- 然后把这些 Key 添加到 Vercel 作为环境变量
- Vercel 只提供 Vercel Token (用于 Vercel API 访问)
常见 Key 的获取位置:
| Key 名称 | 获取位置 | 用途 | 添加到 Vercel? |
|---|---|---|---|
NEXT_PUBLIC_SUPABASE_URL | Supabase Dashboard → Settings → API | 数据库连接 | ✅ 是 |
NEXT_PUBLIC_SUPABASE_ANON_KEY | Supabase Dashboard → Settings → API | 公开访问 | ✅ 是 |
SUPABASE_SERVICE_KEY | Supabase Dashboard → Settings → API | 服务端访问 | ✅ 是 |
DATABASE_URL | Supabase Dashboard → Settings → Database | PostgreSQL 连接 | ✅ 是 |
OPENAI_API_KEY | OpenAI Platform → API Keys | AI 功能 | ✅ 是 |
VERCEL_TOKEN | Vercel Dashboard → Settings → Tokens | Vercel API 访问 | ❌ 否* |
小白提示:
- ✅ 部署到 Vercel 时,需要把 Supabase/OpenAI 等服务的 Key 添加到 Vercel 环境变量
- ❌ Vercel Token 是用于其他工具访问 Vercel,不需要添加到项目环境变量
3.3 如何在 Vercel 添加环境变量?
方法一: 在网页控制台添加
详细操作步骤:
第1步: 打开 Vercel Dashboard
↓
第2步: 选择你的项目
↓
第3步: 点击顶部导航栏的 "Settings" 标签
↓
第4步: 在左侧菜单找到并点击 "Environment Variables"
↓
第5步: 添加变量
具体填写方法:
-
Name (变量名): 输入变量名称
- 例如:
OPENAI_API_KEY - 注意: 如果需要在前端使用,必须以
NEXT_PUBLIC_开头
- 例如:
-
Value (值): 输入实际的密钥或配置
- 例如:
sk-xxxxxxxxxxxxx - 重要: 粘贴时小心不要有多余空格!
- 例如:
-
Environment (环境): 选择环境 (可多选)
- Production: 生产环境 (正式网站)
- Preview: 预览环境 (PR 预览)
- Development: 开发环境 (本地开发)
-
点击 “Save” 按钮保存
添加完成后,必须重新部署才会生效!
方法二: 使用命令行添加
# 添加生产环境变量
vercel env add OPENAI_API_KEY production
# 系统会提示你输入值,粘贴后按 Enter
# 查看所有环境变量
vercel env ls
3.3 环境变量使用示例
例子 1: OpenAI API Key
# 变量名
OPENAI_API_KEY
# 值 (示例,请替换为你自己的)
sk-proj-abc123def456...
例子 2: Supabase 配置
# Supabase 项目 URL
NEXT_PUBLIC_SUPABASE_URL=https://xxxxx.supabase.co
# Supabase 匿名密钥
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGciOiJIUzI1NiIs...
为什么加 NEXT_PUBLIC_?
- 加前缀的变量可以在浏览器端使用
- 不加前缀的变量只能在服务器端使用
- 永远不要把私密的 API Key 加 NEXT_PUBLIC_ 前缀!
第四步: 获取 Vercel API Token (高级功能)
4.1 什么是 Vercel API Token?
Vercel Token 是一个访问凭证,让其他工具 (比如 CI/CD、Trae MCP) 能够:
- 自动部署项目
- 管理环境变量
- 读取项目信息
4.2 如何获取 Vercel Token?
超详细步骤 (每一步都有说明):
第1步: 登录 Vercel Dashboard (https://vercel.com)
↓
第2步: 点击右上角头像 → 选择 "Settings"
↓
第3步: 在左侧菜单找到 "Tokens"
↓
第4步: 点击 "Create Token" 按钮
↓
第5步: 填写 Token 信息
填写 Token 信息:
-
Token Name: 给 Token 起个名字
- 例如: “Trae MCP Token” 或 “GitHub Actions”
- 建议: 用途清晰的名字,方便以后管理
-
Scope: 选择权限范围
- Full Account: 完整账号权限 (谨慎选择)
- Specific Projects: 指定项目 (推荐)
-
Expiration: 过期时间
- 建议选择一个合理的过期时间,不要选 “No Expiration”
-
点击 “Create” 按钮
重要! 立即复制 Token!
创建成功后,页面会显示 Token 字符串:
vercel_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
⚠️ 这个 Token 只会显示一次!
立即复制并保存到安全的地方!
保存到哪里?
- 密码管理器 (1Password, LastPass 等)
- 或者记事本 (但要确保安全)
- 绝对不要提交到 GitHub!
4.3 Token 类型对比
| Token 类型 | 权限范围 | 适用场景 | 安全性 |
|---|---|---|---|
| Personal Access Token | 所有项目 | 个人使用 | 中 |
| Project Token | 单个项目 | 推荐使用 | 高 |
| Team Token | 团队级别 | 团队协作 | 中 |
小白建议: 使用 Project Token,只给需要的项目授权,更安全!
4.4 如何使用 Token?
场景 1: 在 Trae MCP 中使用
在 Trae 的 MCP 配置中:
{
"mcpServers": {
"vercel": {
"env": {
"VERCEL_TOKEN": "你复制的 Token"
}
}
}
}
场景 2: 在 GitHub Actions 中使用
在 GitHub Secrets 中添加:
- Name:
VERCEL_TOKEN - Value: 你复制的 Token
第五步: 自定义域名配置 (可选)
5.1 为什么要自定义域名?
Vercel 默认域名:
- 格式:
your-project.vercel.app - 优点: 免费,自动配置
- 缺点: 不够专业,难记
自定义域名:
- 格式:
www.your-domain.com - 优点: 专业,好记,有品牌感
- 缺点: 需要购买域名 (一年几十块)
5.2 添加自定义域名步骤
第1步: 购买域名 (推荐: 阿里云, 腾讯云, Cloudflare)
↓
第2步: 在 Vercel 项目中点击 "Settings" → "Domains"
↓
第3步: 输入你的域名 (如 example.com)
↓
第4步: Vercel 会给你 DNS 配置说明
↓
第5步: 到域名提供商配置 DNS
5.3 DNS 配置方法
在你的域名提供商 (阿里云/腾讯云/Cloudflare) 添加 DNS 记录:
记录类型: CNAME
主机记录: @ (或 www)
记录值: cname.vercel-dns.com
TTL: 600 (10分钟) 或保持默认
等待 5-30 分钟,DNS 生效后你的自定义域名就可以访问了!
第六步: 常见问题解决
Q1: 部署失败了怎么办?
排查步骤:
1. 查看构建日志
在 Vercel Dashboard → 选择失败的部署 → "View Details"
2. 检查常见问题:
- ❌ 缺少环境变量 → 添加后重新部署
- ❌ Node.js 版本不对 → 在 package.json 添加:
"engines": {
"node": "18.x"
}
- ❌ 构建命令错误 → Settings → Build & Output Settings 检查
- ❌ 依赖安装失败 → 检查 package.json
3. 重新部署
修复问题后,点击 "Redeploy" 按钮
Q2: 环境变量不生效?
解决方案:
-
检查变量名是否正确
- 区分大小写!
OPENAI_API_KEY≠openai_api_key - 前端使用必须加
NEXT_PUBLIC_前缀
- 区分大小写!
-
重新部署
- 重要: 修改环境变量后,必须重新部署!
- 方法: Deployments → 最新部署 → “Redeploy”
-
检查环境选择
- Production / Preview / Development 都选了吗?
-
清除缓存
- 有时需要: Deployments → Redeploy → 勾选 “Use existing Build Cache” 取消
Q3: Vercel 免费版够用吗?
免费版额度:
| 项目 | 免费额度 | 够用吗? |
|---|---|---|
| 带宽 | 100 GB/月 | ✅ 个人项目绝对够 |
| 构建时间 | 100 小时/月 | ✅ 完全够用 |
| Serverless 函数 | 100次/小时 | ⚠️ 流量大时可能不够 |
| 团队成员 | 1 人 | ✅ 个人开发足够 |
小白建议: 个人学习和小项目,免费版完全够用!
Q4: 国内访问 Vercel 慢怎么办?
解决方案 (按推荐程度排序):
-
使用 Cloudflare CDN
- 绑定自己的域名
- 将域名托管到 Cloudflare
- 开启 Cloudflare CDN 加速
-
使用 Vercel 的 Edge Network
- Vercel 在全球有边缘节点
- 绑定域名后会自动优化
-
考虑替代方案
- Netlify: 类似 Vercel
- Cloudflare Pages: 国内速度更快
- EdgeOne Pages: 腾讯云服务,国内速度快
实战案例: 5 分钟部署 AI 聊天应用
准备工作
# 1. 确保你有:
- GitHub 账号
- Vercel 账号 (用 GitHub 登录)
- OpenAI API Key
操作步骤
第1步: Fork 示例项目
访问: https://github.com/vercel/ai-chatbot
点击右上角 "Fork" 按钮
↓
第2步: 在 Vercel 导入项目
Vercel Dashboard → Add New → Project
选择刚才 Fork 的仓库 → Import
↓
第3步: 配置环境变量
Settings → Environment Variables
添加: OPENAI_API_KEY = sk-xxxxx
↓
第4步: 部署!
点击 "Deploy" 按钮
等待 1-2 分钟
↓
完成! 你有了自己的 AI 聊天应用!
高级配置
vercel.json 配置文件
在项目根目录创建 vercel.json:
{
"version": 2,
"builds": [
{
"src": "package.json",
"use": "@vercel/node"
}
],
"routes": [
{
"src": "/api/(.*)",
"dest": "/api/$1"
}
]
}
构建配置优化
在 Settings → Build & Output Settings:
# 构建命令
Build Command: npm run build
# 输出目录 (根据框架不同)
Output Directory:
- Next.js: .next
- React/Vue: dist
- Nuxt: .output
# 安装命令
Install Command: npm install
安全最佳实践
1. 保护你的 API Key
# ❌ 错误做法: 直接写在代码里
const apiKey = "sk-abc123..." # 危险!
# ✅ 正确做法: 使用环境变量
const apiKey = process.env.OPENAI_API_KEY
# ❌ 错误: 提交 .env 文件到 Git
git add .env # 千万别这样!
# ✅ 正确: .env 文件加入 .gitignore
echo ".env" >> .gitignore
echo ".env.local" >> .gitignore
2. 定期更换 Token
- 每 3-6 个月更换一次 Vercel Token
- 不再使用的 Token 及时删除
- 怀疑泄露时立即撤销并重新创建
3. 使用最小权限原则
- 优先使用 Project Token,而不是 Account Token
- 只给必要的项目授权
- 设置合理的过期时间
参考资源
小结
Vercel 部署就是这么简单:
- 注册账号 - 用 GitHub 登录
- 导入项目 - 选择 GitHub 仓库
- 配置环境变量 - 添加 API Key
- 一键部署 - 等待 1 分钟
- 获取链接 - 分享给全世界!
现在就开始你的第一个部署吧! 🚀
💡 Vibe Coding 心法: 部署不可怕! Vercel 已经把复杂的服务器配置、DNS 解析、HTTPS 证书都搞定了。你只需要专注写代码,其他的交给 Vercel!
🌐 域名配置完全指南 (小白专用)
写在前面: 这份教程涵盖 Vercel 和 Cloudflare Pages 两种主流部署平台的域名配置,帮助你把本地项目部署到全球可访问的网站。两个平台都提供完全免费的 CDN、SSL 证书,非常适合个人项目。
📌 重要! 理解域名配置的核心概念 (小白必读)
域名配置的本质是什么?
你购买的域名 (example.com)
↓
需要"指向"你的项目部署地址
↓
Vercel/Cloudflare Pages 会给你一个默认地址
↓
通过 DNS 配置,让你的域名指向这个地址
域名在哪里获取?
| 域名来源 | 说明 | 是域名提供商吗? |
|---|---|---|
| 域名注册商 (阿里云、Namesilo、GoDaddy) | 购买域名的地方 | ✅ 是 |
| Vercel | 前端部署平台 | ❌ 不是 (只提供免费子域名) |
| Cloudflare Pages | 前端部署平台 | ❌ 不是 (只提供免费子域名) |
小白必读:
- ❌ 错误: 在 Vercel/Cloudflare 获取域名
- ✅ 正确: 在域名注册商购买域名,然后在 Vercel/Cloudflare 配置 DNS
- Vercel 和 Cloudflare 只是部署平台,域名需要自己购买!
📖 一、核心概念(30 秒看懂)
1.1 我们要做什么?
想象一下,你在自己电脑上做了一个很酷的网站:
你的电脑(本地开发)
↓
推送到 GitHub(代码托管)
↓
部署到 Vercel/Cloudflare Pages(全球可访问)
↓
绑定自定义域名(专业网址)
部署后你将获得:
- ✅ 一个免费的默认域名 (即刻可用)
- Vercel:
你的项目名.vercel.app - Cloudflare Pages:
你的项目名.pages.dev
- Vercel:
- ✅ 全球 CDN 加速 (网站访问超快)
- ✅ 自动 HTTPS 证书 (浏览器小绿锁 🔒)
- ✅ 可选: 绑定你自己的域名 (如
example.com)
1.2 三个关键术语
| 术语 | 生活类比 | 实际含义 |
|---|---|---|
| 域名 | 门牌号 | baidu.com 这种容易记的网址 |
| DNS | 通讯录 | 把“百度“翻译成具体的服务器地址 |
| CDN | 快递柜 | 在离用户最近的地方存一份网站,加速访问 |
🚀 二、购买域名(前置条件)
2.1 推荐域名注册商
如果你想用自己的域名(如 example.com)替代默认域名,需要先购买域名:
| 注册商 | 优点 | 价格参考 | 适合人群 |
|---|---|---|---|
| Namesilo | 便宜,赠送隐私保护 | .com 约 $8.99/年 | 预算有限 |
| Namecheap | 性价比高,界面友好 | .com 约 $10.98/年 | 新手友好 |
| 阿里云 | 中文界面,支付宝付款 | .com 约 ¥55/年 | 国内用户 |
| GoDaddy | 全球最大,域名种类多 | .com 约 $12.99/年 | 需要特殊后缀 |
购买流程(以 Namesilo 为例):
- 访问 Namesilo
- 搜索你想要的域名(如
my-app.com) - 加入购物车 → 结账 → 支付
- 完成! 域名会显示在你的账户中
🎯 三、方案 A: Vercel + 域名配置
3.1 Vercel 部署(获取默认域名)
前提条件: 代码已推送到 GitHub
步骤 1: 注册 Vercel
- 访问 Vercel
- 点击 “Sign Up” → 选择 “Continue with GitHub”
- 授权 Vercel 访问你的 GitHub
- 注册成功!
步骤 2: 导入 GitHub 项目
- 登录 Vercel Dashboard
- 点击右上角 “Add New…” → 选择 “Project”
- 选择 “Import Git Repository” → 选择 “GitHub”
- 找到你的项目 → 点击 “Import”
步骤 3: 配置项目设置
| 字段 | 说明 | 示例 |
|---|---|---|
| Project Name | 项目名称(将用于免费域名) | my-awesome-app |
| Framework Preset | 框架预设(自动识别) | Next.js / React / Vue |
| Build Command | 构建命令 | npm run build |
| Output Directory | 输出目录 | dist 或 .next |
环境变量配置(可选):
- 如果项目需要 API Key,点击 “Environment Variables”
- 添加变量名和值(如
NEXT_PUBLIC_API_URL)
步骤 4: 部署
- 检查所有配置无误
- 点击 “Deploy”
- 等待 1-3 分钟构建完成
- 获得免费域名:
https://my-awesome-app.vercel.app
恭喜! 你的网站已经在全球可访问了 🎉
3.2 绑定自定义域名到 Vercel
如果你已经购买了域名,可以绑定到 Vercel 项目:
步骤 1: 在 Vercel 添加域名
Vercel Dashboard → 选择你的项目 → Settings → Domains
↓
点击 "Add" 按钮
↓
输入你的域名(如 example.com 或 www.example.com)
↓
点击 "Add"
Vercel 会提示你需要配置的 DNS 记录,类似这样:
Type: CNAME
Name: www (或 @)
Value: cname.vercel-dns.com
步骤 2: 配置 DNS(两种情况)
情况 A: 子域名(如 www.example.com)
最简单! 只需添加 CNAME 记录
在你的域名注册商(阿里云/Namesilo)添加 DNS 记录:
| 类型 | 名称 | 目标 | TTL |
|---|---|---|---|
CNAME | www | cname.vercel-dns.com | Auto 或 600 |
阿里云操作步骤:
- 登录阿里云 → 域名控制台 → DNS 管理
- 点击 “添加记录”
- 填写上述信息 → 保存
Namesilo 操作步骤:
- 登录 Namesilo → Domain Manager
- 找到域名,点击蓝色小球图标 → “Manage DNS”
- 添加新的 CNAME 记录
情况 B: Apex 域名(如 example.com)
需要修改 Nameservers (推荐使用 Cloudflare)
为什么这样做?
- Apex 域名技术上需要 A 记录,但 Vercel 的 IP 可能变化
- 使用 Cloudflare 托管 DNS 可以解决这个问题,并获得 CDN 加速
步骤:
- 将域名托管到 Cloudflare(见下文 3.3 节)
- 在 Cloudflare 添加 DNS 记录:
- Type:
CNAME - Name:
@ - Target:
cname.vercel-dns.com - Proxy status: 关闭(橙色云变灰色云)
- Type:
- 回到 Vercel 验证域名
步骤 3: 验证生效
- 等待 DNS 传播(10 分钟 - 1 小时)
- 回到 Vercel → Settings → Domains
- 看到域名状态为 “Valid Configuration”(绿色 ✓)
- 访问
https://example.com验证 - SSL 证书会自动颁发(5-15 分钟)
3.3 使用 Cloudflare 加速 Vercel(推荐)
为什么要用 Cloudflare?
- ✅ 免费的全球 CDN
- ✅ 国内访问速度更快
- ✅ 额外的安全保护
步骤 1: 将域名托管到 Cloudflare
1.1 注册 Cloudflare
- 访问 Cloudflare
- 填写邮箱和密码 → “创建账号”
- 验证邮箱 → 登录成功
1.2 添加域名
- 登录后,点击 “添加站点 (Add a site)”
- 输入你的域名(如
example.com)→ “添加站点” - 选择 “Free” 免费计划 → “继续”
- Cloudflare 会扫描现有 DNS 记录 → “继续”
1.3 修改 Nameservers
Cloudflare 会给你两个 Nameserver 地址,类似:
amber.ns.cloudflare.com
logan.ns.cloudflare.com
在你的域名注册商修改 Nameservers:
阿里云示例:
- 域名控制台 → DNS 管理 → 修改 DNS 服务器
- 删除默认的,添加 Cloudflare 的两个地址
- 保存
Namesilo 示例:
- Domain Manager → 点击蓝色小球图标(⚙️)
- 选择 “Change Nameservers”
- 删除默认的,添加 Cloudflare 的两个地址
- “Submit” 保存
1.4 等待生效
- 通常需要 10 分钟 - 24 小时(大多数 30 分钟内完成)
- Cloudflare 会发邮件通知: “Your site is active on Cloudflare”
步骤 2: 在 Cloudflare 添加 DNS 记录
- Cloudflare Dashboard → 选择你的域名 → “DNS” → “Records”
- 点击 “Add record”
- 填写:
- Type:
CNAME - Name:
@(根域名) 或www(子域名) - Target:
cname.vercel-dns.com - Proxy status: DNS only(灰色云,不要开启代理)
- TTL:
Auto
- Type:
- “Save” 保存
步骤 3: 回到 Vercel 验证
- Vercel Dashboard → Settings → Domains
- 等待域名验证通过
- 完成! 你的网站现在通过 Cloudflare CDN 加速了
🎯 四、方案 B: Cloudflare Pages + 域名配置
4.1 Cloudflare Pages 部署(获取默认域名)
步骤 1: 注册 Cloudflare
- 访问 Cloudflare
- 填写邮箱和密码 → “创建账号”
- 验证邮箱 → 登录成功
步骤 2: 连接 GitHub 仓库
2.1 进入 Workers & Pages
- 登录后,点击左侧菜单 “Workers & Pages”
- 点击 “Create application”
- 选择 “Pages” 标签
- 点击 “Connect to Git”
2.2 授权 GitHub
- 点击 “Connect GitHub”
- 登录 GitHub
- 选择授权范围:
- 推荐: “Only select repositories”
- 选择你的项目仓库
- “Install & Authorize”
2.3 选择仓库
- 找到你要部署的仓库,点击 “Begin setup”
- 如果找不到,点击 “Configure GitHub App”
步骤 3: 配置构建设置
| 字段 | 说明 | 示例 |
|---|---|---|
| Project name | 项目名称(将用于免费域名) | my-awesome-app |
| Production branch | 生产分支 | main 或 master |
| Framework preset | 框架预设 | Next.js / Vite / React |
| Build command | 构建命令 | npm run build |
| Build output directory | 输出目录 | dist 或 .next |
环境变量(可选):
- 点击 “Environment variables (optional)”
- 添加如
NODE_VERSION = 18等
步骤 4: 部署
- 检查配置无误
- 点击 “Save and Deploy”
- 等待 1-3 分钟
- 获得免费域名:
https://my-awesome-app.pages.dev
完成! 你的网站已经在全球可访问了 🎉
4.2 绑定自定义域名到 Cloudflare Pages
两种配置方式
| 域名类型 | 示例 | 配置方式 |
|---|---|---|
| Apex 域名(根域名) | example.com | 需要完全托管到 Cloudflare |
| 子域名 | www.example.com 或 app.example.com | 只需添加 CNAME 记录 |
方案 A: Apex 域名(如 example.com)
步骤 1: 将域名托管到 Cloudflare
为什么这样做? Apex 域名需要完全托管在 Cloudflare,才能正确解析并获得 SSL 证书。
操作步骤:
-
添加站点:
- Cloudflare Dashboard → “添加站点”
- 输入域名(如
example.com)→ “添加站点” - 选择 “Free” 免费计划 → “继续”
- Cloudflare 扫描 DNS 记录 → “继续”
-
修改 Nameservers:
- Cloudflare 给你两个 Nameserver 地址
- 去域名注册商(阿里云/Namesilo)修改 Nameservers
- 等待生效(10 分钟 - 24 小时)
-
邮件通知: Cloudflare 会发邮件确认 “Your site is active on Cloudflare”
步骤 2: 在 Pages 添加自定义域名
- Cloudflare Dashboard → “Workers & Pages” → 选择项目
- “Custom domains” → “Set up a custom domain”
- 输入域名(如
example.com) - “Continue”
- 自动配置: 因为域名已在 Cloudflare,系统会自动添加 CNAME 记录
- “Activate domain”
- 等待 SSL 证书颁发(5-15 分钟)
完成! 访问 https://example.com 即可看到你的网站。
方案 B: 子域名(如 www.example.com)
不需要完全托管域名,只需添加 CNAME 记录。
步骤 1: 在 Cloudflare Pages 添加域名
- “Workers & Pages” → 选择项目
- “Custom domains” → “Set up a custom domain”
- 输入子域名(如
www.example.com) - “Continue”
步骤 2: 配置 DNS(两种情况)
情况 A: 域名已托管在 Cloudflare
- 系统会自动添加 CNAME 记录
- 直接点击 “Activate domain”
情况 B: 域名托管在其他地方(如阿里云、Namesilo)
在原 DNS 服务商添加 CNAME 记录:
| 类型 | 名称 | 目标 | TTL |
|---|---|---|---|
CNAME | www | 你的项目名.pages.dev | Auto 或 300 |
示例: 如果你的 Pages 项目是 my-app.pages.dev:
类型: CNAME
名称: www
目标: my-app.pages.dev
阿里云操作: 域名控制台 → DNS 管理 → 添加记录 Namesilo 操作: Domain Manager → Manage DNS → 添加 CNAME
步骤 3: 验证生效
- 等待 DNS 传播(10 分钟 - 1 小时)
- Cloudflare Pages → Custom domains
- 域名状态为 “Active”(绿色 ✓)
- 访问
https://www.example.com验证 - SSL 证书自动颁发(5-15 分钟)
✅ 五、验证部署成功
5.1 检查清单
- 访问你的域名,网站正常打开
- 浏览器地址栏显示 小绿锁 🔒(HTTPS 已启用)
- 用手机 4G/5G 网络访问,也能正常打开
- 使用 DNS Checker 查询,全球 DNS 已生效
5.2 性能测试
想知道你的网站在全球各地的速度?
- Pingdom: 测试加载速度
- GTmetrix: 性能评分
- WebPageTest: 全球多地测试
❓ 六、常见问题(FAQ)
Q1: 部署后显示“找不到服务器“?
原因: DNS 传播需要时间。
解决方案:
- 等待 10-30 分钟(最长 24 小时)
- 清除 DNS 缓存:
- Windows:
ipconfig /flushdns - macOS:
sudo dscacheutil -flushcache - Chrome: 访问
chrome://net-internals/#dns→ Clear host cache
- Windows:
- 用手机 4G 网络测试(避免本地 DNS 缓存)
Q2: 浏览器提示“不安全“?
原因: SSL 证书正在颁发中。
解决方案:
- 等待 15-30 分钟
- 强制刷新: 按
Ctrl + Shift + R(Windows)或Cmd + Shift + R(Mac) - 检查 DNS 配置: 确保 CNAME 记录指向正确
Q3: 修改代码后如何更新网站?
Vercel/Cloudflare Pages 都支持自动部署:
git add .
git commit -m "更新功能"
git push
系统会自动检测并重新部署(1-3 分钟)。
手动部署:
- Vercel: Dashboard → Deployments → “Redeploy”
- Cloudflare Pages: Workers & Pages → 项目 → “Create deployment”
Q4: 构建失败怎么办?
常见原因:
-
Node.js 版本不对 → 在环境变量添加
NODE_VERSION = 18或20 -
构建命令错误 → 检查
package.json中的scripts.build -
依赖安装失败 → 确保
package.json和package-lock.json已提交到 Git
查看构建日志:
- 项目页面 → Deployments → 点击失败的部署
- 查看详细错误信息并修复
Q5: 如何设置 www 跳转?
目标: 访问 www.example.com 自动跳转到 example.com(或反过来)。
Vercel 步骤:
- 两个域名都添加到 Domains
- Vercel 会自动设置跳转
Cloudflare Pages 步骤:
- 两个域名都添加到 Custom domains
- Cloudflare → 选择域名 → “Rules” → “Redirect Rules”
- “Create rule”:
- When:
www.example.com/* - Then: Redirect → Type:
Permanent (301) - URL:
https://example.com/$1
- When:
- “Deploy”
Q6: 国内访问慢怎么办?
原因: Vercel/Cloudflare 免费版在国内速度有限。
解决方案:
- Vercel: 使用 Cloudflare CDN 加速(见 3.3 节)
- Cloudflare Pages: 已经自带 CDN,速度相对更快
- 备选方案:
- 腾讯云 EdgeOne Pages(国内速度快,需要域名备案)
- Netlify(类似 Vercel)
Q7: 如何删除项目?
⚠️ 警告: 删除前请先删除自定义域名的 DNS 记录!
Vercel:
- Dashboard → 选择项目 → Settings
- 拉到最下方 → “Delete Project”
- 输入项目名确认
Cloudflare Pages:
- Workers & Pages → 选择项目 → Settings
- 拉到最下方 → “Delete project”
- 输入项目名确认
Q8: Vercel 和 Cloudflare Pages 该选哪个?
| 对比项 | Vercel | Cloudflare Pages |
|---|---|---|
| 部署速度 | 快(1-3 分钟) | 快(1-3 分钟) |
| 国内访问 | 较慢(需配合 Cloudflare CDN) | 较快 |
| 免费额度 | 100 GB 带宽/月 | 无限 |
| Serverless 函数 | 100次/小时(免费) | 无限 |
| 框架支持 | Next.js 官方支持最好 | 所有主流框架 |
| 推荐场景 | Next.js 项目 | 纯静态/Vue/React 项目 |
🎓 七、进阶技巧
7.1 设置环境变量
用途: 存储 API 密钥、数据库连接等敏感信息。
Vercel:
- Dashboard → 选择项目 → Settings → Environment Variables
- 点击 “Add”
- 填写变量名和值 → “Save”
- 重新部署生效
Cloudflare Pages:
- Workers & Pages → 项目 → Settings → Environment variables
- 选择环境(Production / Preview)
- “Add variable”
- 填写变量名和值 → “Save”
- 重新部署生效
7.2 配置邮件转发(免费)
想要 hello@yourdomain.com 这样的专业邮箱?
Cloudflare Email Routing(完全免费):
- Cloudflare Dashboard → 选择域名 → “Email” → “Email Routing”
- “Get started” → 验证域名
- 添加转发规则:
hello@yourdomain.com→你的 Gmail - 完成! 现在别人发到专业邮箱的邮件会自动转到你的 Gmail
7.3 监控网站在线状态
推荐工具: UptimeRobot(免费)
- 注册 UptimeRobot
- 添加监控: 输入你的网站 URL
- 设置邮件/短信提醒
- 网站宕机时自动通知你
7.4 启用 Web Analytics(免费)
Cloudflare Web Analytics(无需 Cookie,完全免费):
- Cloudflare Dashboard → “Web Analytics”
- “Add a site” → 输入网站 URL
- 获得一段 JavaScript 代码
- 粘贴到你网站的
<head>标签中:<!-- Cloudflare Web Analytics --> <script defer src='https://static.cloudflareinsights.com/beacon.min.js' data-cf-beacon='{"token": "你的token"}'></script> - 重新部署 → 回到 Cloudflare Dashboard 查看访问数据
📚 八、总结
恭喜你完成域名配置! 现在你的网站已经拥有:
✅ 全球 CDN 加速 - 访问速度快 ✅ 自动 HTTPS - 免费 SSL 证书 ✅ 自动部署 - Git 推送即部署 ✅ 无限流量 - 完全免费 ✅ 自定义域名 - 专业网址(可选)
🎯 学到的核心知识
| 概念 | 你现在知道了什么 |
|---|---|
| 域名购买 | 在域名注册商购买,不是在部署平台 |
| DNS 配置 | 通过 CNAME 记录把域名指向部署平台 |
| SSL 证书 | Vercel/Cloudflare 自动颁发,无需手动配置 |
| 环境变量 | 存储 API 密钥等敏感信息的安全方式 |
| 自动部署 | Git 推送代码,自动触发部署 |
🚀 下一步建议
- 添加 Analytics: 了解有多少人访问你的网站
- 设置专业邮箱:
contact@yourdomain.com - 优化 SEO: 让搜索引擎更容易收录
- 定期备份: 备份代码和数据库
- 监控性能: 使用 Web Vitals 追踪网站速度
📖 相关教程
记住: 部署只是开始,持续优化和维护才能让你的网站越来越好!
🎉 享受你的全球在线作品吧! 🎉
💡 Vibe Coding 心法: 域名配置不可怕! Vercel 和 Cloudflare 已经把复杂的服务器配置、DNS 解析、HTTPS 证书都搞定了。你只需要专注写代码,其他的交给这些平台! 让 AI 时代的部署变得更简单!
Supabase 配置完全指南 (小白专用)
什么是 Supabase?
Supabase 是一个开源的 Firebase 替代品,为你提供后端服务,让你不用写后端代码就能构建完整应用!
核心功能:
- 🗄️ PostgreSQL 数据库 - 免费 500MB
- 🔐 用户认证系统 - 支持邮箱、OAuth、手机号登录
- 📦 文件存储 - 免费 1GB 存储空间
- ⚡ 实时数据库 - 数据变化自动同步
- 🔒 行级安全 - 细粒度权限控制
- 🌐 自动生成 API - RESTful + GraphQL
为什么选 Supabase?
- ✅ 完全免费 (个人项目)
- ✅ 无需信用卡
- ✅ 部署简单
- ✅ 与 Vercel 完美配合
第一步: 注册 Supabase 账号
1.1 访问 Supabase 官网
打开浏览器,访问: https://supabase.com
1.2 使用 GitHub 账号登录 (强烈推荐)
点击右上角 "Start your project" 按钮
↓
选择 "Continue with GitHub"
↓
授权 Supabase 访问你的 GitHub
↓
注册成功!
小白提示: 为什么用 GitHub 登录? 因为后面部署项目时,GitHub、Vercel、Supabase 三者可以无缝集成!
第二步: 创建你的第一个项目
2.1 创建新项目
详细操作步骤:
第1步: 登录后,点击 "New project" 按钮
↓
第2步: 选择 Organization (如果是第一次,会自动创建)
↓
第3步: 填写项目信息
2.2 填写项目信息
必填字段说明:
-
Name (项目名称)
- 例如:
my-learning-app或knowfun-clone - 只能用小写字母、数字和连字符
- - 这个名称会出现在数据库 URL 中
- 例如:
-
Database Password (数据库密码)
- 超级重要! 这是你的数据库主密码
- 点击 “Generate a password” 自动生成强密码
- ⚠️ 立即复制保存! 之后无法再查看
- 保存到密码管理器 (1Password 等)
-
Region (服务器区域)
- 推荐选择: Southeast Asia (Singapore) - 离中国最近
- 或选择: Northeast Asia (Tokyo) - 日本东京
- 注意: 创建后无法更改区域!
-
Pricing Plan (定价方案)
- 选择: Free (免费版)
- 免费版额度:
- 500 MB 数据库存储
- 1 GB 文件存储
- 50,000 月活用户
- 无限 API 请求
2.3 创建项目
点击 “Create new project” 按钮
等待 2-3 分钟,Supabase 会自动配置:
- PostgreSQL 数据库
- 认证服务
- 存储服务
- 实时订阅
- API 端点
第三步: 获取 API Keys (核心!)
3.1 为什么需要这些 Keys?
这些 Keys 是你的应用连接 Supabase 服务的身份凭证:
| Key 名称 | 用途 | 安全级别 | 暴露到前端? |
|---|---|---|---|
| Project URL | 服务器地址 | 公开 | ✅ 可以 |
| anon (public) key | 前端公开访问 | 公开 | ✅ 可以 |
| service_role key | 后端管理员权限 | 🔒 私密 | ❌ 绝不! |
小白必读:
anon key可以在前端使用 (加NEXT_PUBLIC_前缀)service_role key只能在后端使用,绝不能暴露到前端!
3.2 获取 API Keys - 超详细步骤
第1步: 进入 Settings 页面
项目创建完成后,你会看到项目控制台
↓
点击左侧边栏最下方的齿轮图标 ⚙️ "Settings"
↓
进入 Settings 页面
第2步: 找到 API 配置
在 Settings 页面中
↓
点击左侧菜单 "API" 选项
↓
你会看到 "Project API keys" 部分
第3步: 复制所需的 Keys
你会看到以下信息 (全部复制保存!):
📍 Project URL
https://xxxxxxxxxxxxx.supabase.co
- 变量名:
NEXT_PUBLIC_SUPABASE_URL(前端) 或SUPABASE_URL(后端) - 用途: 你的 Supabase 项目地址
- 安全: 公开,可以暴露
🔑 anon public key
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZSIsInJlZiI6...
- 变量名:
NEXT_PUBLIC_SUPABASE_ANON_KEY(前端) 或SUPABASE_KEY(后端) - 用途: 前端访问数据库
- 安全: 公开,有行级安全保护
- 位置: “Project API keys” 下的 “anon public” 行
🔐 service_role key (需要点击 “Reveal” 显示)
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZS1kZW1vIiwicm...
- 变量名:
SUPABASE_SERVICE_KEY - 用途: 后端管理员操作 (绕过行级安全)
- 安全: 🚨 绝密! 绝不能暴露到前端!
- 位置: “Project API keys” 下的 “service_role” 行,点击 “Reveal” 显示
第4步: 保存到安全的地方
创建一个临时文件保存这些信息:
# Supabase Keys - [你的项目名]
NEXT_PUBLIC_SUPABASE_URL=https://xxxxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGc...
SUPABASE_SERVICE_KEY=eyJhbGc... # 仅后端使用!
第四步: 获取数据库连接信息
4.1 获取 Database URL
详细步骤:
第1步: Settings → Database (左侧菜单)
↓
第2步: 找到 "Connection string" 部分
↓
第3步: 选择 "URI" 标签页
↓
第4步: 复制连接字符串
你会看到类似这样的连接字符串:
postgresql://postgres:[YOUR-PASSWORD]@db.xxxxx.supabase.co:5432/postgres
⚠️ 重要: 替换密码!
连接字符串中的 [YOUR-PASSWORD] 需要替换为你在创建项目时设置的数据库密码!
# 例子:
# 原始: postgresql://postgres:[YOUR-PASSWORD]@db.xxxxx.supabase.co:5432/postgres
# 替换后: postgresql://postgres:MyStr0ngP@ssw0rd@db.xxxxx.supabase.co:5432/postgres
# 环境变量
DATABASE_URL=postgresql://postgres:你的密码@db.xxxxx.supabase.co:5432/postgres
小白提示: 如果忘记了数据库密码,可以在 Settings → Database → “Database password” 处重置密码
4.2 获取 JWT Secret (用于认证)
详细步骤:
第1步: Settings → API (左侧菜单)
↓
第2步: 滚动到 "JWT Settings" 部分
↓
第3步: 找到 "JWT Secret"
↓
第4步: 点击 "Reveal" 按钮显示密钥
↓
第5步: 复制 JWT Secret
示例:
# 环境变量
SUPABASE_JWT_SECRET=your-super-secret-jwt-token-with-at-least-32-characters-long
用途:
- 验证 JWT Token 的真实性
- 后端验证用户身份
- 通常在后端框架 (FastAPI、Express) 中使用
第五步: 配置存储 (Storage)
5.1 创建 Storage Bucket
什么是 Bucket?
- Bucket 就是文件夹,用来存放文件
- 类似于 AWS S3 的 Bucket 概念
- 每个 Bucket 可以设置不同的访问权限
创建步骤:
第1步: 点击左侧菜单 "Storage"
↓
第2步: 点击 "Create a new bucket" 按钮
↓
第3步: 填写 Bucket 信息
Bucket 配置:
-
Name (名称)
- 例如:
avatars(用户头像) - 或:
documents(文档文件) - 或:
knowfun-files(知识付费平台文件)
- 例如:
-
Public bucket (公开访问)
- ✅ 勾选: 文件可以通过 URL 直接访问 (适合图片、视频)
- ❌ 不勾选: 文件需要认证才能访问 (适合私密文档)
-
点击 “Create bucket”
5.2 获取 Storage Keys (S3 兼容)
Supabase Storage 支持 S3 兼容 API,你需要获取 Access Keys:
详细步骤:
第1步: Settings → Storage (左侧菜单)
↓
第2步: 滚动到 "S3 Access Keys" 部分
↓
第3步: 点击 "Generate new keys" 按钮
↓
第4步: 复制以下信息
你会得到:
# S3 Access Key ID
SUPABASE_ACCESS_KEY_ID=c2fc93cd64ef6b3c7da4eea19f60ebd8...
# S3 Secret Access Key
SUPABASE_SECRET_ACCESS_KEY=9ff1a54c867b6f97b3d8fb85b5ddd5a3
# S3 Endpoint
SUPABASE_ENDPOINT=https://xxxxx.supabase.co/storage/v1/s3
# S3 Region
SUPABASE_REGION=us-east-1 # 或你选择的区域
完整环境变量配置:
# Supabase Storage (S3 兼容)
SUPABASE_ACCESS_KEY_ID=your-access-key-id
SUPABASE_SECRET_ACCESS_KEY=your-secret-key
SUPABASE_ENDPOINT=https://xxxxx.supabase.co/storage/v1/s3
SUPABASE_REGION=us-east-1
SUPABASE_BUCKET_NAME=knowfun-files
SUPABASE_PUBLIC_URL=https://xxxxx.supabase.co/storage/v1/object/public
第六步: 配置认证 (Authentication)
6.1 启用认证提供商
Supabase 支持多种登录方式:
第1步: 点击左侧菜单 "Authentication"
↓
第2步: 点击 "Providers" 标签页
↓
第3步: 选择要启用的登录方式
常用登录方式:
1️⃣ Email (邮箱登录) - 默认启用
- 用户用邮箱 + 密码注册登录
- 支持邮箱验证
2️⃣ Google OAuth
点击 "Google" → 启用开关
↓
填写 Google OAuth 凭证:
- Client ID: 从 Google Cloud Console 获取
- Client Secret: 从 Google Cloud Console 获取
↓
点击 "Save"
3️⃣ GitHub OAuth
点击 "GitHub" → 启用开关
↓
填写 GitHub OAuth 凭证:
- Client ID: 从 GitHub Developer Settings 获取
- Client Secret: 从 GitHub Developer Settings 获取
↓
点击 "Save"
6.2 配置邮件模板
Authentication → Email Templates
↓
自定义邮件内容:
- Confirm signup (注册确认邮件)
- Magic Link (无密码登录邮件)
- Change Email Address (更改邮箱邮件)
- Reset Password (重置密码邮件)
第七步: 完整环境变量清单
7.1 前端环境变量 (.env.local)
# Supabase 配置 (前端)
NEXT_PUBLIC_SUPABASE_URL=https://xxxxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGc...
# API 地址 (可选)
NEXT_PUBLIC_API_URL=http://localhost:8000
保存位置:
- Next.js 项目:
frontend/.env.local - React/Vue 项目:
.env.local
7.2 后端环境变量 (.env)
# Supabase 数据库配置
SUPABASE_URL=https://xxxxx.supabase.co
SUPABASE_KEY=eyJhbGc... # anon key
SUPABASE_SERVICE_KEY=eyJhbGc... # service_role key (保密!)
DATABASE_URL=postgresql://postgres:密码@db.xxxxx.supabase.co:5432/postgres
SUPABASE_JWT_SECRET=your-jwt-secret
# Supabase Storage 配置
SUPABASE_ACCESS_KEY_ID=xxx
SUPABASE_SECRET_ACCESS_KEY=xxx
SUPABASE_ENDPOINT=https://xxxxx.supabase.co/storage/v1/s3
SUPABASE_REGION=us-east-1
SUPABASE_BUCKET_NAME=knowfun-files
SUPABASE_PUBLIC_URL=https://xxxxx.supabase.co/storage/v1/object/public
保存位置:
- FastAPI/Express 项目:
backend/.env - Python 项目:
.env
第八步: 部署到 Vercel 时配置
8.1 在 Vercel 添加环境变量
第1步: 登录 Vercel Dashboard
↓
第2步: 选择你的项目
↓
第3步: Settings → Environment Variables
↓
第4步: 添加 Supabase Keys
前端项目需要添加:
NEXT_PUBLIC_SUPABASE_URL = https://xxxxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY = eyJhbGc...
后端项目需要添加:
SUPABASE_URL = https://xxxxx.supabase.co
SUPABASE_KEY = eyJhbGc...
SUPABASE_SERVICE_KEY = eyJhbGc...
DATABASE_URL = postgresql://postgres:密码@...
SUPABASE_JWT_SECRET = your-jwt-secret
重要: 添加完环境变量后,必须重新部署才会生效!
第九步: 验证配置是否成功
9.1 测试数据库连接
在你的项目中创建一个测试文件:
# test_supabase.py (Python)
import os
from supabase import create_client, Client
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_KEY")
supabase: Client = create_client(url, key)
# 测试连接
response = supabase.table("test").select("*").execute()
print("✅ 数据库连接成功!")
print(response)
// test_supabase.js (JavaScript)
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = process.env.NEXT_PUBLIC_SUPABASE_URL
const supabaseKey = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY
const supabase = createClient(supabaseUrl, supabaseKey)
// 测试连接
async function testConnection() {
const { data, error } = await supabase.from('test').select('*')
if (error) {
console.error('❌ 连接失败:', error)
} else {
console.log('✅ 数据库连接成功!', data)
}
}
testConnection()
9.2 测试文件上传
// 测试上传文件
async function testUpload() {
const file = new File(['Hello World'], 'test.txt', { type: 'text/plain' })
const { data, error } = await supabase.storage
.from('knowfun-files')
.upload('test/test.txt', file)
if (error) {
console.error('❌ 上传失败:', error)
} else {
console.log('✅ 文件上传成功!', data)
}
}
testUpload()
常见问题 FAQ
Q1: 忘记数据库密码怎么办?
解决方案:
第1步: Settings → Database
↓
第2步: 找到 "Database password" 部分
↓
第3步: 点击 "Reset database password" 按钮
↓
第4步: 设置新密码
↓
第5步: 更新 DATABASE_URL 中的密码
Q2: 如何查看数据库中的数据?
使用内置的 Table Editor:
第1步: 点击左侧菜单 "Table Editor"
↓
第2步: 选择表名
↓
第3步: 查看/编辑数据
或使用 SQL Editor:
第1步: 点击左侧菜单 "SQL Editor"
↓
第2步: 编写 SQL 查询
↓
第3步: 点击 "Run" 执行
Q3: 如何创建数据库表?
方法一: 使用 Table Editor (可视化)
Table Editor → New table → 填写表名和字段
方法二: 使用 SQL Editor
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
email TEXT UNIQUE NOT NULL,
name TEXT,
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
Q4: Service Role Key 泄露了怎么办?
紧急处理:
第1步: Settings → API → "Reset service_role secret"
↓
第2步: 立即更新所有使用该 Key 的地方
↓
第3步: 重新部署应用
Q5: 免费版额度够用吗?
免费版限制:
| 项目 | 免费额度 | 够用吗? |
|---|---|---|
| 数据库存储 | 500 MB | ✅ 小项目够用 |
| 文件存储 | 1 GB | ✅ 图片/文档够用 |
| 月活用户 | 50,000 | ✅ 个人项目绝对够 |
| 数据库带宽 | 5 GB | ⚠️ 流量大时可能不够 |
| API 请求 | 无限 | ✅ 完全够用 |
小白建议: 个人学习和小项目,免费版完全够用!
Q6: 如何升级到付费版?
如果需要更多资源:
Settings → Billing → 选择 Pro 计划 ($25/月)
Pro 计划优势:
- 8 GB 数据库存储
- 100 GB 文件存储
- 100,000 月活用户
- 无限带宽
- 优先支持
实战案例: 5 分钟搭建用户认证系统
准备工作
# 1. 创建 Supabase 项目
# 2. 获取 API Keys
# 3. 安装依赖
npm install @supabase/supabase-js
前端代码 (Next.js)
// lib/supabase.js
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = process.env.NEXT_PUBLIC_SUPABASE_URL
const supabaseKey = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY
export const supabase = createClient(supabaseUrl, supabaseKey)
// 注册用户
export async function signUp(email, password) {
const { data, error } = await supabase.auth.signUp({
email,
password,
})
return { data, error }
}
// 登录
export async function signIn(email, password) {
const { data, error } = await supabase.auth.signInWithPassword({
email,
password,
})
return { data, error }
}
// 登出
export async function signOut() {
const { error } = await supabase.auth.signOut()
return { error }
}
// 获取当前用户
export async function getUser() {
const { data: { user } } = await supabase.auth.getUser()
return user
}
完成! 你有了一个完整的认证系统!
安全最佳实践
1. 保护你的 Service Role Key
# ❌ 错误: 暴露到前端
const supabase = createClient(url, serviceRoleKey) # 危险!
# ✅ 正确: 只在后端使用
# 前端用 anon key,后端用 service_role key
2. 启用行级安全 (RLS)
-- 启用 RLS
ALTER TABLE users ENABLE ROW LEVEL SECURITY;
-- 创建策略: 用户只能看到自己的数据
CREATE POLICY "Users can view own data"
ON users
FOR SELECT
USING (auth.uid() = id);
-- 创建策略: 用户只能更新自己的数据
CREATE POLICY "Users can update own data"
ON users
FOR UPDATE
USING (auth.uid() = id);
3. 使用环境变量
# ✅ 正确
const url = process.env.NEXT_PUBLIC_SUPABASE_URL
# ❌ 错误: 直接写在代码里
const url = "https://xxxxx.supabase.co"
4. 定期轮换密钥
- 每 6 个月更换一次 Service Role Key
- 数据库密码定期更换
- 怀疑泄露时立即重置
参考资源
小结
Supabase 配置就是这么简单:
- 注册账号 - 用 GitHub 登录
- 创建项目 - 选择区域,设置密码
- 获取 Keys - 复制 URL、anon key、service_role key
- 配置存储 - 创建 Bucket,获取 S3 Keys
- 启用认证 - 选择登录方式
- 添加到项目 - 配置环境变量
- 部署到 Vercel - 添加环境变量并部署
现在就开始用 Supabase 构建你的应用吧! 🚀
💡 Vibe Coding 心法: Supabase 就像你的私人后端团队! 数据库、认证、存储全都帮你搞定,你只需要专注于前端开发和业务逻辑。让 AI 时代的开发变得更简单!
Stripe 支付集成指南
什么是 Stripe?
Stripe 是全球领先的在线支付处理平台,专为 SaaS 和互联网企业设计。
核心优势:
- 全球覆盖 - 支持 135+ 种货币,覆盖 195+ 个国家
- 安全合规 - PCI DSS Level 1 认证,保障支付安全
- 开发友好 - 提供完善的 API 和 SDK
- 费率透明 - 标准费率 2.9% + $0.30/笔
为什么选择 Stripe?
- 适合独立开发者(无需复杂资质)
- 完善的文档和 API(开发体验好)
- 与 Vercel 等平台无缝集成
- 支持订阅、一次性付款等多种模式
第一步:注册 Stripe 账户
1.1 访问 Stripe 官网
打开浏览器访问:https://stripe.com 或 https://dashboard.stripe.com
1.2 创建账户
点击 "Start now" 或 "Sign up" 按钮
↓
填写邮箱地址
↓
设置密码
↓
完成邮箱验证
↓
登录后台
提示: Stripe 提供测试模式,在完成身份验证前可以使用 Sandbox(测试环境)进行开发
1.3 完成身份验证
登录后,Stripe 会要求填写以下信息:
第1步: 选择账户类型
- 个人 (Individual)
- 公司 (Company)
第2步: 填写基本信息
- 姓名
- 地址
- 电话号码
第3步: 提供银行账户信息(可选)
- 用于收款提现
- 需要验证银行账户
注意: 在 Live 模式(生产环境)启用前需要完成验证,Sandbox 模式(测试环境)无需验证
第二步:理解 Sandbox vs Live 模式
2.1 什么是 Sandbox 模式?
Stripe 提供两种模式:
| 模式 | 用途 | 资金 | 需要验证? |
|---|---|---|---|
| Sandbox (测试模式) | 开发测试 | 虚拟资金,测试卡号 | 不需要 |
| Live (生产模式) | 正式收款 | 真实资金,真实交易 | 需要 |
2.2 切换模式
在 Stripe Dashboard 右上角,可以看到模式切换开关:
Test mode (测试模式) ⟷ Live mode (生产模式)
推荐开发流程:
第1步: 在 Sandbox 模式下开发测试
↓
第2步: 确保所有功能正常
↓
第3步: 切换到 Live 模式
↓
第4步: 进行真实交易
第三步:获取 API 密钥
3.1 找到密钥位置
- 登录 Stripe Dashboard
- 点击左侧菜单 “Developers”
- 选择 “API keys”
3.2 密钥类型
| 密钥类型 | 格式 | 用途 |
|---|---|---|
| Publishable key | pk_test_xxx / pk_live_xxx | 前端使用,可公开 |
| Secret key | sk_test_xxx / sk_live_xxx | 后端使用,必须保密 |
安全提示: Secret key 绝对不能暴露在前端代码或 GitHub 仓库中!
3.3 配置环境变量
在项目根目录创建 .env.local 文件:
# Stripe 测试环境密钥
NEXT_PUBLIC_STRIPE_PUBLISHABLE_KEY=pk_test_xxx
STRIPE_SECRET_KEY=sk_test_xxx
# Stripe 生产环境密钥(上线时替换)
# NEXT_PUBLIC_STRIPE_PUBLISHABLE_KEY=pk_live_xxx
# STRIPE_SECRET_KEY=sk_live_xxx
第四步:安装 Stripe SDK
4.1 安装依赖
# 安装 Stripe Node.js SDK
npm install stripe
# 安装 Stripe React 组件(可选)
npm install @stripe/stripe-js @stripe/react-stripe-js
4.2 初始化 Stripe
后端初始化 (Node.js/Next.js API):
// lib/stripe.js
import Stripe from 'stripe';
export const stripe = new Stripe(process.env.STRIPE_SECRET_KEY, {
apiVersion: '2023-10-16',
});
前端初始化:
// lib/stripe-client.js
import { loadStripe } from '@stripe/stripe-js';
export const stripePromise = loadStripe(
process.env.NEXT_PUBLIC_STRIPE_PUBLISHABLE_KEY
);
第五步:创建支付流程
5.1 创建 Checkout Session (推荐)
API 路由 (pages/api/checkout.js):
import { stripe } from '@/lib/stripe';
export default async function handler(req, res) {
if (req.method !== 'POST') {
return res.status(405).json({ error: 'Method not allowed' });
}
try {
const session = await stripe.checkout.sessions.create({
payment_method_types: ['card'],
line_items: [
{
price_data: {
currency: 'usd',
product_data: {
name: '产品名称',
description: '产品描述',
},
unit_amount: 1999, // 金额单位是分,1999 = $19.99
},
quantity: 1,
},
],
mode: 'payment', // 'payment' 一次性付款, 'subscription' 订阅
success_url: `${req.headers.origin}/success?session_id={CHECKOUT_SESSION_ID}`,
cancel_url: `${req.headers.origin}/cancel`,
});
res.status(200).json({ sessionId: session.id, url: session.url });
} catch (error) {
res.status(500).json({ error: error.message });
}
}
5.2 前端调用支付
// components/CheckoutButton.jsx
import { stripePromise } from '@/lib/stripe-client';
export default function CheckoutButton() {
const handleCheckout = async () => {
const response = await fetch('/api/checkout', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
});
const { url } = await response.json();
// 跳转到 Stripe 支付页面
window.location.href = url;
};
return (
<button onClick={handleCheckout}>
立即购买
</button>
);
}
第六步:处理 Webhook
6.1 什么是 Webhook?
Webhook 是 Stripe 主动通知你的服务器支付状态变化的方式。
6.2 创建 Webhook 端点
API 路由 (pages/api/webhook.js):
import { stripe } from '@/lib/stripe';
import { buffer } from 'micro';
export const config = {
api: { bodyParser: false },
};
export default async function handler(req, res) {
if (req.method !== 'POST') {
return res.status(405).end();
}
const buf = await buffer(req);
const sig = req.headers['stripe-signature'];
const webhookSecret = process.env.STRIPE_WEBHOOK_SECRET;
let event;
try {
event = stripe.webhooks.constructEvent(buf, sig, webhookSecret);
} catch (err) {
console.error(`Webhook Error: ${err.message}`);
return res.status(400).send(`Webhook Error: ${err.message}`);
}
// 处理不同事件类型
switch (event.type) {
case 'checkout.session.completed':
const session = event.data.object;
// 处理支付成功逻辑
console.log('支付成功:', session.id);
break;
case 'payment_intent.succeeded':
console.log('付款意图成功');
break;
default:
console.log(`未处理的事件类型: ${event.type}`);
}
res.status(200).json({ received: true });
}
6.3 配置 Webhook
- 在 Stripe Dashboard 进入 “Developers” → “Webhooks”
- 点击 “Add endpoint”
- 输入你的 Webhook URL:
https://yourdomain.com/api/webhook - 选择要监听的事件(如
checkout.session.completed) - 复制 Webhook Secret 到环境变量
测试卡号
在 Sandbox 模式下使用以下测试卡号:
| 卡号 | 说明 |
|---|---|
4242 4242 4242 4242 | 成功支付 |
4000 0000 0000 0002 | 卡被拒绝 |
4000 0000 0000 9995 | 余额不足 |
- 有效期:任意未来日期(如 12/34)
- CVC:任意3位数字(如 123)
- 邮编:任意5位数字(如 12345)
常见问题
Q: 中国开发者可以使用 Stripe 吗?
A: 可以,但需要注意:
- 需要有海外银行账户(如香港账户)
- 或使用 Stripe Atlas 注册美国公司
- 部分功能可能受限
Q: 如何处理退款?
A: 使用 Stripe API:
const refund = await stripe.refunds.create({
payment_intent: 'pi_xxx',
amount: 1000, // 可选,部分退款
});
Q: 费用如何计算?
A: 标准费率:
- 国际卡:2.9% + $0.30
- 订阅额外费用:0.5%
- 货币转换:1%
更多资源
🎨 从 0 到 1 上线 AI 图片站实战教程 (小白专用)
写在前面: 这是一个完整的实战项目教程,教你如何用 Vercel + Cloudflare R2 + Supabase 白嫖方案,从零开始搭建一个可以对外访问、可被搜索引擎收录的 AI 图片站。总成本只需要域名费用(约 $10-17/年),其他全部免费!
案例项目: Pet Emoji Generator (宠物表情包生成器)
- 功能: 上传宠物照片 → AI 生成 9 宫格表情包
- 成本: $17/年 (仅域名费用)
- 用时: 半天 ~ 1 天
- 访问: www.petemojimaker.com
📌 重要! 理解技术方案和成本 (小白必读)
完整技术栈
| 服务 | 用途 | 获取位置 | 费用 | 是否必需? |
|---|---|---|---|---|
| Namecheap | 域名购买 | namecheap.com | $10-17/年 | ✅ 必需 |
| Vercel | 网站部署 | vercel.com | 免费 | ✅ 必需 |
| Cloudflare R2 | 图片存储 | cloudflare.com | 免费 10GB | ✅ 必需 |
| Supabase | 数据库 | supabase.com | 免费 500MB | ✅ 必需 |
| GitHub | 代码托管 | github.com | 免费 | ✅ 必需 |
| Cursor | AI 编程工具 | cursor.sh | 免费/付费 | ⚠️ 可选 |
小白必读:
- ❌ 错误: 所有配置都在 Vercel 完成
- ✅ 正确: 域名在 Namecheap 购买,图片存 R2,数据存 Supabase,网站部署到 Vercel
- 总成本 = 域名费用($10-17/年) + 其他全免费!
🏗️ 一、架构总览
1.1 完整链路图
用户访问
↓
自定义域名 (example.com)
↓
Vercel (Next.js SSR/静态页面)
↓
┌─────────────────┬──────────────────┐
│ │ │
Cloudflare R2 Supabase AI API
(图片存储) (数据库) (图片生成)
│ │ │
img.example.com 生成记录/点赞 ComfyUI/Replicate
1.2 技术方案说明
前端:
- Next.js 提供静态/SSR 页面
- Tailwind CSS 样式
- React 组件
后端:
- Vercel Serverless Functions (Next.js API Routes)
- Supabase 数据库 (PostgreSQL)
存储:
- Cloudflare R2 存储图片 (S3 兼容)
- 自定义域名访问 (如
img.example.com)
部署:
- GitHub 代码托管
- Vercel 自动部署
- 全球 CDN 加速
🚀 二、完整开发流程 (5 大步骤)
流程总览
Step 1: 购买域名 (Namecheap)
↓
Step 2: 开发项目 (Next.js + Cursor)
↓
Step 3: 部署到 Vercel + 绑定域名
↓
Step 4: 配置 Cloudflare R2 图片存储
↓
Step 5: 配置 Supabase 数据库 + SEO 优化
📦 Step 1: 购买域名 (Namecheap)
1.1 为什么要买域名?
Vercel 默认域名 vs 自定义域名:
| 对比项 | Vercel 默认域名 | 自定义域名 |
|---|---|---|
| 格式 | your-app.vercel.app | example.com |
| 费用 | 免费 | $10-17/年 |
| 专业度 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| SEO 收录 | 一般 | 好 |
| 可信度 | 低 | 高 |
1.2 推荐域名注册商
| 注册商 | 优点 | 价格 | 推荐指数 |
|---|---|---|---|
| Namecheap | 便宜,面板简单,送隐私保护 | $8-12/年 | ⭐⭐⭐⭐⭐ |
| Cloudflare | 成本价,无加价 | $9/年 | ⭐⭐⭐⭐ |
| 阿里云 | 中文界面,支付宝 | ¥55/年 | ⭐⭐⭐ |
1.3 购买步骤 (以 Namecheap 为例)
第1步: 访问 Namecheap.com
↓
第2步: 搜索域名 (如 petemojimaker.com)
↓
第3步: 加入购物车 → 结账
↓
第4步: 完成支付
↓
第5步: 域名显示在 Domain List
域名选择建议:
- ✅ 简短易记 (如
petmaker.com) - ✅ 优先
.com/.io/.app - ✅ 避免数字和连字符
- ✅ 与产品功能相关
💻 Step 2: 开发项目 (Next.js + Cursor)
2.1 技术栈
# 前端框架
Next.js 14 (App Router)
React 18
Tailwind CSS
TypeScript
# 图片处理
Sharp (压缩)
Next/Image (优化)
# AI 集成
ComfyUI / Replicate API
2.2 项目初始化
# 创建 Next.js 项目
npx create-next-app@latest pet-emoji-generator
# 选择配置
✅ TypeScript
✅ ESLint
✅ Tailwind CSS
✅ App Router
✅ src/ directory
❌ Turbopack
# 进入项目
cd pet-emoji-generator
# 安装依赖
npm install @supabase/supabase-js @aws-sdk/client-s3
2.3 核心功能实现 (使用 Cursor)
功能清单:
- 用户上传图片
- AI 生成 9 宫格表情包
- 图片保存到 R2
- 生成记录存入 Supabase
- 点赞/下载统计
- SEO 优化
Cursor 开发提示词示例:
需求: 实现宠物表情包生成器
技术栈:
- Next.js 14 (App Router)
- Supabase 数据库
- Cloudflare R2 存储
- Tailwind CSS
功能:
1. 首页: 上传宠物照片
2. 调用 AI API 生成 9 宫格表情包
3. 将生成的图片上传到 R2
4. 记录生成信息到 Supabase
5. 展示生成结果,支持下载
6. 统计点赞和下载次数
请生成完整代码结构
2.4 项目结构
pet-emoji-generator/
├── src/
│ ├── app/
│ │ ├── page.tsx # 首页
│ │ ├── api/
│ │ │ ├── generate/route.ts # AI 生成 API
│ │ │ ├── upload/route.ts # R2 上传 API
│ │ │ └── stats/route.ts # 统计 API
│ │ ├── gallery/page.tsx # 作品画廊
│ │ └── layout.tsx
│ ├── components/
│ │ ├── UploadForm.tsx
│ │ ├── ImageGrid.tsx
│ │ └── DownloadButton.tsx
│ └── lib/
│ ├── supabase.ts # Supabase 客户端
│ └── r2.ts # R2 客户端
├── .env.local # 环境变量
└── package.json
🌐 Step 3: 部署到 Vercel + 绑定域名
3.1 推送代码到 GitHub
# 初始化 Git
git init
git add .
git commit -m "Initial commit: Pet Emoji Generator"
# 创建 GitHub 仓库后
git remote add origin https://github.com/你的用户名/pet-emoji-generator.git
git branch -M main
git push -u origin main
3.2 部署到 Vercel
步骤 1: 导入 GitHub 仓库
访问 Vercel.com → 登录
↓
点击 "Add New..." → "Project"
↓
选择 "Import Git Repository" → "GitHub"
↓
找到 pet-emoji-generator → "Import"
步骤 2: 配置项目
| 字段 | 值 | 说明 |
|---|---|---|
| Framework Preset | Next.js | 自动识别 |
| Build Command | npm run build | 默认 |
| Output Directory | .next | 默认 |
步骤 3: 添加环境变量
现在先跳过,后续配置完 R2 和 Supabase 后再添加
步骤 4: 部署
点击 "Deploy"
↓
等待 1-3 分钟
↓
获得 Vercel 默认域名: https://pet-emoji-generator.vercel.app
3.3 绑定自定义域名到 Vercel
步骤 1: 在 Vercel 添加域名
Vercel Dashboard → 选择项目 → Settings → Domains
↓
点击 "Add" 按钮
↓
输入域名: petemojimaker.com (或 www.petemojimaker.com)
↓
点击 "Add"
Vercel 会提示需要配置的 DNS 记录,类似:
Type: A
Name: @
Value: 76.76.21.21
Type: CNAME
Name: www
Value: cname.vercel-dns.com
步骤 2: 在 Namecheap 配置 DNS
登录 Namecheap → Domain List
↓
选择域名 → Manage → Advanced DNS
↓
添加 DNS 记录:
| 类型 | 主机 | 值 | TTL |
|---|---|---|---|
A Record | @ | 76.76.21.21 | Automatic |
CNAME Record | www | cname.vercel-dns.com | Automatic |
保存
↓
等待 10-30 分钟 DNS 生效
↓
回到 Vercel,域名状态变为 "Valid Configuration"
步骤 3: HTTPS 自动启用
Vercel 会自动申请 Let’s Encrypt SSL 证书,无需手动配置。
验证:
- 访问
https://petemojimaker.com - 看到浏览器小绿锁 🔒
🖼️ Step 4: 配置 Cloudflare R2 图片存储
4.1 为什么用 R2?
Vercel 内置存储 vs Cloudflare R2:
| 对比项 | Vercel | Cloudflare R2 |
|---|---|---|
| 免费额度 | 100MB | 10GB |
| 价格 | 昂贵 | S3 的 1/10 |
| 适合场景 | 小文件 | 图片/视频站 |
4.2 创建 R2 Bucket
步骤 1: 注册 Cloudflare
访问 Cloudflare.com → 注册/登录
↓
验证邮箱
步骤 2: 创建 Bucket
Cloudflare Dashboard → R2 → "Create bucket"
↓
Bucket name: pet-emojis (只能小写字母、数字、连字符)
↓
Location: Automatic (或选择离用户最近的区域)
↓
点击 "Create bucket"
步骤 3: 开启公开访问
进入 Bucket → Settings → Public access
↓
点击 "Allow Access" (允许公开访问)
↓
确认
4.3 绑定自定义域名到 R2
为什么要绑定域名?
- ✅ 更专业 (
img.example.comvsxxx.r2.cloudflarestorage.com) - ✅ 更好的 SEO
- ✅ 防盗链控制
前提条件: 将域名托管到 Cloudflare
如果域名在 Namecheap:
第1步: Cloudflare Dashboard → "添加站点"
↓
第2步: 输入域名 petemojimaker.com → "添加站点"
↓
第3步: 选择 "Free" 免费计划 → "继续"
↓
第4步: Cloudflare 扫描 DNS 记录 → "继续"
↓
第5步: Cloudflare 给你两个 Nameserver 地址:
amber.ns.cloudflare.com
logan.ns.cloudflare.com
在 Namecheap 修改 Nameservers:
Namecheap → Domain List → Manage
↓
Domain → Nameservers → "Custom DNS"
↓
删除默认的 Nameservers
↓
添加 Cloudflare 的两个地址:
amber.ns.cloudflare.com
logan.ns.cloudflare.com
↓
保存 → 等待 10 分钟 - 24 小时生效
等待 Cloudflare 邮件确认: “Your site is active on Cloudflare”
绑定子域名到 R2
Cloudflare Dashboard → R2 → 选择 Bucket (pet-emojis)
↓
Custom Domains → "Connect domain"
↓
输入子域名: img.petemojimaker.com
↓
点击 "Continue"
↓
Cloudflare 自动添加 DNS 记录
↓
等待 5-15 分钟生效
验证:
- 访问
https://img.petemojimaker.com/test.png(上传测试文件后) - 能正常访问即成功
4.4 获取 R2 API 凭证
用于代码上传文件到 R2:
Cloudflare Dashboard → R2 → Overview
↓
"Manage R2 API Tokens" → "Create API token"
↓
Token name: pet-emoji-uploader
↓
Permissions: "Object Read & Write"
↓
点击 "Create API Token"
↓
复制保存:
- Access Key ID
- Secret Access Key
- Endpoint (S3 兼容端点)
保存到 .env.local:
# Cloudflare R2
R2_ACCOUNT_ID=你的账号ID
R2_ACCESS_KEY_ID=复制的 Access Key ID
R2_SECRET_ACCESS_KEY=复制的 Secret Access Key
R2_BUCKET_NAME=pet-emojis
R2_PUBLIC_URL=https://img.petemojimaker.com
🗄️ Step 5: 配置 Supabase 数据库
5.1 创建 Supabase 项目
访问 Supabase.com → 注册/登录
↓
"New project"
↓
填写信息:
Project name: pet-emoji-generator
Database Password: 生成强密码 (保存!)
Region: Southeast Asia (Singapore) - 离中国最近
↓
选择 "Free" 免费计划
↓
点击 "Create new project"
↓
等待 2-3 分钟创建完成
5.2 创建数据表
进入 SQL Editor:
Supabase Dashboard → SQL Editor → "New query"
执行 SQL:
-- 创建表: 记录图片生成信息
create table if not exists emoji_generations (
id uuid primary key default gen_random_uuid(),
image_url text not null,
prompt text,
ip varchar(64),
created_at timestamp with time zone default now(),
likes int default 0,
downloads int default 0
);
-- 创建索引: 加速查询
create index idx_created_at on emoji_generations(created_at desc);
-- 启用行级安全 (RLS)
alter table emoji_generations enable row level security;
-- 创建策略: 允许所有人读取
create policy "Allow public read access"
on emoji_generations
for select
using (true);
-- 创建策略: 允许所有人插入 (实际应该限制)
create policy "Allow public insert"
on emoji_generations
for insert
with check (true);
点击 “Run” 执行。
5.3 获取 Supabase API Keys
Supabase Dashboard → Settings → API
↓
复制以下信息:
| Key 名称 | 用途 | 暴露到前端? |
|---|---|---|
| Project URL | Supabase 项目地址 | ✅ 可以 |
| anon public key | 前端公开访问 | ✅ 可以 |
| service_role key | 后端管理员权限 | ❌ 绝不! |
保存到 .env.local:
# Supabase
NEXT_PUBLIC_SUPABASE_URL=https://xxxxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGc...
SUPABASE_SERVICE_KEY=eyJhbGc... # 仅后端使用!
🔧 Step 6: 完整环境变量配置
6.1 本地开发环境变量
创建 .env.local 文件:
# Vercel 部署
NEXT_PUBLIC_SITE_URL=https://petemojimaker.com
# Supabase 数据库
NEXT_PUBLIC_SUPABASE_URL=https://xxxxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGc...
SUPABASE_SERVICE_KEY=eyJhbGc...
# Cloudflare R2 存储
R2_ACCOUNT_ID=你的账号ID
R2_ACCESS_KEY_ID=xxx
R2_SECRET_ACCESS_KEY=xxx
R2_BUCKET_NAME=pet-emojis
R2_PUBLIC_URL=https://img.petemojimaker.com
# AI API (示例: Replicate)
REPLICATE_API_TOKEN=r8_xxx
6.2 在 Vercel 添加环境变量
Vercel Dashboard → 选择项目 → Settings → Environment Variables
↓
逐个添加上述变量:
添加方法:
- Name:
NEXT_PUBLIC_SUPABASE_URL - Value:
https://xxxxx.supabase.co - Environment: 选择
Production,Preview,Development - 点击 “Save”
重复添加所有变量
重新部署:
Deployments → 最新部署 → "Redeploy"
📊 Step 7: SEO 优化 (免费流量!)
7.1 为什么要做 SEO?
SEO = 免费的持续流量来源
| 流量来源 | 成本 | 持续性 | 难度 |
|---|---|---|---|
| SEO (搜索引擎) | 免费 | 长期 | 中 |
| 广告投放 | 高 | 短期 | 低 |
| 社交媒体 | 低 | 短期 | 中 |
7.2 SEO 清单 (必做 7 项)
✅ 1. 生成 sitemap.xml
Next.js App Router: 创建 src/app/sitemap.ts
import { MetadataRoute } from 'next'
export default function sitemap(): MetadataRoute.Sitemap {
return [
{
url: 'https://petemojimaker.com',
lastModified: new Date(),
changeFrequency: 'daily',
priority: 1,
},
{
url: 'https://petemojimaker.com/gallery',
lastModified: new Date(),
changeFrequency: 'daily',
priority: 0.8,
},
]
}
访问: https://petemojimaker.com/sitemap.xml
✅ 2. 生成 robots.txt
创建 src/app/robots.ts:
import { MetadataRoute } from 'next'
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: '*',
allow: '/',
disallow: '/api/',
},
sitemap: 'https://petemojimaker.com/sitemap.xml',
}
}
访问: https://petemojimaker.com/robots.txt
✅ 3. 优化页面元数据
首页 src/app/page.tsx:
import { Metadata } from 'next'
export const metadata: Metadata = {
title: 'Pet Emoji Generator - Turn Your Pet into 9-Grid Emojis',
description: 'Free AI-powered tool to transform your pet photos into adorable 9-grid emoji packs. Upload, generate, and download instantly!',
keywords: ['pet emoji', 'emoji generator', 'pet stickers', 'AI pet'],
openGraph: {
title: 'Pet Emoji Generator',
description: 'Turn your pet into cute emojis!',
url: 'https://petemojimaker.com',
siteName: 'Pet Emoji Maker',
images: [
{
url: 'https://img.petemojimaker.com/og-image.png',
width: 1200,
height: 630,
},
],
locale: 'en_US',
type: 'website',
},
twitter: {
card: 'summary_large_image',
title: 'Pet Emoji Generator',
description: 'Turn your pet into cute emojis!',
images: ['https://img.petemojimaker.com/og-image.png'],
},
}
✅ 4. 语义化 HTML
{/* ❌ 错误 */}
<div className="title">Pet Emoji Generator</div>
{/* ✅ 正确 */}
<h1>Pet Emoji Generator</h1>
<h2>How It Works</h2>
<h3>Step 1: Upload Photo</h3>
{/* 图片添加有意义的 alt */}
<Image
src="/example.jpg"
alt="Cute dog emoji generated by AI"
width={300}
height={300}
/>
✅ 5. 提交到 Google Search Console
访问 Google Search Console:
https://search.google.com/search-console
↓
"添加资源" → 输入 petemojimaker.com
↓
验证所有权 (选择 "HTML 标记" 方式):
复制 meta 标签 → 添加到 layout.tsx <head>
↓
点击 "验证"
↓
提交 Sitemap:
左侧菜单 "站点地图" → 输入 sitemap.xml → "提交"
✅ 6. 提交到 Bing Webmaster Tools
访问 Bing Webmaster Tools:
https://www.bing.com/webmasters
↓
"添加站点" → 输入 petemojimaker.com
↓
验证方式: "从 Google Search Console 导入"
↓
提交 Sitemap: sitemap.xml
✅ 7. 性能优化
{/* 图片懒加载 */}
<Image
src="/image.jpg"
loading="lazy"
alt="..."
/>
{/* 压缩图片 */}
// 使用 webp/avif 格式
// 适当的尺寸 (不要加载 4K 图片显示 300px)
7.3 推广建议 (获取外链)
在这些平台发布:
- ✅ Product Hunt - 科技产品
- ✅ V2EX - 程序员社区
- ✅ Twitter/X - 社交媒体
- ✅ Reddit - 相关 subreddit
- ✅ Hacker News - 技术新闻
发布策略:
- 标题: 简洁、吸引人
- 内容: 突出痛点和解决方案
- 截图: 展示实际效果
- 链接: 放在评论区或简介
❓ 常见问题 (FAQ)
Q1: R2 自定义域为什么一直验证不通过?
原因: 域名 DNS 未托管到 Cloudflare。
解决方案:
- 确认域名 Nameservers 已改为 Cloudflare
- 等待 DNS 生效 (10 分钟 - 24 小时)
- 在 Cloudflare 看到 “Active” 状态后再绑定 R2
Q2: Vercel 需要自己配置 SSL 吗?
答: 不需要。
Vercel 自动申请 Let’s Encrypt 证书并续期,域名 DNS 生效后会自动开启 HTTPS。
Q3: Supabase 的 key 会不会泄露?
答: 分情况。
- ✅
ANON_KEY可以放前端,但务必配置 RLS (行级安全) - ❌
SERVICE_ROLE_KEY绝对不能暴露,只能在服务端使用
最佳实践:
// ✅ 前端: 使用 ANON_KEY
const supabase = createClient(
process.env.NEXT_PUBLIC_SUPABASE_URL!,
process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY!
)
// ✅ 服务端: 使用 SERVICE_ROLE_KEY
const supabaseAdmin = createClient(
process.env.NEXT_PUBLIC_SUPABASE_URL!,
process.env.SUPABASE_SERVICE_KEY! // 仅服务端环境变量
)
Q4: 免费额度够用吗?
答: 早期完全够用!
| 服务 | 免费额度 | 早期项目够用吗? |
|---|---|---|
| Vercel | 100 GB 带宽/月 | ✅ 完全够 |
| Cloudflare R2 | 10 GB 存储 | ✅ 够几千张图片 |
| Supabase | 500 MB DB / 1 GB 文件 / 200K 请求/月 | ✅ 完全够 |
超出后怎么办?
- Vercel: 升级 Pro ($20/月)
- R2: 超出后 $0.015/GB/月 (很便宜)
- Supabase: 升级 Pro ($25/月)
Q5: 为什么不用 Vercel 自带的存储?
答: 太贵了!
| 对比项 | Vercel Blob | Cloudflare R2 |
|---|---|---|
| 免费额度 | 100 MB | 10 GB |
| 超出价格 | $0.20/GB | $0.015/GB |
| 带宽费用 | $0.20/GB | 免费 |
结论: R2 便宜 10 倍以上!
Q6: 如何防止恶意上传?
解决方案:
- 限制文件大小:
// 最大 5MB
if (file.size > 5 * 1024 * 1024) {
throw new Error('File too large')
}
- 限制文件类型:
const allowedTypes = ['image/jpeg', 'image/png', 'image/webp']
if (!allowedTypes.includes(file.type)) {
throw new Error('Invalid file type')
}
- IP 限流:
// 使用 Upstash Redis 或 Vercel KV
// 限制每个 IP 每小时 10 次
- 图片内容审核:
// 使用 Cloudflare AI 或 Google Vision API
// 检测不当内容
Q7: 国内访问 Vercel 慢怎么办?
解决方案:
- 使用 Cloudflare CDN 加速 (见域名配置教程 3.3 节)
- 图片走 R2 自定义域 (已经是 Cloudflare CDN)
- 考虑备选方案:
- Netlify (类似 Vercel)
- Cloudflare Pages (国内速度更快)
📊 成本总结
开发成本
| 项目 | 费用 | 说明 |
|---|---|---|
| 域名 (Namecheap) | $10-17/年 | 唯一必需费用 |
| Vercel | 免费 | 100 GB 带宽/月 |
| Cloudflare R2 | 免费 | 10 GB 存储 |
| Supabase | 免费 | 500 MB 数据库 |
| 开发工具 (Cursor) | 免费/付费 | 可选 |
| AI API | 按用量 | 看使用情况 |
总计: $10-17/年 (仅域名费用)
时间成本
| 阶段 | 用时 | 说明 |
|---|---|---|
| 学习教程 | 2-4 小时 | 阅读文档 |
| 开发项目 | 4-8 小时 | 使用 Cursor 加速 |
| 配置部署 | 1-2 小时 | 按本教程操作 |
| SEO 优化 | 1 小时 | 必做项 |
总计: 半天 ~ 1 天
🎯 总结
你学到了什么?
| 技能 | 掌握程度 |
|---|---|
| ✅ Next.js 开发 | 入门 → 熟练 |
| ✅ Vercel 部署 | 从零到上线 |
| ✅ 域名配置 | 完全理解 |
| ✅ R2 对象存储 | 掌握使用 |
| ✅ Supabase 数据库 | 基础 CRUD |
| ✅ SEO 优化 | 快速收录 |
下一步建议
- 数据分析: 接入 Google Analytics 或 Cloudflare Web Analytics
- 用户反馈: 添加评论/评分功能
- 变现探索:
- 广告 (Google AdSense)
- 付费功能 (Stripe)
- 会员订阅
- 持续优化: 根据用户反馈迭代功能
- 推广: 定期在社交媒体分享
📖 相关教程
记住:
- 先做出最小可用版本 (MVP)
- 让真实用户用起来
- 根据反馈快速迭代
- 持续优化体验与变现
用 Vercel + Cloudflare R2 + Supabase,个人也能在 0 预算内把图片站跑起来!
🎉 开始你的 AI 图片站之旅吧! 🎉
💡 Vibe Coding 心法: 不要追求完美!先用 Cursor 快速搭建 MVP,部署上线让真实用户使用,然后根据反馈快速迭代。完美的产品是迭代出来的,不是一开始设计出来的!
从 0 到 1 上线一个AI图片站
本章概览:从零到上线
这一章带你完整走一遍项目开发流程:从配置环境,到写代码,再到部署上线。
你会学到什么?
学完这章,你能独立完成:
- 配置好 Claude Code 开发环境
- 让 AI 帮你写后端代码
- 让 AI 帮你写前端代码
- 把项目部署到线上,让全世界都能访问
整体流程
环境准备 → 需求设计 → 后端开发 → 前端开发 → 部署上线
↓ ↓ ↓ ↓ ↓
3篇文章 1篇文章 1篇文章 1篇文章 1篇文章
每篇文章讲什么?
第一阶段:环境准备(先把工具装好)
| 文章 | 干嘛的 | 需要多久 |
|---|---|---|
| 01_配置Claude_Code环境 | 装好 Claude Code,能跟 AI 对话写代码 | 10分钟 |
| 02_配置Python虚拟环境 | 装好 Python,后端代码能跑起来 | 5分钟 |
| 03_安装Playwright_MCP插件 | 让 Claude 能操作浏览器帮你测试 | 5分钟 |
第二阶段:需求设计(想清楚要做啥)
| 文章 | 干嘛的 | 需要多久 |
|---|---|---|
| 04_如何设计需求 | 学会写需求文档,让 AI 理解你要做什么 | 30分钟 |
第三阶段:代码开发(让 AI 帮你写)
| 文章 | 干嘛的 | 需要多久 |
|---|---|---|
| 05_后端代码开发 | 让 Claude 帮你写后端接口 | 看项目大小 |
| 06_前端代码开发 | 让 Claude 帮你写前端页面 | 看项目大小 |
第四阶段:部署上线(让全世界能访问)
| 文章 | 干嘛的 | 需要多久 |
|---|---|---|
| 07_一条龙部署上线 | 前端部署 Vercel,后端部署 Railway | 30分钟 |
建议学习顺序
新手必读: 01 → 02 → 03 → 04
开始开发: 05 → 06
准备上线: 07
小提示:遇到不懂的名词,翻到最后看《08_名词手册》
技术栈说明
这章用的技术栈:
| 类型 | 技术 | 为什么选它 |
|---|---|---|
| 前端 | Next.js + Tailwind CSS | 主流、好学、部署方便 |
| 后端 | FastAPI + PostgreSQL | Python 写的,简单易懂 |
| 数据库 | Supabase | 免费、功能全、自带用户认证 |
| 部署 | Vercel + Railway + Cloudflare | 免费额度够用、一键部署 |
学之前需要会什么?
不需要会:
- 不需要会写代码(Claude 帮你写)
- 不需要懂服务器(平台帮你管)
- 不需要会数据库(跟着教程配就行)
需要会:
- 会用电脑打字
- 会注册账号
- 能看懂简单的英文单词
遇到问题怎么办?
- 先问 Claude — 把报错信息贴给它,让它帮你排查
- 查名词手册 — 不懂的词去《08_名词手册》查
- 搜一下 — 报错信息 + 关键词,Google 一下
- 问社群 — 实在搞不定,去社群问问其他人
配置 Claude Code 环境
跟着这篇走一遍,10 分钟搞定 Claude Code 的安装和配置。
第一步:搞个 API 密钥
Claude Code 官方的 API 有点贵,咱们先用第三方中转服务,便宜又稳定:
- aicodemirror.com
- 88code.org(推荐,有中文文档)
注册账号 → 充点钱 → 拿到你的 API 密钥,长这样:sk-xxxxx
第二步:打开终端
终端在哪? 看左边侧边栏那个蓝色小图标,点一下就出来了:
把终端想象成你跟电脑“说话“的地方。你敲一行命令,电脑就乖乖去执行。以后装包、跑脚本、配环境,都在这儿搞定。
第三步:安装 Claude Code
在终端里敲这行命令,回车:
npm install -g @anthropic-ai/claude-code
等它跑完,Claude Code 就装好了。
第四步:配置 API 密钥
有两种方式,选一个就行:
方式一:临时配置(重启终端就没了)
适合先试试水,敲这两行:
export ANTHROPIC_BASE_URL="https://www.88code.org/api"
export ANTHROPIC_AUTH_TOKEN="你的API密钥"
把“你的API密钥“换成你刚才拿到的那串 sk-xxxxx。
方式二:永久配置(一劳永逸)
不想每次都敲?把配置写进系统文件,一次搞定:
echo 'export ANTHROPIC_BASE_URL="https://www.88code.org/api"' >> ~/.zshrc
echo 'export ANTHROPIC_AUTH_TOKEN="你的API密钥"' >> ~/.zshrc
source ~/.zshrc
小提示:Mac 默认用 zsh,所以写到
~/.zshrc。如果你用的是 bash,就换成~/.bash_profile。
第五步:验证一下
敲 claude 回车,如果出来 Claude Code 的界面,恭喜你,配置成功了!
遇到问题?
查查官方文档:88code.org 配置指南
Python 虚拟环境配置
写代码之前,先把 Python 环境配好。别担心,直接让 Claude Code 帮你搞定。
为什么要用虚拟环境?
想象一下:项目 A 要用 Python 3.8,项目 B 要用 Python 3.12,装在一起不打架才怪。
虚拟环境就是给每个项目建一个“独立小房间“,互不干扰。用 conda 管理这些环境,简单又省心。
让 Claude Code 帮你配置
打开 Claude Code,直接跟它说:
第一句:配置 conda 镜像源
帮我配置 conda 环境,把下载源换成清华镜像源
为啥要换?默认的国外源下载贼慢,换成国内镜像,速度飞起。
Claude 会自动帮你改配置文件,大概长这样:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
第二句:创建 Python 环境
帮我创建一个 Python 3.12 的虚拟环境,名字叫 py312
Claude 会执行类似这样的命令:
conda create -n py312 python=3.12 -y
等它跑完,你就有了一个干净的 Python 3.12 环境。
怎么用这个环境?
每次打开终端,敲一句就切换过去了:
conda activate py312
看到命令行前面出现 (py312) 就说明切换成功了。
想退出?敲:
conda deactivate
小技巧:让 Claude Code 自动激活
如果你懒得每次都敲 conda activate,跟 Claude 说:
帮我配置终端,让它每次启动自动激活 py312 环境
Claude 会帮你在 ~/.zshrc 里加一行,以后打开终端就自动进入 py312 环境,省事儿。
常用命令速查
| 想干嘛 | 敲这个 |
|---|---|
| 查看所有环境 | conda env list |
| 激活环境 | conda activate py312 |
| 退出环境 | conda deactivate |
| 删除环境 | conda remove -n py312 --all |
| 安装包 | pip install xxx |
遇到问题?
直接问 Claude Code:
conda activate 报错了,帮我看看怎么回事
把报错信息贴给它,它会帮你排查。
安装第一个 MCP 插件:Playwright
MCP 插件是 Claude Code 的“外挂技能“。装上 Playwright 这个插件,Claude 就能帮你操作浏览器了——打开网页、点按钮、截图、填表单,全都行。
MCP 插件去哪找?
逛逛这个网站:smithery.ai
这是个 MCP 插件商店,各种插件应有尽有。今天咱们装的 Playwright 在这:
怎么安装?
分两步:先配置 MCP 插件,再在本地装依赖包。缺一不可。
第一步:配置 MCP 插件
打开 Playwright MCP 插件页面,找到 Claude Code 选项卡。
你会看到两种配置方式:
- 本地配置(local):只在你这台电脑生效
- 云端配置(user):同步到你的账号,换电脑也能用
选一个,复制那串命令,粘贴到终端运行。
大概长这样:
claude mcp add playwright -s user -- npx -y @anthropic-ai/claude-code-mcp-server-playwright
⚠️ 注意:这步只是告诉 Claude “有这个插件可以用”,但插件要真正跑起来,还得装本地依赖。
第二步:本地安装 Playwright 包
MCP 配置好了,但 Playwright 本体还没装呢。打开终端,敲这两行:
装 Playwright 包:
npm install -g playwright
装浏览器(Playwright 需要一个浏览器来干活):
npx playwright install chromium
等它下载完,才算真正装好了。
为什么要装两次?
打个比方:
- 配置 MCP = 告诉 Claude:“你可以用 Playwright 这个技能”
- 本地装包 = 把 Playwright 这个工具真正装到你电脑上
两边都装好,Claude 才能调用 Playwright 帮你干活。
验证安装成功没
在 Claude Code 里敲:
/mcp
看到列表里有 playwright 就说明装好了。
怎么用?
装好之后,直接跟 Claude 说人话就行:
用 playwright 打开百度首页,截个图给我看看
用 playwright 访问 https://example.com,告诉我页面上有什么内容
用 playwright 打开淘宝,搜索"机械键盘"
Claude 会自动调用 Playwright 帮你操作浏览器,你坐着看就行。
实际应用场景
| 场景 | 怎么跟 Claude 说 |
|---|---|
| 截网页图 | “帮我截一下 xxx.com 的首页” |
| 抓取内容 | “打开这个网页,把文章内容提取出来” |
| 填写表单 | “帮我在这个页面的搜索框里输入 xxx” |
| 自动化测试 | “访问我的网站,检查登录功能正不正常” |
遇到问题?
浏览器打不开? 跟 Claude 说:
playwright 浏览器启动失败,帮我排查一下
插件没识别到? 重启一下 Claude Code,再敲 /mcp 看看。
如何设计需求:我的真实试错过程
-
在进行 Vibe Coding 之前,你会想一些基本的东西,例如:我怎么实现一个产品?
-
例如我想实现一个网站像 https://www.knowfun.io/ 一样,我需要实现哪些前端功能,哪些后端功能?
-
这篇文章不是给你“正确答案“,而是让你看到我真实的试错过程 —— 从失败到成功。
第一性原理思考:收集更多有效信息
怎么让 AI 帮你做好设计?—— 给它更多真实信息。
使用 web_search 尽可能挖掘信息,进入网页,使用截图,和大模型对话,告诉大模型你的场景、你的技术栈。
信息收集方法论
你可以给 AI 喂这些信息:
- 截图 —— 进入网页,截图给 AI 看,让它“看到“真实界面
- 抓包 —— 打开 DevTools,把网络请求发给 AI,让它知道接口长什么样
- 搜索 —— 用 web_search 查竞品、查资料,把结果喂给 AI
- 角色 —— 告诉 AI “你是产品经理”、“你是架构师”,让它换个视角思考
- 约束 —— 告诉 AI 你的技术栈,比如 “我用 Next.js + FastAPI”
- 差异 —— 告诉 AI 你和原产品的不同,比如 “我不是生成 PPT,是生成 HTML 动画”
- 文档 —— 把官方文档、设计规范喂给 AI,让它基于权威资料输出
背景:我想做什么
我想实现一个网站,类似 KnowFun(一个 AI 动画讲解生成平台)。
我需要搞清楚:
- 这个产品有哪些前端页面?
- 需要哪些后端接口?
- 数据库怎么设计?
第一步:先确定技术框架
在开始之前,我先确定了技术栈(这个不能让 AI 随便选):
前端: Next.js + Tailwind CSS + shadcn/ui + Supabase Auth 后端: FastAPI + PostgreSQL + SQLAlchemy 基础设施: Supabase(数据库 + 存储 + 认证)
第二步:让 AI 帮我生成需求文档(3次迭代)
方案一(V1):直接问 AI
我想实现一个 LLM 生成动画的系统,帮我生成技术框架和功能需求
❌ 问题: 没有给 AI 足够的背景信息,生成的内容太泛泛,不落地。
方案二(V2):加上角色和背景信息
你是一个资深产品经理,我想模仿 knowfun.io 这个产品,
帮我分析它的功能模块和技术架构...
❌ 问题: AI 没有真正“看过“这个产品,只是在瞎猜。生成的前端页面描述和实际产品差很远。
方案三(V3):用 Playwright 截图 + Manus[https://manus.im/] 分析
使用 Playwright 进行登录态截图,收集真实的产品信息,然后让 AI 分析。
✅ 结果: 终于得到了准确的需求文档!
方案四(V4):基于 V3 对话调整,适配自己的需求
V3 生成的是原产品的需求,但我的需求和原产品不完全一样:
| 原产品 (KnowFun) | 我的需求 |
|---|---|
| 生成 PPT/演示文稿 | 生成 HTML + GSAP 动画 |
| 导出为 PPT 文件 | 直接在网页预览/分享 |
| 多种演示风格 | 多种动画风格 |
V4 做法: 基于 V3 的文档,告诉 AI 我的差异点,让它帮我调整:
基于上面的需求文档,我需要做以下调整:
1. 我不是生成 PPT,而是生成 HTML + GSAP 动画代码
2. 用户输入内容后,LLM 直接生成可运行的 HTML 动画
3. 不需要导出功能,直接在网页 iframe 中预览
4. 请帮我调整相关的数据库设计和 API 接口
✅ 结果: 得到了符合我实际需求的定制化文档!
四种方案对比
| 对比项 | V1 直接问 | V2 加角色 | V3 截图分析 | V4 对话调整 |
|---|---|---|---|---|
| 输入 | 一句话 | 角色 + 产品名 | 真实截图 | V3 + 差异点 |
| AI 理解 | ❌ 瞎猜 | ❌ 半猜 | ✅ 真实数据 | ✅ 定制化 |
| 前端页面 | ❌ 不对 | ❌ 大概对 | ✅ 精确 | ✅ 符合我的需求 |
| 后端接口 | ❌ 泛泛 | ❌ 缺细节 | ✅ 有参数 | ✅ 适配我的技术栈 |
| 可用性 | 0% | 30% | 90% | 95% |
💡 核心教训:
- 让 AI 做需求分析,必须给它真实的产品数据
- 抄完之后要根据自己的需求调整,不能完全照搬
最终方案输出(V3 生成的文档)
KnowFun 产品设计文档
1. 产品概述
•
产品名称: KnowFun
•
产品定位: 一个AI驱动的革命性教育应用,旨在“让每个人的知识学习都毫不费力”。它将您的学习材料转化为个性化的多模态内容(如视频、PPT),以提供量身定制的学习体验。
•
目标用户群体: 从免费体验者到个人用户、专业用户和企业用户,覆盖不同需求的用户群体。
•
核心功能概述: AI驱动的课程/演示文稿生成、支持多种教学风格、实时问答与测试、文档/演示文稿管理、积分/存储空间管理。
•
技术栈:
•
前端框架: Next.js (基于React)
•
UI 组件库: 未明确识别,但从类名和HTML结构来看,可能是自定义组件或未被识别的库。
•
打包工具: Webpack (Next.js默认)
•
后端技术线索: Vercel (从响应头推断),API Host为 https://api.knowfun.io 。
2. 前端页面结构、交互与样式分析
2.0 整体视觉与样式分析
方面
描述
关键元素
整体风格
现代、简洁、扁平化设计,注重内容展示和功能性。采用深色模式(Dark Mode)和浅色模式(Light Mode)切换。
侧边栏导航、卡片式内容展示、居中布局。
配色方案
主色调: 紫色系(如 #8B5CF6 或更深的紫色)用于按钮、高亮和品牌元素。辅助色: 绿色系(如 #10B981)用于成功提示和功能强调。背景: 浅色模式下为白色/浅灰色,深色模式下为深灰色/黑色。
导航栏高亮、Submit 按钮、功能卡片边框。
字体
采用无衬线字体,如系统默认字体或 Tailwind CSS 默认字体(如 Inter),确保在不同设备上的可读性。
标题使用粗体,正文使用常规字重。
布局
采用左侧固定侧边栏(用于主要功能导航和用户状态展示),右侧主内容区的经典 Web 应用布局。内容区多采用卡片式布局,便于信息组织和视觉聚焦。
侧边栏、内容卡片、居中表单。
交互
按钮和链接有明显的悬停(Hover)和点击(Active)反馈。核心功能(如课程创建)采用分步引导或模态框进行操作。
提交按钮的动画、导航栏的选中状态。
2.1 页面列表梳理
2.1 页面列表梳理
页面路径
页面名称
页面功能
需要登录
/
首页
产品介绍、定价信息、引导注册/登录
❌
/learn/course-creation
课程创建页
核心功能入口,通过文本/文件/链接生成课程
✅
/learn/my-document
我的文档
用户上传文档列表管理
✅
/learn/my-courses
我的演示文稿
用户已生成课程/演示文稿列表管理
✅
/fun-square
Fun Square
用户分享和发现内容的社区
❌/✅
/pricing
定价页
详细展示不同套餐的定价和权益
❌
/referral
邀请页
邀请好友获取积分奖励
✅
/user
个人中心
账户信息、积分、订阅管理
✅
2.2 交互元素清单 (以课程创建页 /learn/course-creation 为例)
元素类型
位置
触发条件
交互行为
API 调用 (推断)
文本输入框
页面中央
输入问题/主题
准备生成内容
N/A
文件上传区
页面中央
拖拽或点击上传文件
上传文件到云存储
POST /api/document/upload
提交按钮
页面底部
点击"Submit"
触发课程生成流程
POST /api/course/create
侧边栏导航
页面左侧
点击链接
页面跳转
N/A
升级按钮
侧边栏
点击"Upgrade"
跳转到定价页或支付流程
N/A
3. 后端 API 接口逆向与认证分析
3.1 认证机制分析
•
认证方式: Clerk 身份验证服务。
•
实现细节: 登录后,浏览器Cookie中包含 __session 等JWT格式的Token。应用通过这些Token进行用户身份验证和授权。
•
Token 刷新机制: 由 Clerk 服务管理,应用层无需关心。
3.2 API 接口清单 (推断)
接口名称
HTTP 方法
请求路径 (推断)
请求参数 (推断)
响应结构 (推断)
认证方式
用户积分/存储信息
GET
/api/user/info
无
{ "credits": 500, "storage_used": 0, ... }
Bearer Token
文档上传
POST
/api/document/upload
file (FormData)
{ "document_id": "xxx", "url": "xxx" }
Bearer Token
文档列表
GET
/api/document/list
?page=1&limit=20
{ "data": [...], "total": 0 }
Bearer Token
课程/演示文稿列表
GET
/api/course/list
?page=1&limit=20
{ "data": [...], "total": 0 }
Bearer Token
课程/演示文稿创建
POST
/api/course/create
{ "input_type": "text", "text_input": "...", "style": "..." }
{ "task_id": "xxx", "status": "pending" }
Bearer Token
课程/演示文稿详情
GET
/api/course/:id
路径参数 id
{ "id": "xxx", "title": "...", "content": "..." }
Bearer Token
社区内容列表
GET
/api/square/content/list
?sort=hot&page=1&limit=20
{ "data": [...], "total": 0 }
无需认证
社区内容详情
GET
/api/square/content/:id
路径参数 id
{ "id": "xxx", "title": "...", "content": "..." }
无需认证
内容点赞
POST
/api/square/content/:id/like
{ "action": "like" }
{ "success": true, "likes": 1 }
Bearer Token
PPT/演示文稿导出
GET
/api/course/:id/export?format=ppt
路径参数 id,查询参数 format
文件流
Bearer Token
课程/演示文稿分享
POST
/api/course/:id/share
{ "public": true }
{ "share_url": "https://www.knowfun.io/share/xxx" }
Bearer Token
邀请规则
GET
/api/referral/rules
无
{ "refereePoints": 100, "referrerPoints": 500, ... }
无需认证
获取邀请码
GET
/api/referral/code
无
{ "code": "VP86D2", "link": "..." }
Bearer Token
4. 数据结构推断
4.1 数据模型梳理 (推断 )
User 表 (基于 Clerk 用户信息和应用数据)
Plain Text
User 表:
- id (VARCHAR, PRIMARY KEY) // Clerk User ID
- email (VARCHAR, UNIQUE)
- username (VARCHAR)
- credits (INT, DEFAULT 500)
- storage_limit (INT, DEFAULT 5) // GB
- storage_used (INT, DEFAULT 0) // MB
- created_at (DATETIME)
Document 表 (用户上传的文档)
Plain Text
Document 表:
- id (VARCHAR, PRIMARY KEY)
- user_id (VARCHAR, FOREIGN KEY -> User.id)
- title (VARCHAR)
- file_path (VARCHAR) // S3 或其他存储路径
- file_size (INT) // MB
- upload_date (DATETIME)
- status (VARCHAR) // e.g., 'uploaded', 'processing', 'ready'
Course/Presentation 表 (生成的课程/演示文稿)
Plain Text
Course 表:
- id (VARCHAR, PRIMARY KEY)
- user_id (VARCHAR, FOREIGN KEY -> User.id)
- title (VARCHAR)
- input_type (VARCHAR) // 'text', 'file', 'url'
- style (VARCHAR) // 'academic', 'humorous', etc.
- generation_status (VARCHAR) // 'pending', 'generating', 'completed', 'failed'
- created_at (DATETIME)
- last_modified (DATETIME)
- content_json (JSON/TEXT) // 存储演示文稿的结构化内容
4.2 关联关系分析
•
User 1:N Document: 一个用户可以上传多个文档。
•
User 1:N Course: 一个用户可以创建多个课程/演示文稿。
•
User 1:1 ReferralCode: 每个用户有一个唯一的邀请码。
5. 核心业务流程与页面跳转逻辑梳理
5.1 核心业务流程:课程生成流程 (Mermaid 流程图)
mermaid
graph TD
A[用户在 /learn/course-creation 输入主题/上传文件] --> B{点击 Submit 按钮}
B --> C[前端调用 POST /api/course/create]
C --> D{后端验证用户身份/积分/存储空间}
D --> E{验证通过?}
E -->|否| F[返回错误信息(积分不足/存储已满)]
E -->|是| G[创建 Course 记录 (status=pending)]
G --> H[返回 {task_id: "xxx"}]
H --> I[前端跳转到 /learn/my-courses 或任务详情页]
G --> J[异步:AI服务开始生成内容]
J --> K{生成完成?}
K -->|是| L[更新 Course 记录 (status=completed)]
K -->|否| M[更新 Course 记录 (status=failed)]
L --> N[通知用户 (Message Center)]
5.2 页面跳转逻辑
起始页
触发操作
目标页
携带参数
/ (首页)
点击 "Start For Free"
/learn/course-creation
N/A
/ (首页)
点击 "Pricing"
/pricing
N/A
/learn/course-creation
点击 "My Documents"
/learn/my-document
N/A
/learn/course-creation
点击 "My Presentations"
/learn/my-courses
N/A
/learn/my-courses
点击 课程卡片
/learn/course/:id
课程 ID
任意页
点击右上角头像
/user (个人中心)
N/A
6. 撰写产品设计文档及生成附加产物
6.1 文档结构模板 (已完成大部分内容)
6.2 附加产物
•
API 接口 Postman Collection:需要根据推断的API结构创建。
•
数据库 SQL 建表脚本:需要根据推断的表结构创建。
•
页面截图/流程图:需要进行截图和流程图生成。
•
技术评估报告:需要总结技术栈和风险。
7. 技术评估与风险分析
7.1 技术评估
方面
评估内容
优势
劣势/挑战
前端
Next.js (React)
性能优秀,支持SSR/SSG,利于SEO;生态成熟,组件化开发效率高。
学习曲线相对陡峭;部署成本高于纯静态网站。
后端
推测为Node.js/Go/Python微服务架构,API Host独立于主站。
架构灵活,可扩展性强;API Host独立有利于前后端分离和安全管理。
缺乏直接证据,推测存在不确定性。
认证
Clerk
专业的身份验证服务,提供开箱即用的用户管理功能,安全可靠。
引入第三方依赖,成本和控制权受限。
核心功能
AI驱动的课程生成
创新性强,符合市场趋势;用户体验好,降低内容创作门槛。
对AI模型的依赖性高;生成质量和成本是核心挑战。
7.2 风险分析
风险点
描述
应对策略
API 逆向风险
仅通过前端行为推断API,可能存在参数、请求头、业务逻辑上的偏差。
需通过实际抓包工具(如Charles/Fiddler)进行二次验证。
数据模型推断风险
数据库结构完全基于前端展示和API推断,可能与实际数据库结构不符。
仅作为参考设计,实际开发需根据业务需求和后端规范调整。
AI 成本风险
核心功能依赖AI模型,用户量增加可能导致成本快速上升。
引入积分/额度系统进行控制,并优化AI调用链以降低Token消耗。
流程图渲染失败
流程图渲染工具对中文支持不佳,导致无法生成图片。
在最终报告中提供原始Mermaid代码,并解释渲染失败原因。
8. 附加产物清单
1.
Postman Collection: knowfun_postman_collection.json
2.
数据库 SQL 建表脚本: knowfun_db_schema.sql
3.
核心业务流程图 (Mermaid Source): knowfun_course_creation_flow.md
4.
页面截图: 见附件 knowfun_io_2025-11-27_22-36-28_1424.webp (Fun Square 页面)
后端代码开发实战
让 Claude Code 帮你写后端,不是一句“帮我写个后端“就完事了。得有节奏、有步骤,一步步来才不会乱。
技术栈
先跟 Claude 说清楚你用啥:
- 后端框架: FastAPI
- 数据库: PostgreSQL + SQLAlchemy
- 基础设施: Supabase(数据库 + 文件存储 + 用户认证)
开发流程
第一阶段:打地基
1. 把需求文档甩给 Claude
@需求文档.md 这是我的需求文档,技术栈是 FastAPI + PostgreSQL + Supabase,帮我理解一下要做哪些功能
让它先理解你要做啥,别急着写代码。
2. 配置 Supabase 连接
跟 Claude 说:
帮我配置 Supabase 的数据库连接,我需要:
- 数据库连接(PostgreSQL)
- 文件存储(Storage)
- 用户认证(Auth)
把需要的 key 都配置好
这步搞定,后面才能跑得动。
3. 跑通文件上传
帮我写一个文件上传的接口,上传到 Supabase Storage,测试一下能不能跑通
先验证基础设施没问题。
第二阶段:跑通核心链路
4. 测试 LLM 调用
帮我写一个测试接口,调用大模型 API,验证连接是否正常
能调通大模型,后面的 AI 功能才有戏。
5. 写一个最小 MVP
帮我写一个最简单的 demo:用户输入提示词 → 调用 LLM → 生成 HTML + GSAP 动画 → 返回结果
这步很关键——先跑通最核心的链路,证明技术路线可行。
第三阶段:正式开发
6. 让 Claude 设计 API 结构
根据需求文档,帮我设计后端的 API 接口结构,列出每个模块需要哪些接口
先规划,再动手。
7. 一个模块一个模块写
别一口气让它写完所有代码。按模块来:
先帮我写用户模块:注册、登录、获取用户信息
用户模块写完了,接下来写动画生成模块
8. 每个模块写完立刻测试
帮我写几个测试用例,验证用户注册登录功能是否正常
写一个测一个,别攒着。
第四阶段:联调验收
9. 模拟完整用户流程
模拟一个用户的完整流程:注册账号 → 登录 → 创建动画 → 查看结果,帮我走一遍看看有没有问题
10. 发现问题就贴给 Claude
这个接口报错了:[贴报错信息],帮我看看怎么回事
11. 循环修 bug 直到顺畅
重复第 9-10 步,直到整个流程跑通没毛病。
小贴士
| 场景 | 怎么跟 Claude 说 |
|---|---|
| 代码报错 | “这段代码报错了:[报错信息],帮我修” |
| 功能不对 | “这个接口返回的数据格式不对,应该是 xxx” |
| 想加功能 | “在用户模块加一个修改密码的接口” |
| 想优化 | “这个查询太慢了,帮我优化一下” |
核心原则
- 先跑通再完善 — MVP 能跑了再加功能
- 一个模块一个模块来 — 别贪多,稳扎稳打
- 写完就测 — 别攒一堆再测,到时候 bug 连环爆
- 有问题就问 — Claude 不怕你问多,就怕你不说清楚
前端代码开发实战
前端开发的核心流程:喂材料给 Claude → 批量生成代码 → 用 Playwright 访问测试 → 发现问题就修 → 循环。
准备材料
开工之前,先把这些东西准备好:
| 材料 | 说明 |
|---|---|
| 需求文档 | 写清楚要做哪些页面、每个页面有啥功能 |
| 后端代码 | 让 Claude 知道有哪些接口可以调 |
| 设计截图 | 页面长啥样,截图比文字描述清楚一万倍 |
开发流程
第一步:把材料喂给 Claude
一次性把上下文给足:
@需求文档.md 这是需求文档
@backend/ 这是后端代码,里面有 API 接口定义
@设计图.png 这是设计稿截图
技术栈:Next.js 14 + Tailwind CSS + shadcn/ui
帮我批量生成前端页面代码
Claude 会根据这些材料,理解你要做啥,然后开始写代码。
第二步:批量生成页面
让 Claude 一口气把页面都写出来:
根据需求文档和设计图,帮我生成以下页面:
1. 首页
2. 登录页
3. 注册页
4. 工作台页面
5. 个人中心页面
每个页面都要对接后端接口
Claude 会批量生成代码,一个页面一个页面写好。
第三步:用 Playwright 访问测试
代码写完了,别急着自己点,让 Playwright 帮你测:
用 playwright 访问 http://localhost:3000,截图给我看看首页效果
用 playwright 访问登录页,帮我检查页面有没有报错
用 playwright 在登录页输入用户名 test,密码 123456,点击登录按钮,看看会发生什么
第四步:发现问题就修
Playwright 测试过程中发现问题,直接贴给 Claude:
页面报错了:
playwright 访问这个页面报错了:[贴报错信息],帮我修
样式不对:
这个页面的布局跟设计图不一样,@设计图.png 帮我调成这样
功能不对:
点击登录按钮没反应,帮我看看哪里出问题了
接口对不上:
这个接口调用失败了,返回 404,帮我检查一下是不是地址写错了
第五步:循环测试直到通过
测试流程
├── 用 playwright 访问页面
├── 发现问题 → 让 Claude 修
├── 修完再用 playwright 测
└── 重复,直到所有页面都正常
实战示例
例子:测试登录功能
第一轮:访问页面
用 playwright 访问 http://localhost:3000/login,截图看看
发现问题:样式乱了
这个登录页样式不对,表单应该居中显示,帮我修
第二轮:测试交互
用 playwright 在登录页的用户名输入框输入 test@example.com,密码输入 password123,然后点击登录按钮
发现问题:接口报错
点击登录后控制台报错 401 Unauthorized,帮我看看是不是接口地址或参数有问题
第三轮:验证修复
再用 playwright 测一遍登录流程,看看修好没
常用 Playwright 测试命令
| 想干嘛 | 怎么跟 Claude 说 |
|---|---|
| 看页面效果 | 用 playwright 访问 xxx 页面,截图给我 |
| 检查报错 | 用 playwright 访问这个页面,看看控制台有没有报错 |
| 填写表单 | 用 playwright 在输入框里填入 xxx,然后点击提交 |
| 点击操作 | 用 playwright 点击页面上的 xxx 按钮 |
| 验证跳转 | 用 playwright 点击登录后,看看有没有跳转到首页 |
| 检查元素 | 用 playwright 检查页面上有没有显示 xxx 文字 |
核心原则
- 材料给足 - 需求文档 + 后端代码 + 设计截图,一次性喂给 Claude
- 批量生成 - 让 Claude 一口气写多个页面,效率高
- Playwright 验证 - 别自己手动点,让 Playwright 帮你测
- 发现就修 - 测出问题立刻让 Claude 修,别攒着
- 循环到位 - 测试 → 修复 → 再测试,直到全部通过
优化加速的点: 截图信息, 重建一个脚本 进行调试启动前端和后端,避免端口冲突
一条龙上线部署
代码写完了,怎么让全世界都能访问?这篇教你用 Vercel + Railway + Cloudflare 三件套,把前后端都部署上线。
架构说明
| 组件 | 平台 | 说明 |
|---|---|---|
| 前端 | Vercel | Next.js 部署首选,零配置,推送即部署 |
| 后端 | Railway | FastAPI + PostgreSQL,一键部署,自带数据库 |
| 域名 | Cloudflare | 免费 CDN + SSL + 域名管理 |
这套组合的好处:免费额度够用、部署简单、全球访问快。
第一步:部署后端到 Railway
先把后端搞定,前端才有接口可调。
1. 注册 Railway
访问 railway.app,用 GitHub 账号登录。
2. 创建项目
两种方式,选一个:
方式一:用模板(推荐新手)
访问 FastAPI + PostgreSQL 模板,点击 Deploy,一键部署。
方式二:连 GitHub 仓库
1. Railway 控制台 → New Project → Deploy from GitHub repo
2. 选你的后端仓库
3. Railway 自动识别 FastAPI,开始部署
3. 添加 PostgreSQL 数据库
1. 项目页面 → New → Database → PostgreSQL
2. 等它创建好,点进去看 Variables 标签
3. 复制 DATABASE_URL,等下要用
4. 配置环境变量
点击你的 FastAPI 服务 → Variables,添加这些:
DATABASE_URL=postgresql://... (从 PostgreSQL 服务复制)
SECRET_KEY=你的密钥(随便生成一个长字符串)
SUPABASE_URL=你的 Supabase 地址(如果用了的话)
SUPABASE_KEY=你的 Supabase Key
5. 获取后端地址
部署成功后,Railway 会给你一个地址,类似:
https://your-app.up.railway.app
记住这个地址,前端要用。
第二步:部署前端到 Vercel
1. 注册 Vercel
访问 vercel.com,用 GitHub 账号登录。
2. 导入项目
1. 控制台 → Add New → Project
2. 选择你的前端 GitHub 仓库
3. Vercel 自动识别 Next.js
4. 点 Deploy
3. 配置环境变量
部署前,先配好环境变量:
Settings → Environment Variables,添加:
NEXT_PUBLIC_API_URL=https://your-app.up.railway.app (你的后端地址)
NEXT_PUBLIC_SUPABASE_URL=你的 Supabase 地址
NEXT_PUBLIC_SUPABASE_ANON_KEY=你的 Supabase Key
注意:前端环境变量要以
NEXT_PUBLIC_开头,不然客户端拿不到。
4. 重新部署
改完环境变量后,需要重新部署才生效:
Deployments → 点最新的那个 → Redeploy
第三步:配置 Cloudflare 域名
1. 注册 Cloudflare
访问 cloudflare.com,注册账号。
2. 添加域名
1. Add a Site → 输入你的域名
2. 选 Free 计划
3. Cloudflare 会给你两个 nameserver 地址
4. 去你的域名注册商(阿里云/腾讯云/GoDaddy),把 DNS 服务器改成 Cloudflare 给的
3. 配置前端域名(Vercel)
Vercel 控制台 → 你的项目 → Settings → Domains
添加你的域名,比如:www.yourdomain.com
Vercel 会告诉你需要添加的 DNS 记录,去 Cloudflare 添加:
类型:CNAME
名称:www
内容:cname.vercel-dns.com
4. 配置后端域名(Railway)
Railway 默认给你的地址是 xxx.up.railway.app,生产环境最好换成自己的域名。
第一步:在 Railway 添加自定义域名
1. Railway 控制台 → 点击你的 FastAPI 服务
2. Settings → Networking → Custom Domain
3. 点击 "Add Custom Domain"
4. 输入你的子域名:api.yourdomain.com
5. Railway 会显示需要配置的 CNAME 记录值,类似:xxx.railway.app
第二步:在 Cloudflare 添加 DNS 记录
1. Cloudflare 控制台 → DNS → Records → Add record
2. 类型:CNAME
3. 名称:api(这样最终域名就是 api.yourdomain.com)
4. 目标:粘贴 Railway 给你的那个地址
5. 代理状态:先关掉(灰色云朵),等验证通过再开
6. 点击保存
第三步:等待验证
回到 Railway,等几分钟,状态会从 "Pending" 变成 "Active"
验证通过后,就可以用 https://api.yourdomain.com 访问后端了
第四步:更新前端的 API 地址
域名配好后,记得把前端的环境变量改成新域名:
Vercel → Settings → Environment Variables
把 NEXT_PUBLIC_API_URL 改成 https://api.yourdomain.com
然后重新部署
5. 开启 SSL
Cloudflare 默认开启 SSL,确保设置是:
SSL/TLS → Overview → Full (strict)
第四步:解决 CORS 跨域问题
这是最容易踩的坑!前端 www.yourdomain.com 调用后端 api.yourdomain.com,浏览器会拦截。
后端配置(FastAPI)
在 main.py 里加上:
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=[
"https://www.yourdomain.com",
"https://yourdomain.com",
"http://localhost:3000", # 本地开发
],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
前端配置(Next.js)
如果后端配了还不行,可以在 next.config.js 加个代理:
module.exports = {
async rewrites() {
return [
{
source: '/api/:path*',
destination: 'https://api.yourdomain.com/:path*',
},
]
},
}
Vercel 配置
在项目根目录创建 vercel.json:
{
"headers": [
{
"source": "/api/(.*)",
"headers": [
{ "key": "Access-Control-Allow-Credentials", "value": "true" },
{ "key": "Access-Control-Allow-Origin", "value": "*" },
{ "key": "Access-Control-Allow-Methods", "value": "GET,POST,PUT,DELETE,OPTIONS" },
{ "key": "Access-Control-Allow-Headers", "value": "Content-Type, Authorization" }
]
}
]
}
第五步:用 Playwright 调试线上环境
部署完了,让 Claude 帮你测一遍:
测试前端页面
用 playwright 访问 https://www.yourdomain.com,截图看看首页效果
测试后端接口
用 playwright 访问 https://api.yourdomain.com/docs,看看 FastAPI 文档页面能不能打开
测试完整流程
用 playwright 访问我的网站 https://www.yourdomain.com,执行以下操作:
1. 点击注册按钮
2. 填写邮箱和密码
3. 点击提交
4. 看看有没有报错
检查控制台错误
用 playwright 访问首页,帮我看看控制台有没有 CORS 错误或者其他报错
常见问题排查
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 前端白屏 | 环境变量没配对 | 检查 NEXT_PUBLIC_ 开头的变量 |
| 接口 404 | 后端地址写错了 | 检查 API_URL 配置 |
| CORS 错误 | 跨域没配好 | 后端加 CORSMiddleware |
| 数据库连接失败 | DATABASE_URL 没配 | Railway 里复制正确的连接串 |
| SSL 证书错误 | Cloudflare 设置问题 | SSL 模式改成 Full (strict) |
| Supabase 连不上 | IPv6 不兼容 | 用 Pooler 连接串(见下方) |
Supabase IPv6 连接问题(重要!)
从 2024 年开始,Supabase 新项目默认只支持 IPv6,但很多部署平台(包括 Railway)不支持 IPv6 直连,会报错:
connection to server failed: Connection refused
解决方案:使用 Pooler 连接串
第一步:找到 Pooler 连接串
1. 登录 Supabase 控制台
2. 进入你的项目 → Settings → Database
3. 找到 "Connection string" 部分
4. 选择 "Mode: Session" 或 "Mode: Transaction"
5. 复制 Pooler 连接串(不是直连的那个!)
两种连接串对比:
❌ 直连(IPv6,可能连不上):
postgres://postgres:[密码]@db.xxxx.supabase.co:5432/postgres
✅ Pooler 连接(IPv4 兼容,推荐):
postgres://postgres.xxxx:[密码]@aws-0-us-east-1.pooler.supabase.com:6543/postgres
注意看区别:
- 用户名从
postgres变成postgres.xxxx(带项目 ID) - 域名从
db.xxxx.supabase.co变成pooler.supabase.com - 端口从
5432变成6543(或用5432走 Session 模式)
第二步:更新 Railway 环境变量
Railway → 你的服务 → Variables
把 DATABASE_URL 改成 Pooler 连接串
重新部署
其他方案
如果 Pooler 还是不行,还有两个选择:
- 买 IPv4 附加组件:Supabase Pro 计划可以花 $4/月 买专用 IPv4 地址
- 用 Railway 自带的 PostgreSQL:Railway 自己的数据库没有 IPv6 问题
验证连接
部署后让 Claude 帮你测:
用 playwright 访问 https://api.yourdomain.com/docs,看看 FastAPI 能不能正常启动,有没有数据库连接错误
环境变量清单
Railway(后端)
DATABASE_URL=postgresql://...
SECRET_KEY=随机字符串
SUPABASE_URL=https://xxx.supabase.co
SUPABASE_KEY=eyJxxx...
Vercel(前端)
NEXT_PUBLIC_API_URL=https://api.yourdomain.com
NEXT_PUBLIC_SUPABASE_URL=https://xxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJxxx...
部署完成检查清单
[ ] Railway 后端部署成功,能访问 /docs 页面
[ ] Vercel 前端部署成功,能打开首页
[ ] Cloudflare 域名解析生效
[ ] HTTPS 正常工作
[ ] CORS 跨域问题解决
[ ] 前端能正常调用后端接口
[ ] 用 Playwright 走一遍完整用户流程
参考链接
名词手册
遇到不懂的词?来这里查。按字母和拼音排序,方便找。
A
API(接口)
全称 Application Programming Interface。简单说就是“程序之间说话的方式“。
比如:前端要获取用户信息,就调用后端的 /api/user 接口,后端把数据返回给前端。
API Key(密钥)
一串字符,用来证明“我有权限用这个服务“。
类似于:进小区要刷门禁卡,调用 API 要带上 API Key。
C
Claude Code
Anthropic 公司出的 AI 编程助手,能帮你写代码、改 bug、做测试。
你跟它说人话,它帮你写代码。本教程的核心工具。
Cloudflare
一家提供 CDN、域名管理、SSL 证书的公司。
用它来:管理域名、加速网站访问、提供免费 HTTPS。
CORS(跨域)
全称 Cross-Origin Resource Sharing。浏览器的安全机制。
当前端(www.xxx.com)调用后端(api.xxx.com)时,浏览器会拦截,需要后端配置允许才能访问。
报错长这样:Access to fetch at 'xxx' from origin 'xxx' has been blocked by CORS policy
D
Database(数据库)
存数据的地方。用户信息、文章内容、订单记录,都存在数据库里。
常见的:MySQL、PostgreSQL、MongoDB、SQLite。
Docker
一个打包工具,把代码和运行环境打包在一起,在哪儿都能跑。
类似于:把整个电脑装进箱子,搬到哪儿插上电就能用。
E
ENV / 环境变量
存放配置信息的地方,比如数据库地址、API 密钥。
通常放在 .env 文件里,不会上传到 GitHub(防止泄露)。
F
FastAPI
Python 写的后端框架,用来写 API 接口。
特点:快、简单、自动生成文档。本教程后端用的就是它。
Frontend(前端)
用户能看到的部分:网页、按钮、输入框、动画效果。
技术:HTML、CSS、JavaScript、React、Vue、Next.js 等。
G
Git
代码版本管理工具。能记录代码的每次修改,方便回退和协作。
GitHub
代码托管平台,把代码存在云上。Vercel、Railway 都能从 GitHub 拉取代码自动部署。
H
HTTP / HTTPS
网页传输协议。HTTPS 是加密版,更安全。
现在网站基本都要用 HTTPS,浏览器会提示“不安全“如果没有。
I
IPv4 / IPv6
IP 地址的两种格式。
- IPv4:
192.168.1.1(数字用点分开,快用完了) - IPv6:
2001:0db8:85a3:0000:0000:8a2e:0370:7334(更长,够用)
Supabase 2024 年开始默认用 IPv6,有些平台连不上,要用 Pooler 连接。
J
JSON
一种数据格式,长这样:
{
"name": "张三",
"age": 25
}
前后端传数据基本都用 JSON 格式。
M
MCP(插件)
全称 Model Context Protocol。Claude Code 的插件系统。
装上 MCP 插件,Claude 就能获得新技能。比如装 Playwright MCP,Claude 就能操作浏览器。
Middleware(中间件)
请求到达最终处理之前,经过的“中转站“。
比如:检查用户有没有登录、记录日志、处理跨域,都可以用中间件。
N
Next.js
React 的全栈框架,能写前端也能写后端。
特点:服务端渲染、自动路由、部署方便。本教程前端用的就是它。
npm
Node.js 的包管理器,用来安装 JavaScript 的库。
npm install xxx = 安装 xxx 这个包。
P
Playwright
浏览器自动化工具,能用代码控制浏览器。
用途:自动化测试、爬虫、截图。配合 Claude,让 AI 帮你操作浏览器。
PostgreSQL
一种关系型数据库,开源免费,功能强大。
Supabase 底层用的就是 PostgreSQL。
Pooler(连接池)
数据库连接的“中转站“,复用连接,提高效率。
Supabase 的 Pooler 连接还能解决 IPv6 兼容问题。
R
Railway
后端部署平台,能一键部署 FastAPI、Node.js 等应用,还自带数据库。
特点:免费额度、零配置、支持 Docker。
React
Facebook 出的前端框架,用来构建用户界面。
组件化开发,现在最流行的前端框架之一。
S
SSL / TLS
加密协议,让网站支持 HTTPS。
Cloudflare 提供免费 SSL 证书。
Supabase
开源的 Firebase 替代品,提供数据库、文件存储、用户认证。
特点:免费额度大方、功能全、基于 PostgreSQL。
T
Tailwind CSS
CSS 框架,用类名直接写样式。
<div class="bg-blue-500 text-white p-4 rounded">
蓝色背景、白色文字、内边距、圆角
</div>
不用写 CSS 文件,直接在 HTML 里加类名。
Terminal(终端)
输入命令的地方,黑底白字那个窗口。
在这里敲命令,让电脑执行各种操作。
U
URL
网址。https://www.example.com/path?query=1
https://协议www.example.com域名/path路径?query=1参数
V
Vercel
前端部署平台,Next.js 的亲儿子(同一家公司)。
特点:推送代码自动部署、全球 CDN、免费额度够用。
虚拟环境
Python 的隔离机制,每个项目用自己的依赖,互不干扰。
类似于:给每个项目建一个独立的“小房间“。
常见报错速查
| 报错关键词 | 可能原因 | 解决方向 |
|---|---|---|
| CORS | 跨域问题 | 后端加 CORSMiddleware |
| 404 | 地址不对 | 检查 URL 有没有写错 |
| 401 | 没权限 | 检查 API Key 或登录状态 |
| 500 | 服务器内部错误 | 看后端日志,找具体报错 |
| Connection refused | 连不上 | 检查地址、端口、IPv6 问题 |
| Module not found | 包没装 | npm install 或 pip install |
XiaZheStudy 功能解读
这是一个 AI 驱动的学习平台,核心功能是:上传文档或输入文字 → AI 自动生成动画讲解。
项目定位
一句话介绍: 让复杂的知识像动画一样生动。
解决什么问题:
- 看文档太枯燥,看不进去
- 知识点复杂,难以理解
- 想要更直观的学习方式
怎么解决:
- 上传文档(PDF/Word/PPT)
- AI 分析内容,生成动画脚本
- 输出可交互的动画讲解
核心功能模块
1. 用户系统
| 功能 | 说明 |
|---|---|
| 注册登录 | 支持邮箱注册 + Google OAuth |
| 用户中心 | 查看个人信息、订阅状态、积分余额 |
| 订阅套餐 | free / basic / plus / pro 四档 |
| 积分系统 | 新用户送 500 积分,用于生成动画 |
| 邀请系统 | 邀请好友注册,双方都得积分奖励 |
2. 文档管理
| 功能 | 说明 |
|---|---|
| 上传文档 | 支持 PDF、Word、PPT 等格式 |
| 文档解析 | 后端自动提取文档文本内容 |
| 文档列表 | 查看、删除已上传的文档 |
| 存储管理 | 文件存储在 Supabase Storage |
3. 课程/动画生成(核心功能)
这是整个产品的核心:
用户输入(文档/文字)
↓
AI 分析内容
↓
生成动画脚本(HTML + GSAP)
↓
实时流式输出
↓
用户预览动画
↓
保存为课程
支持的输入方式:
- 上传文档 → 解析文本 → 生成动画
- 直接输入文字 → 生成动画
生成选项:
- 风格:标准、幽默、学术、科幻等
- 难度:简单、中等、困难
状态流转:
pending(排队中)→ processing(生成中)→ completed(完成)
↘ failed(失败)
4. 课程广场(Fun Square)
| 功能 | 说明 |
|---|---|
| 公开课程 | 用户可以把自己的课程设为公开 |
| 浏览发现 | 查看其他用户分享的优质动画 |
| 点赞收藏 | 给喜欢的课程点赞 |
| 播放统计 | 记录播放次数 |
5. 导出功能
| 功能 | 说明 |
|---|---|
| 导出视频 | 把动画导出为 MP4 视频文件 |
| 导出图片 | 导出为图片序列 |
| 任务队列 | 导出是异步任务,后台处理 |
6. 站内信系统
| 功能 | 说明 |
|---|---|
| 系统通知 | 积分变动、订阅到期等通知 |
| 消息列表 | 查看历史消息 |
| 已读未读 | 标记消息状态 |
用户使用流程
流程一:文档生成动画
1. 用户注册/登录
2. 进入「我的文档」页面
3. 上传一个 PDF 文件
4. 点击「生成动画」
5. 选择风格和难度
6. 等待 AI 生成(流式输出,实时可见)
7. 预览生成的动画
8. 保存到「我的课程」
9. (可选)设为公开,分享到广场
流程二:文字生成动画
1. 进入「创作课程」页面
2. 直接输入主题或内容
3. 选择风格和难度
4. AI 实时生成动画
5. 预览、保存、分享
流程三:邀请好友
1. 进入「邀请好友」页面
2. 复制自己的邀请链接
3. 分享给朋友
4. 朋友通过链接注册
5. 双方各得积分奖励
技术栈概览
| 层级 | 技术 |
|---|---|
| 前端 | Next.js 14 + Tailwind CSS + shadcn/ui |
| 后端 | FastAPI + SQLAlchemy |
| 数据库 | PostgreSQL (Supabase) |
| 存储 | Supabase Storage |
| 认证 | Supabase Auth (支持 Google OAuth) |
| AI | 大语言模型 API(流式输出) |
| 部署 | Vercel (前端) + Railway (后端) |
| 域名 | Cloudflare |
数据模型概览
User(用户)
├── Documents(文档)
├── Courses(课程/动画)
├── Posts(广场帖子)
├── Wallet(钱包/积分)
├── CreditTransactions(积分记录)
├── Invitations(邀请记录)
└── Messages(站内信)
Course(课程)
├── status: pending/processing/completed/failed
├── content: JSON(动画内容)
├── style: 风格
├── difficulty: 难度
└── is_public: 是否公开
Document(文档)
├── file_url: 存储地址
├── file_type: 文件类型
└── file_size: 文件大小
商业模式
| 套餐 | 价格 | 权益 |
|---|---|---|
| Free | 免费 | 500 积分,基础功能 |
| Basic | ¥xx/月 | 更多积分,更多存储 |
| Plus | ¥xx/月 | 高级功能,优先生成 |
| Pro | ¥xx/月 | 无限制,API 访问 |
积分消耗:
- 生成一个动画消耗 xx 积分
- 导出视频消耗 xx 积分
获取积分:
- 新用户注册送 500 积分
- 邀请好友各得 xx 积分
- 充值购买
小结
XiaZheStudy 是一个典型的 AI 内容生成平台:
- 输入 → 文档/文字
- 处理 → AI 分析 + 动画生成
- 输出 → 可交互的动画讲解
- 社交 → 分享到广场,点赞互动
- 变现 → 订阅 + 积分
技术上是标准的全栈架构,适合学习参考。
XiaZheStudy 后端解读
后端用 FastAPI 写的,标准的三层架构:Router → Service → Model。看完这篇,你就知道后端代码是怎么组织的。
技术栈
| 组件 | 技术 | 说明 |
|---|---|---|
| 框架 | FastAPI | Python 异步 Web 框架 |
| ORM | SQLAlchemy 2.0 | 异步 ORM,操作数据库 |
| 数据库 | PostgreSQL | 通过 Supabase 托管 |
| 存储 | Supabase Storage | 文件存储 |
| 认证 | Supabase Auth | 用户认证,支持 OAuth |
| 迁移 | Alembic | 数据库迁移工具 |
目录结构
backend/
├── app/
│ ├── main.py # 入口文件,FastAPI 实例
│ ├── api/
│ │ └── v1/
│ │ ├── __init__.py # 路由注册
│ │ └── endpoints/ # 各个接口模块
│ │ ├── auth.py # 认证相关
│ │ ├── users.py # 用户管理
│ │ ├── documents.py # 文档管理
│ │ ├── courses.py # 课程管理
│ │ ├── ai.py # AI 生成
│ │ ├── posts.py # 广场帖子
│ │ ├── referrals.py # 邀请系统
│ │ ├── messages.py # 站内信
│ │ ├── export_tasks.py # 导出任务
│ │ ├── upload.py # 文件上传
│ │ └── activation_codes.py # 激活码
│ ├── core/
│ │ ├── config.py # 配置管理
│ │ ├── supabase_db.py # 数据库连接
│ │ ├── dependencies.py # 依赖注入
│ │ └── storage_init.py # 存储初始化
│ ├── models/ # 数据模型(SQLAlchemy)
│ │ ├── user.py
│ │ ├── document.py
│ │ ├── course.py
│ │ ├── post.py
│ │ └── ...
│ ├── schemas/ # Pydantic 模型(请求/响应)
│ ├── services/ # 业务逻辑层
│ │ ├── ai_service.py
│ │ └── document_parser.py
│ └── utils/ # 工具函数
├── alembic/ # 数据库迁移
├── requirements.txt # 依赖包
├── Dockerfile # Docker 配置
└── .env # 环境变量
核心文件解读
1. main.py - 入口文件
# 创建 FastAPI 实例
app = FastAPI(
title=settings.APP_NAME,
version=settings.APP_VERSION,
lifespan=lifespan, # 生命周期管理
)
# 配置 CORS(跨域)
app.add_middleware(
CORSMiddleware,
allow_origins=settings.cors_origins_list,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(api_router, prefix="/api/v1")
关键点:
lifespan管理启动和关闭时的操作(连接数据库、初始化存储)- CORS 配置允许前端跨域访问
- 所有 API 都在
/api/v1前缀下
2. 路由注册 - api/v1/init.py
api_router = APIRouter()
# 注册各个模块的路由
api_router.include_router(auth.router, prefix="/auth", tags=["auth"])
api_router.include_router(users.router, prefix="/users", tags=["users"])
api_router.include_router(documents.router, prefix="/documents", tags=["documents"])
api_router.include_router(courses.router, prefix="/courses", tags=["courses"])
api_router.include_router(ai.router, prefix="/ai", tags=["ai"])
# ...
最终 API 路径:
/api/v1/auth/login- 登录/api/v1/users/me- 获取当前用户/api/v1/documents- 文档列表/api/v1/courses- 课程列表/api/v1/ai/generate/text- AI 生成
数据模型解读
User 模型
class User(Base):
__tablename__ = "users"
id: Mapped[int] # 主键
supabase_user_id: Mapped[str] # Supabase Auth ID
email: Mapped[str] # 邮箱
username: Mapped[str] # 用户名
avatar_url: Mapped[Optional[str]] # 头像
# 订阅相关
subscription_tier: Mapped[str] # free/basic/plus/pro
points_balance: Mapped[int] # 积分余额(默认 500)
# 邀请系统
referral_code: Mapped[str] # 我的邀请码
referred_by_id: Mapped[int] # 谁邀请了我
# Stripe 集成
stripe_customer_id: Mapped[str] # Stripe 客户 ID
# 关联关系
documents: Mapped[List["Document"]]
courses: Mapped[List["Course"]]
wallet: Mapped["UserWallet"]
Course 模型
class Course(Base):
__tablename__ = "courses"
id: Mapped[int]
user_id: Mapped[int] # 所属用户
document_id: Mapped[Optional[int]] # 关联文档(可选)
# 课程信息
title: Mapped[str] # 标题
description: Mapped[str] # 描述
cover_image: Mapped[str] # 封面图
# 生成配置
style: Mapped[str] # 风格:standard/humorous/academic
difficulty: Mapped[str] # 难度:easy/medium/hard
# 内容
content: Mapped[dict] # JSON 格式的动画内容
# 统计
views_count: Mapped[int] # 播放次数
likes_count: Mapped[int] # 点赞数
# 状态
status: Mapped[str] # pending/processing/completed/failed
is_public: Mapped[bool] # 是否公开
API 接口解读
AI 生成接口(核心)
@router.post("/generate/document")
async def generate_from_document(
request: Request,
gen_request: GenerateFromDocumentRequest,
current_user: User = Depends(get_current_user),
db: AsyncSession = Depends(get_db)
):
# 1. 获取文档
document = await db.execute(
select(Document).where(
Document.id == gen_request.document_id,
Document.user_id == current_user.id
)
)
# 2. 解析文档内容
content = await document_parser.parse_from_storage(document.file_url)
# 3. 流式生成动画
async def event_generator():
async for chunk in ai_service.generate_course_content_stream(
content=content,
style=gen_request.style,
difficulty=gen_request.difficulty
):
yield chunk
# 4. 返回 SSE 流
return StreamingResponse(event_generator(), headers={
"Content-Type": "text/event-stream"
})
关键点:
Depends(get_current_user)- 依赖注入,自动验证用户身份Depends(get_db)- 依赖注入,获取数据库会话StreamingResponse- 流式响应,实时输出 AI 生成的内容- SSE (Server-Sent Events) - 服务端推送,前端实时接收
依赖注入示例
# core/dependencies.py
async def get_current_user(
request: Request,
db: AsyncSession = Depends(get_db)
) -> User:
# 从请求头获取 token
token = request.headers.get("Authorization")
if not token:
raise HTTPException(status_code=401, detail="Not authenticated")
# 验证 token,获取用户
user = await verify_token_and_get_user(token, db)
return user
async def get_db():
async with AsyncSession(engine) as session:
yield session
业务流程解读
文档上传流程
1. 前端调用 POST /api/v1/upload
2. 后端接收文件
3. 上传到 Supabase Storage
4. 创建 Document 记录
5. 返回文档信息
AI 生成流程
1. 前端调用 POST /api/v1/ai/generate/document
2. 后端验证用户身份
3. 获取文档,解析内容
4. 调用 AI 服务,流式生成
5. SSE 实时推送到前端
6. 前端渲染动画
7. 用户确认后保存为 Course
课程保存流程
1. 前端调用 POST /api/v1/courses
2. 后端创建 Course 记录
3. 保存动画内容(JSON)
4. 返回课程 ID
关键配置
环境变量
# 数据库(使用 Pooler 连接,避免 IPv6 问题)
DATABASE_URL=postgresql+asyncpg://postgres.xxx:password@aws-0-us-west-2.pooler.supabase.com:5432/postgres
# Supabase
SUPABASE_URL=https://xxx.supabase.co
SUPABASE_KEY=eyJxxx...
SUPABASE_SERVICE_KEY=eyJxxx...
# CORS
CORS_ORIGINS=https://www.xiazhestudy.com,https://xiazhestudy.com
# JWT
SECRET_KEY=your-secret-key
# AI 服务
AI_API_KEY=your-ai-api-key
CORS 配置
app.add_middleware(
CORSMiddleware,
allow_origins=settings.cors_origins_list, # 允许的前端域名
allow_credentials=True, # 允许携带 cookie
allow_methods=["*"], # 允许所有 HTTP 方法
allow_headers=["*"], # 允许所有请求头
)
代码规范总结
目录组织
endpoints/ - 接口定义(薄,只做请求处理)
services/ - 业务逻辑(厚,核心逻辑在这)
models/ - 数据模型(ORM 定义)
schemas/ - 请求响应模型(Pydantic)
core/ - 核心配置(数据库、依赖注入)
utils/ - 工具函数
命名规范
- 文件名:小写 + 下划线(
user_wallet.py) - 类名:大驼峰(
UserWallet) - 函数名:小写 + 下划线(
get_current_user) - 路由:RESTful 风格(
/users,/users/{id})
异步编程
- 所有数据库操作用
async/await - 使用
AsyncSession而不是Session - AI 生成使用
async for流式输出
小结
这个后端项目是标准的 FastAPI 三层架构:
- Router 层 - 接收请求,参数校验,调用 Service
- Service 层 - 业务逻辑,调用 Model
- Model 层 - 数据库操作
亮点:
- 完整的依赖注入
- SSE 流式响应
- 异步数据库操作
- 清晰的目录结构
适合作为 FastAPI 项目的参考模板。
XiaZheStudy 前端解读
前端用 Next.js 14 + Tailwind CSS 写的,App Router 架构。看完这篇,你就知道前端代码是怎么组织的。
技术栈
| 组件 | 技术 | 说明 |
|---|---|---|
| 框架 | Next.js 14 | App Router,React 全栈框架 |
| 样式 | Tailwind CSS | 原子化 CSS |
| 组件库 | shadcn/ui | 基于 Radix UI 的组件库 |
| 状态管理 | Zustand | 轻量级状态管理 |
| 数据请求 | React Query | 服务端状态管理 |
| 动画 | Framer Motion | React 动画库 |
| 认证 | Supabase Auth | 用户认证 |
目录结构
frontend/src/
├── app/ # 页面(App Router)
│ ├── (auth)/ # 认证相关页面组
│ │ ├── sign-in/ # 登录页
│ │ └── sign-up/ # 注册页
│ ├── auth/ # OAuth 回调
│ ├── learn/ # 学习相关页面
│ │ ├── course-creation/ # 创建课程
│ │ ├── courses/ # 课程详情
│ │ ├── my-courses/ # 我的课程
│ │ └── my-document/ # 我的文档
│ ├── fun-square/ # 课程广场
│ ├── user-center/ # 用户中心
│ ├── pricing/ # 定价页
│ ├── referral/ # 邀请页
│ ├── notifications/ # 通知页
│ ├── layout.tsx # 根布局
│ ├── page.tsx # 首页
│ └── globals.css # 全局样式
├── components/ # 组件
│ ├── ui/ # shadcn/ui 组件
│ ├── layout/ # 布局组件
│ ├── navbar.tsx # 导航栏
│ └── sidebar.tsx # 侧边栏
├── contexts/ # React Context
│ └── auth-context.tsx # 认证上下文
├── lib/ # 工具库
│ ├── api-client.ts # API 客户端
│ ├── supabase.ts # Supabase 客户端
│ └── utils.ts # 工具函数
├── stores/ # Zustand 状态
└── types/ # TypeScript 类型
核心文件解读
1. API 客户端 - lib/api-client.ts
封装了所有后端 API 调用:
export class APIClient {
private baseURL: string
private token: string | null = null
// 设置认证 token
setToken(token: string | null) {
this.token = token
}
// 通用请求方法
private async request<T>(endpoint: string, options: RequestInit = {}): Promise<T> {
const headers: Record<string, string> = {
'Content-Type': 'application/json',
}
// 自动带上 token
if (this.token) {
headers['Authorization'] = `Bearer ${this.token}`
}
const response = await fetch(`${this.baseURL}${endpoint}`, {
...options,
headers,
})
if (!response.ok) {
const error = await response.json()
throw new Error(error.detail)
}
return response.json()
}
// 具体的 API 方法
async login(email: string, password: string) { ... }
async getCourses() { ... }
async uploadDocument(file: File) { ... }
}
// 导出单例
export const apiClient = new APIClient()
亮点:
- 统一的请求封装
- 自动携带认证 token
- 统一的错误处理
2. SSE 流式请求 - AI 生成
// 处理 SSE 流式响应
private async *processStreamResponse(response: Response) {
const reader = response.body?.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() || ''
for (const line of lines) {
if (!line.startsWith('data: ')) continue
const data = JSON.parse(line.slice(6))
if (data.token) {
yield data.token // 逐个返回 token
}
}
}
}
// 调用 AI 生成
async* generateFromText(text: string, style: string) {
const response = await fetch(`${this.baseURL}/api/v1/ai/generate/text`, {
method: 'POST',
body: JSON.stringify({ text, style }),
})
yield* this.processStreamResponse(response)
}
使用方式:
// 在组件中使用
for await (const token of apiClient.generateFromText(text, style)) {
setContent(prev => prev + token) // 实时更新 UI
}
3. 认证上下文 - contexts/auth-context.tsx
interface AuthContextType {
user: User | null // 后端用户信息
supabaseUser: SupabaseUser | null // Supabase 用户
loading: boolean
signIn: (email: string, password: string) => Promise<void>
signUp: (email: string, password: string, username: string) => Promise<void>
signOut: () => Promise<void>
refreshUser: () => Promise<void>
}
export function AuthProvider({ children }) {
const [user, setUser] = useState<User | null>(null)
const [supabaseUser, setSupabaseUser] = useState<SupabaseUser | null>(null)
useEffect(() => {
// 初始化:检查现有会话
supabase.auth.getSession().then(({ data: { session } }) => {
if (session?.access_token) {
fetchUserProfile(session.access_token)
}
})
// 监听认证状态变化
const { data: { subscription } } = supabase.auth.onAuthStateChange(
async (event, session) => {
if (session?.access_token) {
await fetchUserProfile(session.access_token)
} else {
setUser(null)
}
}
)
return () => subscription.unsubscribe()
}, [])
const signIn = async (email: string, password: string) => {
// 1. 调用后端登录接口
const response = await apiClient.login(email, password)
// 2. 设置 Supabase 会话
await supabase.auth.setSession({
access_token: response.access_token,
refresh_token: response.refresh_token,
})
// 3. 获取用户信息
await fetchUserProfile(response.access_token)
}
return (
<AuthContext.Provider value={{ user, signIn, signOut, ... }}>
{children}
</AuthContext.Provider>
)
}
// 使用 Hook
export function useAuth() {
return useContext(AuthContext)
}
使用方式:
function MyComponent() {
const { user, signIn, signOut } = useAuth()
if (!user) return <LoginButton />
return <div>欢迎, {user.username}</div>
}
页面路由结构
App Router 路由规则
app/
├── page.tsx → /
├── (auth)/
│ ├── sign-in/page.tsx → /sign-in
│ └── sign-up/page.tsx → /sign-up
├── learn/
│ ├── layout.tsx → 学习页面共用布局
│ ├── course-creation/page.tsx → /learn/course-creation
│ ├── courses/[id]/page.tsx → /learn/courses/123
│ ├── my-courses/page.tsx → /learn/my-courses
│ └── my-document/page.tsx → /learn/my-document
├── fun-square/page.tsx → /fun-square
└── user-center/page.tsx → /user-center
路由组 (auth):
- 括号包裹的文件夹不会出现在 URL 中
- 用于组织相关页面,共享布局
动态路由 [id]:
/learn/courses/[id]匹配/learn/courses/123- 在页面中通过
params.id获取
首页解读 - app/page.tsx
export default function HomePage() {
const { user, supabaseUser } = useAuth()
const isLoggedIn = !!user || !!supabaseUser
return (
<div>
{/* Hero Section */}
<header>
<motion.h1 variants={itemVariants}>
让复杂的知识
<span className="bg-gradient-to-r from-purple-600 to-pink-500">
像动画一样生动
</span>
</motion.h1>
{/* CTA 按钮 - 根据登录状态显示不同内容 */}
<Link href={isLoggedIn ? "/learn/course-creation" : "/sign-up"}>
<Button>
{isLoggedIn ? "进入工作台" : "开始创作"}
</Button>
</Link>
</header>
{/* Features Grid */}
<section>
{features.map((feature, idx) => (
<motion.div
key={idx}
initial={{ opacity: 0, y: 20 }}
whileInView={{ opacity: 1, y: 0 }}
>
<Card>{feature.title}</Card>
</motion.div>
))}
</section>
</div>
)
}
关键点:
- 使用 Framer Motion 做滚动动画
- 根据登录状态显示不同的 CTA
- Tailwind 渐变文字效果
组件库使用 - shadcn/ui
已安装的组件
components/ui/
├── button.tsx
├── card.tsx
├── dialog.tsx
├── dropdown-menu.tsx
├── input.tsx
├── label.tsx
├── select.tsx
├── tabs.tsx
├── toast.tsx
└── ...
使用示例
import { Button } from "@/components/ui/button"
import { Card, CardContent, CardHeader, CardTitle } from "@/components/ui/card"
import { Input } from "@/components/ui/input"
function MyForm() {
return (
<Card>
<CardHeader>
<CardTitle>创建课程</CardTitle>
</CardHeader>
<CardContent>
<Input placeholder="输入课程标题" />
<Button>提交</Button>
</CardContent>
</Card>
)
}
环境变量
# .env.local
# 后端 API 地址
NEXT_PUBLIC_API_URL=https://api.xiazhestudy.com
# Supabase
NEXT_PUBLIC_SUPABASE_URL=https://xxx.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJxxx...
注意: NEXT_PUBLIC_ 前缀的变量才能在客户端使用。
数据流总结
用户操作
↓
组件调用 useAuth() 或 apiClient
↓
apiClient 发送请求到后端
↓
后端返回数据
↓
更新组件状态 / Context
↓
UI 重新渲染
SSE 流式数据流
用户点击"生成"
↓
apiClient.generateFromText()
↓
后端 SSE 流式返回 token
↓
前端逐个接收 token
↓
实时更新 UI(打字机效果)
↓
生成完成,保存结果
代码规范总结
目录组织
app/ - 页面和路由
components/ - 可复用组件
contexts/ - React Context
lib/ - 工具库和 API 客户端
stores/ - Zustand 状态管理
types/ - TypeScript 类型定义
命名规范
- 文件名:小写 + 连字符(
api-client.ts) - 组件名:大驼峰(
AuthProvider) - Hook 名:use 开头(
useAuth) - 类型名:大驼峰(
AuthContextType)
样式规范
- 使用 Tailwind CSS 类名
- 避免自定义 CSS(除非必要)
- 响应式用 Tailwind 断点(
sm:,md:,lg:)
小结
这个前端项目是标准的 Next.js 14 架构:
- App Router - 文件即路由,简洁直观
- Context + Zustand - 全局状态管理
- shadcn/ui - 高质量组件库
- Tailwind CSS - 快速样式开发
- SSE 流式 - AI 生成的实时体验
亮点:
- 完整的认证流程(邮箱 + Google OAuth)
- SSE 流式响应处理
- 清晰的 API 客户端封装
- 响应式设计
适合作为 Next.js 项目的参考模板。